StyleT2I:提升文本到图像合成的组合性和保真度
23 浏览量
更新于2025-01-16
收藏 1.65MB PDF 举报
"这篇论文介绍了StyleT2I,一个创新的框架,旨在提升文本到图像合成的组合性和保真度。研究主要针对当前方法在处理未见过或代表性不足的属性组合时的局限性,比如在合成代表性不足的人群群体面部图像时的困难。StyleT2I通过引入CLIP引导的对比损失、语义匹配损失和空间约束等技术,提高了模型的组合属性识别和图像合成能力。此外,它还采用2-范数正则化来平衡图像-文本对齐和图像保真度。在实验部分,作者创建了新的数据集分割和评价指标来评估模型的组合性,并展示了StyleT2I在一致性与保真度方面的优越性能。"
文本到图像合成是一个具有广泛应用前景的技术,包括艺术创作、计算机辅助设计以及训练数据增强等。然而,现有的方法往往存在一个问题,即对于那些在训练数据中不常见或者未曾出现过的属性组合,它们可能无法准确合成,这可能源于模型对过度代表的属性的过拟合,导致生成的图像质量和属性准确性下降。例如,如果输入文本描述的是一个少见的性别属性组合,如"他戴着口红",传统的文本到图像合成方法可能会出错,生成的图像不符合预期。
StyleT2I框架的提出,是为了解决这个问题。它采用了CLIP(Contrastive Language-Image Pre-training)引导的对比损失,使得模型能够更准确地区分不同文本句子中的属性成分。同时,通过设计新的语义匹配损失,可以识别并定位属性的潜在方向,进而进行组合属性调整,优化图像的合成过程。2-范数正则化的应用,旨在防止模型过于依赖某一特定属性,以达到在保持图像-文本对齐的同时,提升合成图像的保真度。
在实验阶段,研究者专门设计了数据集的分割策略,以及新的评价标准,以评估模型在处理组合属性时的能力。实验结果显示,StyleT2I在输入文本和合成图像的一致性上超越了现有的方法,并且在生成高保真图像方面也表现出色。这一突破性的进展不仅提升了文本到图像合成的质量,也为未来的公平性和多样性增强的图像生成研究奠定了基础。
18199
l2
范
数
没
z
+
s
如果推论?
z
s
文章方向
不
是的
z+s
0
i
