360°图像中的几何结构深度估计框架与室内场景理解
PDF格式 | 1.45MB |
更新于2025-01-16
| 194 浏览量 | 举报
"基于几何结构的室内深度估计框架在360°图像中的应用"
本文主要探讨了如何利用几何结构信息来改进360°室内图像的深度估计。深度估计是计算机视觉领域的一个核心问题,它对于地图检索、导航以及3D场景理解等应用至关重要。随着便携式全景相机的普及,从360°图像中获取深度信息的需求日益增加。
作者提出了一种创新的深度估计框架,该框架特别关注室内场景的几何结构,包括角落、边缘和平面。这个框架有两个关键方面:首先,深度图的估计可以用来推断场景的几何结构,从而将几何结构作为深度估计的正则化器;其次,利用从图像中估计出的几何结构作为先验信息,进一步优化深度估计。然而,室内场景中家具的存在给从深度或图像数据中推断几何结构带来了挑战。为了解决这个问题,文章引入了注意力机制,通过生成的注意力图来辅助从几何特征进行深度估计,并反过来从深度图中推断几何结构。
为了验证框架中各个组件的有效性,研究人员创建了一个名为Shanghaitech-KujialeIndoor360Mixed的数据集,包含了3550个360°全景室内图像。通过对流行数据集的大量实验,证明了该方法的有效性。此外,他们还展示了这种方法同样适用于反事实深度估计,这是一种评估深度估计假设变化能力的技术。
1. 引言部分强调了深度估计在360°全景图像中的重要性,尤其是全向图像提供的全局结构信息的优势。现有的工作虽然已经在360°图像的深度估计上取得了一些进展,但对大视场特性的充分利用尚不充分。
2. 方法部分详细介绍了利用几何结构进行深度估计的思路,包括如何从深度图中推断几何结构,以及如何用几何结构信息来提升深度估计的准确性。
3. 数据集与实验部分介绍了新创建的数据集,以及通过实验验证方法性能的过程,这表明了提出的框架在实际应用中的潜力。
4. 结果与分析部分展示了实验结果,证明了方法的有效性,并讨论了可能的改进方向。
这项工作为360°室内图像的深度估计提供了一个新的视角,强调了利用几何结构的重要性,并为此设计了一个综合的深度估计框架。这种方法不仅提高了深度估计的精度,也为未来在复杂室内环境中的机器人导航和3D重建等应用奠定了基础。
891
DE
P
∈
(a)
深度估计模块
:
Concate
:点积
(b)
关注模块
(c)
结构作为优先模块
(d)
结构作为正则化模块
图
2.
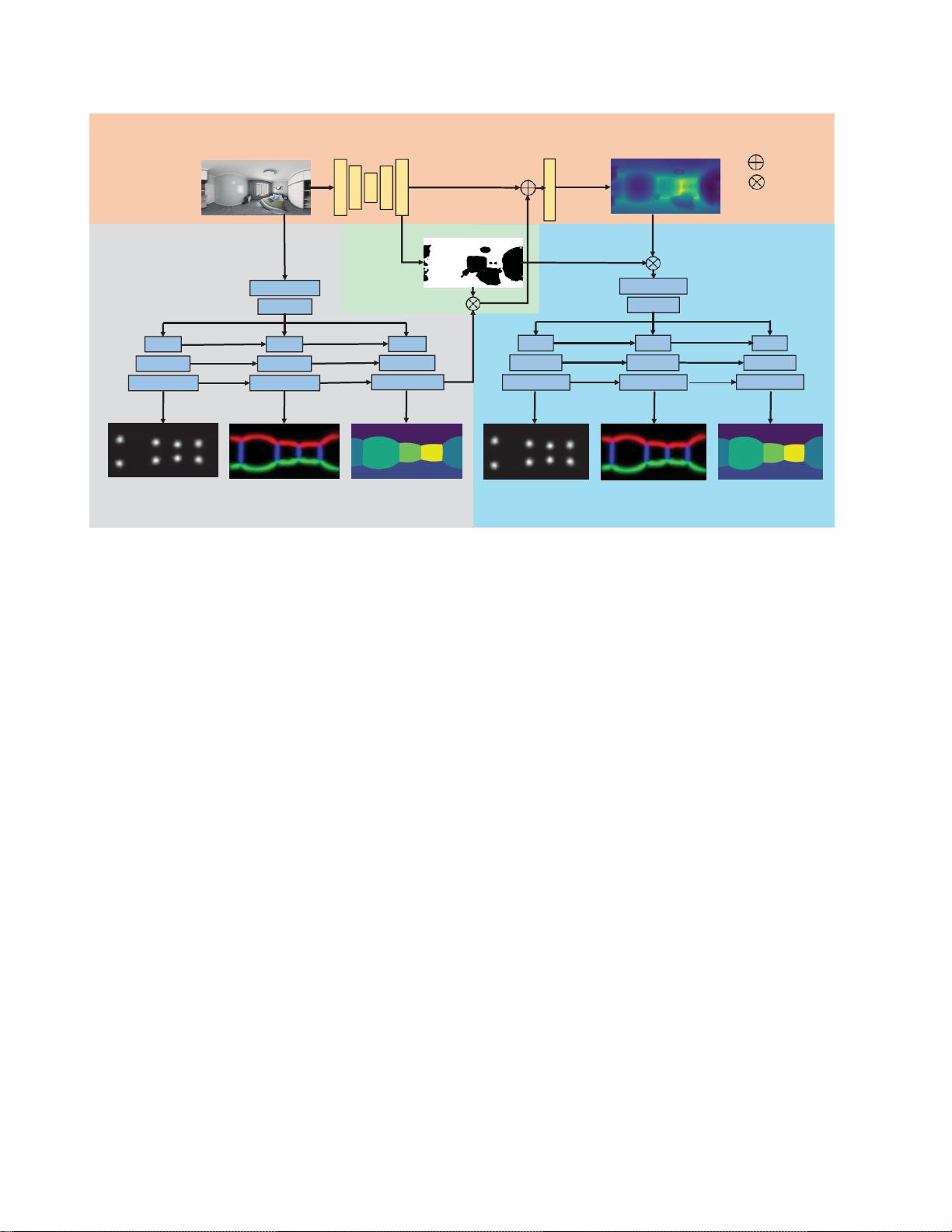
我们的架构概览。(a)深度估计从给定全景图像预测深度。(c)结构作为先验,将全景作为输入,并估计房间的
结构。(b)注意力模块旨在生成注意力图,以避免由家具引起的结构和深度图之间(d)作为正则化器的结构被设计为
通过从估计的深度图预测结构来正则化估计的深度图为了简单起见,我们忽略了
U-Net
