时空一致性视频框模板生成:解决视频对象分割的数据效率问题
PDF格式 | 1.05MB |
更新于2025-01-16
| 129 浏览量 | 举报
视频框模板生成:基于时空一致性的视频对象分割方法是一种先进的计算机视觉技术,它旨在解决视频对象分割中数据标注稀少的问题。传统的深度学习方法依赖于大规模的像素级分割标签,这在实际应用中极其耗时且昂贵。针对这一限制,该研究提出了一种创新的解决方案,即通过利用视频中的边界框注释来生成精确的分割掩模。
研究人员ZhaoBin等人来自苏黎世ETH计算机视觉实验室,他们开发了一种时空聚合模块,该模块能够在多帧之间捕捉和整合对象和背景的动态变化,从而增强对物体的识别和分割准确性。与仅依赖单帧的边界框预测相比,这种方法能够更好地处理复杂场景中对象的运动和遮挡问题,如图1所示,通过视频序列可以更准确地区分汽车和滑板车。
关键点包括:
1. 时空一致性:方法的核心在于跨帧的时空信息融合,确保对象在整个视频序列中的一致性,即使在不同帧间对象位置或姿态发生变化时也能保持正确分割。
2. 边界框注释:研究者利用对象绑定框作为训练数据,这些框提供了对目标区域的约束,相较于像素级注解,其标注成本低且速度快,对于大规模视频应用具有显著优势。
3. 视频对象分割网络(VOS):通过将准确的生成掩模应用于VOS网络的跟踪域,即使在仅使用手动框注释的情况下,也能训练出性能强大的模型。这种方法允许现有VOS技术跨越标注壁垒,提升其泛化能力和在新场景下的表现。
4. 实际应用:这项工作对自动驾驶、监控和视频编辑等领域的应用具有重要价值,有助于简化模型部署过程,使得现有方法能够利用较少的标注资源实现更高效的视频对象分割。
成果方面,研究团队提供的代码和模型已在国家最先进的跟踪基准上展示了优越的表现,证明了该方法的有效性和实用性。通过结合弱监督的边界框注释和时空一致性,视频框模板生成算法为解决视频对象分割的标注问题开辟了一条新的道路。
13558
1
-
-
-
-
图
2.
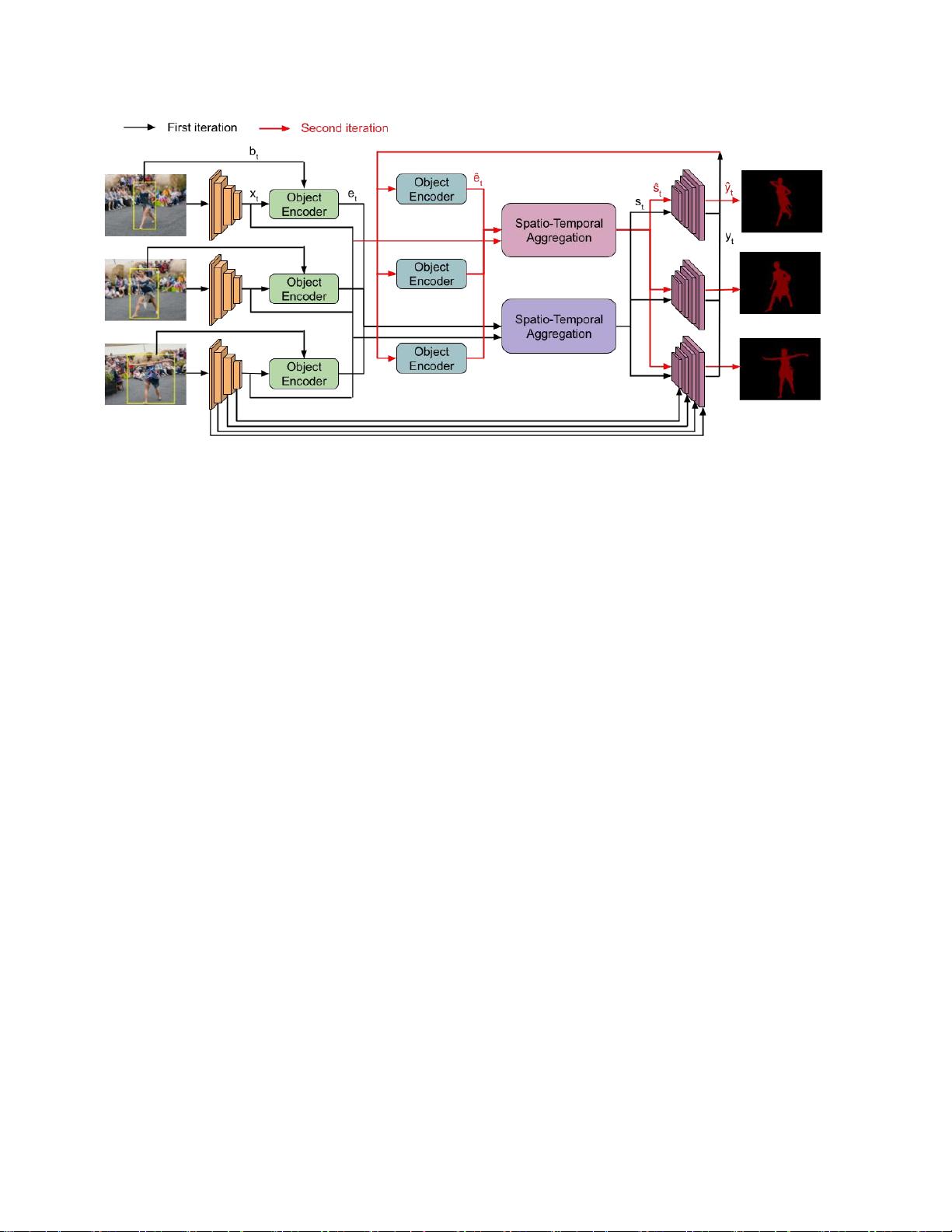
概述了我们的架构,用于从框注释的视频分割对象我们从每帧中提取深度特征
然后,将特征x
t
和框b
t
给予对象编码器(Sec.