=1
夹
··
exp(cos(
E
img
(
t
i
)
,
E
te
xt
(
t
j
)
文
本
成分
G
属性调整
在训练数据中记忆所述成分为了实现这一目标,我们
利用在具有匹配图像-标题对的大规模数据集上预训练
的基础模型CLIP [56]来学习文本和图像的联合嵌入空
间,作为条件搜索。我们提出了一种基于CLIP和对比
度损失[4]的新型CLIP
引导的对比度损失
来训练
文本到
方向
模块。从形式上讲,
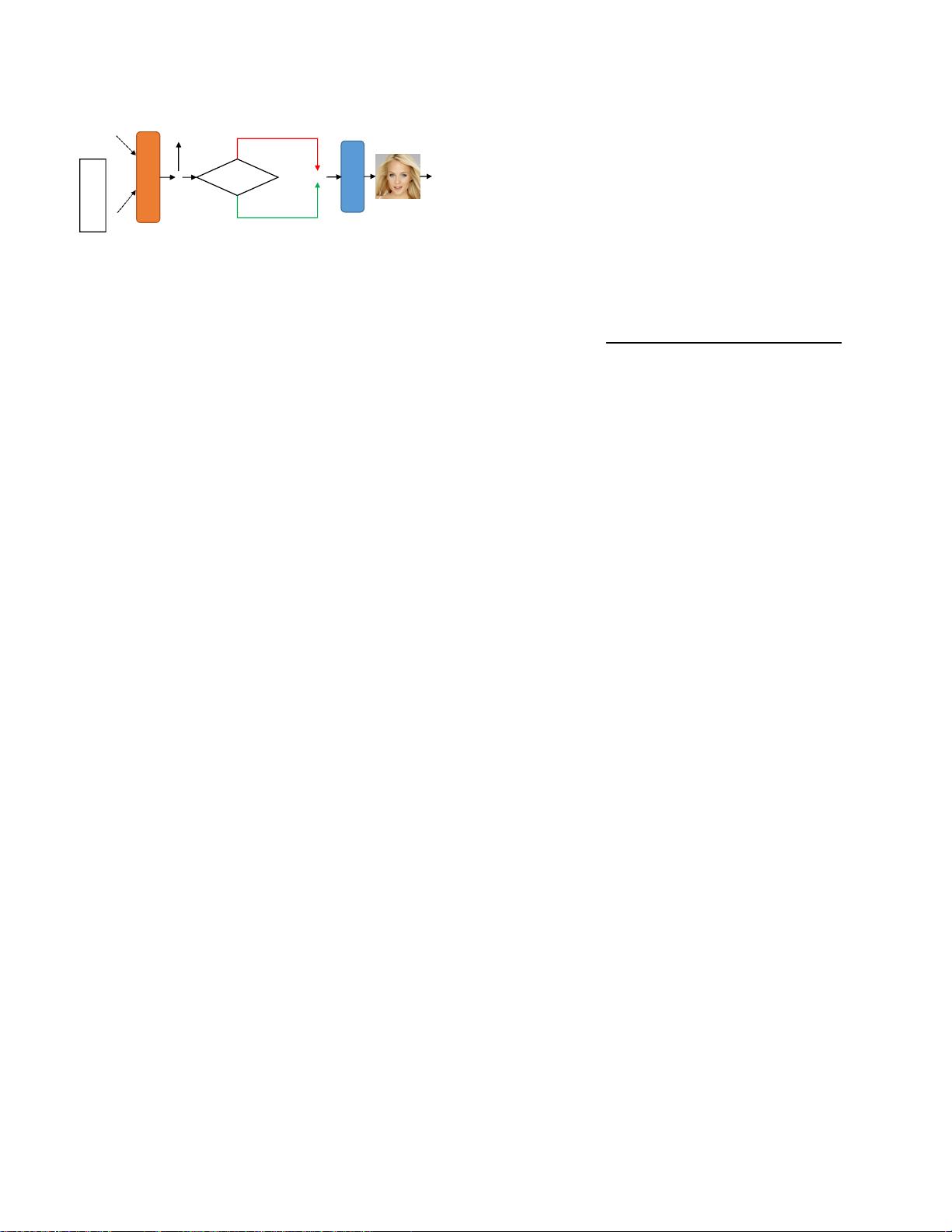
图2.StyleT2I的概述Text-to-Direction模块将文本t和随机潜码z
作为输入,并输出句子方向s以编辑z,从而在StyleGAN的潜
空间中产生用于图像合成的文本条件潜
码z
s
=z+s。
对于从训练
数据采样的
B文本
{
t
i
}
B
和
对应的伪造图像,
我们将
第i
个
伪造图像的
CLIP
引导的
对比度损失
计算
为:
exp
(
cos
(
E
img
(
t
)
,
E
te xt
(
t
)
Text-to-Direction模块使用新的CLIP
引导的
对比损失
(第二节)4.1)与
规范
处罚(第4.2)。
在推理阶段(下分支),
组合属性
L
contras
(
I
i
)
=−log
Ω
J
我
夹
我
夹
夹
i
,
夹
(
一
)
调整
(第5.3)通过将s调整为s
′
来
执行,导致
更好的组合。
其中
E
img
文本
剪辑
表示图像编码器和文本
为了实现这一点,在SEC。4,我们提出了一个
文本
到方向
模块(见图2),用一种新的CLIP
引导的对比损
失训练
,以更好地区分不同的成分(第二节)。4.1)
和一个
标准的惩罚
(第二节)。4.2)以保持合成图像
的高保真度。
为了进一步提高文本到图像合成结果的合成性,在
第5, 我 们 提 出了一 种新
的
Se-mantic
匹配损失
(第5
节)。5.1)和
空间约束
(第二节)。5.2)用于识别解
纠缠属性潜在方向,这将用于在推理阶段调整文本条
件潜在代码(第5.2节)5.3)与我们的新
的成分属性调
整
(CAA)。完整算法的伪代码见附录A.1。
4.
