大型数据库中的CAD零件搜索技术
187 浏览量
更新于2025-01-16
收藏 597KB PDF 举报
"本文主要探讨了在大型数据库中设计和应用CAD零件搜索引擎的方法。文章提到了三种不同的搜索引擎,分别用于发现标准零件、执行个性化查询和比较参照零件。搜索引擎基于CAD模型的结构树数据生成XML文件,包含部件的物理属性,以支持搜索。研究中使用的工具包括CATIA V5和Python编程语言。此外,文章还包含了对各个程序的优缺点比较和性能测试结果,强调了在现代工程设计中,处理大量CAD数据的挑战和应对策略。"
在大型数据库环境中,CAD零件搜索引擎是解决数据管理和检索问题的关键。第一种搜索引擎专注于查找标准化组件,如螺钉和垫圈,这有助于快速定位常用零部件。第二种搜索引擎允许用户输入特定参数,进行定制化的搜索,适应不同工程需求。而第三种方法则通过对比参照零件与数据库中的所有零件,找出匹配或相似的部件,这对于设计迭代和部件重用尤其有用。
文章指出,这些搜索引擎的实现依赖于CATIA V5的结构树分析功能,这是一种强大的CAD软件,广泛应用于工程设计。Python编程语言被用来编写搜索引擎,这表明Python的灵活性和易用性使其成为处理复杂数据任务的理想选择。
随着计算机辅助设计和工程的普及,数据量急剧增加,带来了管理和搜索效率的问题。产品生命周期管理(PLM)系统中的大量数据,如虚拟模型、技术图纸、有限元分析(FEM)计算文件和多媒体资料,都需要高效检索工具。大型企业,如汽车制造商,会建立大型数据库来存储这些信息,有效的搜索引擎对于提高工作效率和降低成本至关重要。
作者对三种搜索引擎进行了性能评估,这不仅提供了实际应用的依据,也为未来优化和开发新的搜索算法提供了参考。文章最后的比较和测试结果部分,揭示了各种方法在实际操作中的表现和适用场景,对于读者理解和应用这些技术具有指导意义。
这篇论文深入探讨了CAD零件搜索引擎在大型数据库环境中的设计原理和应用实践,为工程领域的数据管理和知识发现提供了有价值的见解和解决方案。
R.
计算设计与工程学报。号
12014
年第
3
期第
161~172
页
163
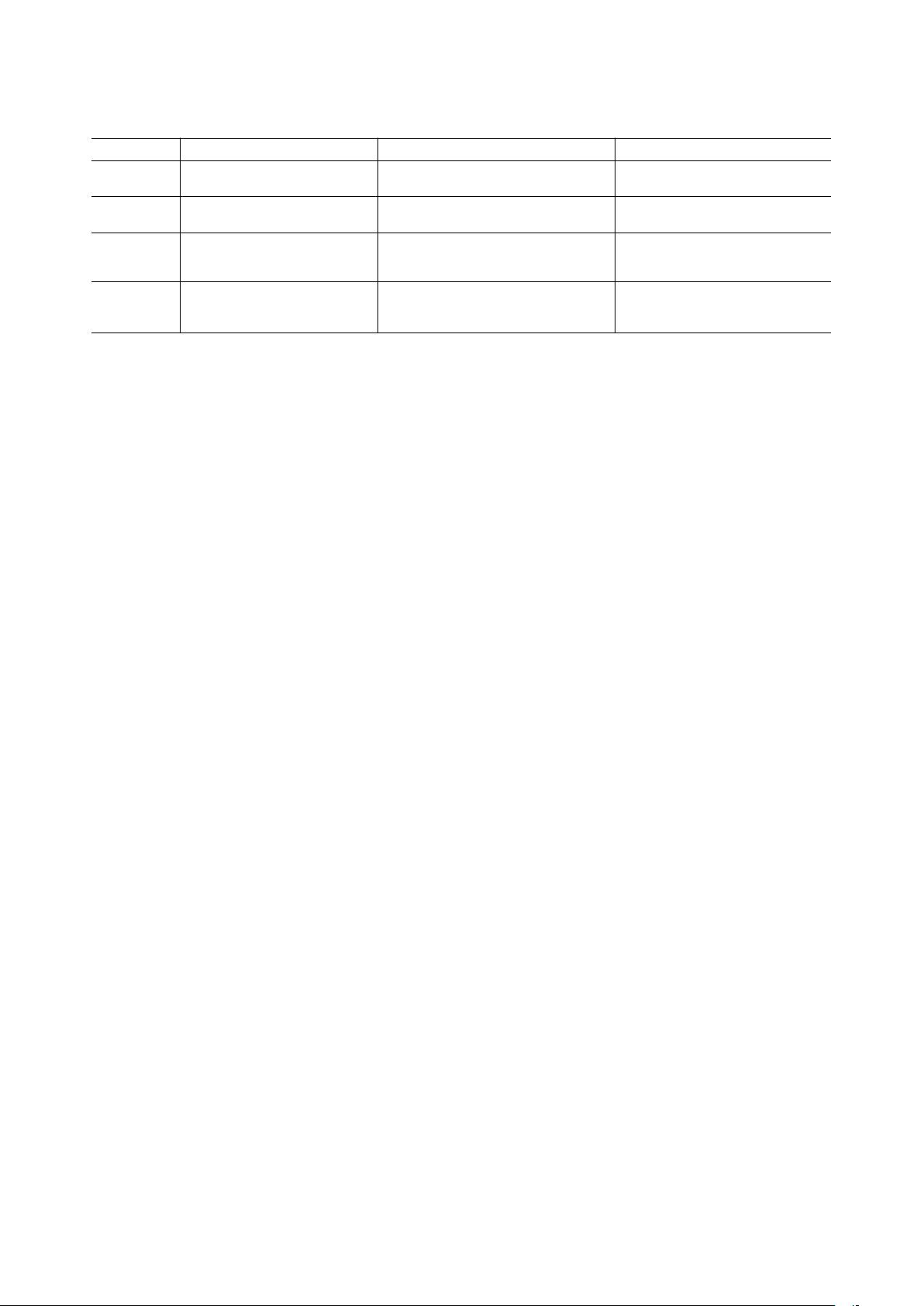
表1.所有方案的概述。
程序
描述
输入
输出
tree.py
将CATIA的结构树外包为
XML文件
带有CATPart文件的
带有XML文件的
norm.py
给定数据库
带有XML文件和CATPart文件
的数据库,标准零件
与所选规范零件相似的已定位文件的