3.1
)以生成对象感知表示
et
。时空聚合模块(
Sec.3.2
)输入来自所有帧的对象编码和深度特征 其输出
s_
t
被解码为对象掩码
y_
t
。 我们
通过迭代该过程
来细化掩码
(
Sec. 3.3
)与次级对象编码器和聚集模块一起生成
最终
输出
y
(
t
)
。
来自给定对象边界框的分割掩模是实例分割中的基本
子任务,尤其是基于检测的方法[13,18,19,36]。
这些方法遵循多任务学习策略,其中骨干网络首先提
取深度特征并生成一组提议。然后分别使用检测和分
割 头 来 预 测 该 建 议 的 准 确 边 界 框 和 分 割 掩 码 。
ShapeMask [32]采用边界框检测作为初始形状估计,并
使用形状先验集合逐渐对其进行细化。Luiten等人[38]
训练修改后的DeepLabv3 [9]模型输出掩码,给定包含
对象的裁剪作为输入。与以前的方法相比,只对单个
图像进行操作,我们解决了给定框注释视频作为输入
生成掩码的任务。我们的方法可以利用视频中的额外
的时间信息来预测更准确的掩模,相比单一图像的方
法。
对象共分割:对象共分割是从一组图像中分割出共同
对象的任务。 这个概念首先由Rother
等人
提出。 在
[53]中,其最小化包含MRF平滑先验和直方图匹配项
的能量 函 数 。后续工 作 [54]结 合 视 觉显著性和密 集
SIFT匹配来捕获一组图像中常见对象的稀疏性工作
[34]将互相关层集成到基于CNN的Siamese架构中以执
行共同分割。与联合分割方法类似,我们使用多幅图
像分割对象然而,我们的图像是从同一个视频中获得
的。这使得能够利用视频中的强时间一致性来提高分
割精度。
3.
方法
我们提出了一个端到端的可训练架构的问题,
分
割视频中的对象,在每一帧中的
边界框。 我们的
完整架构
如图所示。二、 为了充分利用时间维
度
,我们的目标是不仅使用目标的详细信息,而且还
使用背景上下文。因此,我们的骨干特征网络
F
首先
分别编码
包含对象以及实质背景的视频帧
I t T
。所
提取的深度特征x
t
=
F(I
t
)连同对应的边界框b
t
被给予
对象编码器
B
,对象编码器
B
提供每个单独帧
的对象感知
表示
。 通过结合
对象包围盒,它提供了关
于
假想对象和背景区域的信息。
来自所有帧的对象编码和深度特征
Xt
被输入到时空
聚合模块S。该模块的目标是为每个帧生成对象分割
的编码。模块S通过有效且可区分的优化过程来聚合
来自所有帧和位置的迭代过程通过找到对象的底层表
示来融合外观(x
t
,
e
t
)的不同观察。然后,该表示生
成分割编码
st
,其由分割解码器D处理以预测初始对象
掩模为y
t
=D(
st
,
x
t
)。我们灵活的体系结构允许我们
通过将结果馈送到第二个时空聚合模块来进一步改进
掩码,该模块预测一组细化的分割编码
剩余10页未读,继续阅读
相关推荐





cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现ART与SART算法在医学CT重建中的应用
- S2SH整合版:快速搭建Struts2+Spring+Hibernate开发环境
- 托奇卡项目团队成员介绍
- 提升外链发布效率的SEO推广神器——搜易达网络推广大师v2.035
- C#打造简易记事本应用详细教程
- 探索虚拟现实地图VR的奥秘
- iOS模拟器屏幕截图新工具
- 深入解析JavaScript在生活应用开发中的运用
- STM32F10x函数库3.5中文版详解与应用
- 猎豹浏览器v6.0.114.13396 r1:安全防护与网购敢赔
- 掌握JS for循环输出的最简洁代码技巧
- Java入门教程:TranslationFileGenerator快速指南
- OpenDDS3.9源码解析及最新文档指南
- JavaScript提示框插件:鼠标滑过显示文章摘要
- MaskRCNN气球数据集:优质图像识别资源
- Laravel日志查看器:实现Apache多站点日志统一管理