文本条件潜在代码预测
由于许 多 先前的工 作 [42,53, 54 , 69,77]表明
StyleGAN的潜在空间中的潜在方向“因此,为了在预训
练的StyleGAN的潜在空间中找到文本条件潜在代码输
出是一个潜在方向s,称为句子方向,以编辑潜在代码
z
,从而产生文本条件代码
z
s
=
z
+
s
。因此,
z
s
被输入
StyleGAN
生成器
G
来合成图像
I
=
G
(
z
s
)
。
4.1.
CLIP引导的对比损失
文本到方向
模块应该预测与输入文本对齐的句子方
向,并避免简单地
CLIP
的编码器。cos(
,
)表示余弦
相似性。CLIP
引导的对比损失
吸引配对文本
在CLIP的联合 特征空间中进行图像嵌入和伪图像嵌
入,并排斥不匹配对的嵌入。以这种方式,
文本到方
向
模块被训练为更 好地将句子方向s 与输入文 本t 对
齐。同时,CLIP
引导的对比损失
迫使
文本方向
模块对
比不同文本中的不同成分,
例如
,
4.2.
高保真度综合
实验结果(图)7)表明单独最小化对比度损失不能
保证合成图像的保真度。我们观察到,它使
文本到方
向
模块预测的s与一个大的
number2
范数,导致z
s
移动到
低密度区域的潜在分布,导致图像质量下降。因此,
当句子方向s的范数超过阈值超参数θ时,我们惩罚
它:
10
- 12 - 2016
刘晓波
(
||
S
||
2
−
θ
,
0
)
。
(
二)
我们的消融研究(图7)表明,添加
范数惩罚
在文本图
像对齐和质量之间取得了很好的平衡。
总而言之,用于训练Text-to-Direction模块的完整目
标函数是:
L
s
=
L
contra
+
L
norm
。
(
三)
5.
具有属性方向
为了进一步提高组合性,我们首先确定潜在的方向
表示的属性与一个新
的语义匹配损失
(第二。5.1)和
空间约束
(第二节)。5.2)。然后,我们提出
了成分
属性调整
(第二节)。5.3)通过所识别的属性方向来
调整句子方向,以改善文本到图像 合成结果的合成
性。
合成
图像
I
=
G
(
z
s
)
那个女人有
一
头金发。
随机潜码
文本到方向
文本
条件
码
StyleGAN
反
L
和
E
B
剩余11页未读,继续阅读

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Saber仿真下的简化Buck环路分析与TDsa扫频
- Spring框架下使用FreeMarker发邮件实例解析
- Cocos2d捕鱼达人路线编辑器开发指南
- 深入解析CSS Flex布局与特性的应用
- 小学生加减法题库自动生成软件介绍
- JS颜色选择器示例:跨浏览器兼容性
- ios-fingerprinter:自动化匹配iOS配置文件与.p12证书
- 掌握移动Web前端高效开发技术要点
- 解决VS中OpenGL程序缺失GL/glut.h文件问题
- 快速掌握POI技术,轻松编辑Excel文件
- 实用ASCII码转换工具:轻松实现数制转换与查询
- Oracle ODBC补丁解决数据源配置问题
- C#集成连接器的开发与应用
- 电子书制作教程:你的文档整理助手
- OpenStack计费监控:使用collectd插件收集统计信息
- 深入理解SQL Server 2008 Reporting Services