名称
category.py
为给定数据库中符合
参数
带有XML文件和CATPart文
件的数据库,搜索参数
符合给定参数
match.py
查找给定数据库中
与引用
带有XML文件和CATPart文件的
数据库,引用XML文件和
CATPart文件输入部分
三个类别中的文件名称(完美,非常
好,好)
基于近似,当前部件与数据库中的所有相关文件进行
比较,以识别相似性,并将新对象集成到该库中。
当然,所有这些技术都应该降低成本,并提高设计
和制造过程的效率Ip和Regli [20]特别关注制造特征的
识别通过这种特征的自动识别以及生产步骤的分离,
可以在没有任何人工辅助的情况下生成机器应用的
Horváth和Rudas [21]描述了这种跨学科合作的必要性。
一旦分别提取特征和任何其他信息,就可以在数据
库中进行系统和自动搜索以下出版物涉及搜索引擎,
它使用用户的输入作为搜索参数,在数据库中查找某
些模型。Min等人的策略。
[22]可以分为三个步骤:(1)获取:必须从网络收集
3D模型,(2)分析:必须分析它们以用于以后的匹
配,以及(3)查询处理和匹配:在线系统必须将用户
查询与所收集的3D模型相匹配。
Wei和Yuanjun [23]提出了与搜索引擎相关的数据挖掘
技术的另一种方法。为了在大型数据库中检索零件,他
们使用基于体素的技术;而Ansary、Daoudi和Vandeborre
专注于二维视图,以实现他们称为自适应视图聚类的方
法[24]。通过该程序,他们能够从数据库中检索三维模
型在这一点上,应该参考普林斯顿形状检索和分析组
[25],其中有几个示例,例如,Min的论文[26]和
Funkhouser等人的期刊论文。[27],处理三个话题-
数据库中的形状的尺寸检测的细节。
处理从数据库中收集的信息或单个零件的特征参数的
另一种策略是分类。特别是对于工程零件,将CAD模
型按顺序分为不同类型是可行的。如果考虑汽车制造商
的数据库,可以想象将所有组件分离到各个汽车单元是
公司中不同部门的常见做法,以及来自不同供应商的订
单。对于这个任务,一个叫做K-
手段是一种常用的工具。Michalik、Štofa和Zolotová在
数据挖掘应用中测试了K-means算法的特性[28]。
Wang和Chang [29]给出了通过表面特征识别对对称
旋转零件进行分类的一个简洁的例子他们提出了一种
方法,使任何人力援助多余。
所有上述要求是必要的用户友好的软件操作性是实现
以下三个程序,这是专为工业应用。首先介绍了西门子