中的跳跃连接具有不同颜色的不同
矩形表示卷积块。
最近,全景图像中的深度估计已经变得流行。在[31]
中,Keisuke
等人
提出用失真感知卷积代替卷积。在[24]
中,Garanderie
等人
提出通过户外自动驾驶场景中的风
格和投影传输网络将现有的透视数据集利用到全向
域。在[39]中提出了用于室内深度估计的大规模数据
集,由来自四个现有数据集的22,096个重新渲染的图
像本文还提出了两种编码器-解码器网络:具有步幅卷
积的UResNet和具有扩张卷积的WARNET。与上述方
法不同的是,我们使用360
像素
图像中的几何结构信息来
辅助和正则化深度估计。
3.
方法
我们表示一个球形的室内图像作为一个集合的几何
结构,包括角,线和平面。由于缺乏注释,这里我们
只采用了房间中几何结构的大部分,房间布局。
3.1.
整体架构
图图2示出了总体深度估计网络架构。给定一个室
内
360
mm
图像
I R
H
×
W
×
3
,我们的网络通过利用几何结构
作为先验和正则化器来估计其深度图M
gt
我们的整个网
络包含两个阶段:基于几何结构的深度估计模块和几
何正则化深度估计模块。此外,为了使网络对深度图
和几何结构之间的由深度引起的不一致性具有鲁棒
性,引入了注意力模块以帮助从几何结构进行深度估
计和从深度数据推断几何结构。我们将在下面的章节
中介绍这些模块。
3.2.
基于几何结构的深度估计
如图1、对于一个没有家具的空房间,深度与场景
的几何结构有很强的相关性:角部位于局部最大深度
处,并且在同一直线或同一平面内的深度分布呈现规
则图案。因此,一旦场景的几何结构被给出,它就可
以被用作深度预测中的先验。因此,我们建议在进行
深度估计时利用房间的几何结构
剩余10页未读,继续阅读
相关推荐





cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- WebDrive v16.00.4368: 简易易用的Windows风格FTP工具
- FirexKit:Python的FireX库组件
- Labview登录界面设计与主界面跳转实现指南
- ASP.NET JS引用管理器:解决重复问题
- HTML5 canvas绘图技术源代码下载
- 昆仑通态嵌入版ASD操舵仪软件应用解析
- JavaScript实现最小公倍数和最大公约数算法
- C++中实现XML操作类的方法与应用
- 设计编程工具集:材料重量快速计算指南
- Fancybox:Jquery图片轮播幻灯弹窗插件推荐
- Splunk Fitbit:全方位分析您的活动与睡眠数据
- Emoji表情编码资源及数据库查询实现
- JavaScript实现图片编辑:截取、旋转、缩放功能详解
- QNMS系统架构与应用实践
- 微软高薪面试题解析:通向世界500强的挑战
- 绿色全屏大气园林设计企业整站源码与多技术项目资源