的Geolus搜索程序[30]。基本上,它可以被认为是一个
三维搜索引擎的镶嵌CAD模型。用户预先确定一个参
考零件,并提供数据库,应检查.进一步的选项可以通
过细化搜索相同、非常相似或相似的部分来选择图形用
户界面显示存储在存储器中的所有匹配文件,并允许选
择定位的模型以进行可能的更新或继续构建。其目的是
分别减少和消除存储器中已经可用的冗余模型因此,可
以减少创建新组件的时间,从而减少劳动力成本。
第二个处理零件自动分类的程序被Lino称为simus
classmate [31]。它专门用于CAD模型的自动分析和排
序,以获得感兴趣的信息,例如最大尺寸,钻孔数
量,材料或每个元素的不同螺纹参数利用这些提取的
信息,只需点击几下鼠标,就可以将其分类为车削零
件或钣金零件另一个优点是该程序完全集成到不同出
版商的既定CAD程序最后一个相当大的程序被分成几
个包,由CADENAS公司编程[32]。软件称为
PARTSolutions是专为管理和影响已经在创建阶段的建
筑部件,以限制所有的行动,只有必要的步骤。另一
个软件包称为PURESEESTAL,用于处理购买所需结构
时产生的
零件.
总之,可以说,许多不同的方法
剩余11页未读,继续阅读
2021-05-08 上传
2021-08-04 上传
2022-06-01 上传
131 浏览量
191 浏览量
105 浏览量
348 浏览量
2023-06-06 上传
147 浏览量

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Ruby语言集成Mandrill API的gem开发
- 开源嵌入式qt软键盘SYSZUXpinyin可移植源代码
- Kinect2.0实现高清面部特征精确对齐技术
- React与GitHub Jobs API整合的就业搜索应用
- MATLAB傅里叶变换函数应用实例分析
- 探索鼠标悬停特效的实现与应用
- 工行捷德U盾64位驱动程序安装指南
- Apache与Tomcat整合集群配置教程
- 成为JavaScript英雄:掌握be-the-hero-master技巧
- 深入实践Java编程珠玑:第13章源代码解析
- Proficy Maintenance Gateway软件:实时维护策略助力业务变革
- HTML5图片上传与编辑控件的实现
- RTDS环境下电网STATCOM模型的应用与分析
- 掌握Matlab下偏微分方程的有限元方法解析
- Aop原理与示例程序解读
- projete大语言项目登陆页面设计与实现
