时空插值一致性训练:提升视频阴影检测的准确性
173 浏览量
更新于2025-01-16
收藏 2.32MB PDF 举报
"本文介绍了一种在视频阴影检测中基于时空插值一致性训练(STICT)的方法,旨在解决大规模数据集注释难题和视频帧间的时间不一致性问题。通过结合未标记的视频帧与标记的图像进行训练,该方法提升了模型的泛化能力和时间一致性。文中提出的空间和时间ICT策略包含空间内插和时间内插,以及相应的约束条件,以优化像素分类任务并确保预测的一致性。此外,还设计了尺度感知网络以学习图像中的多尺度阴影知识,并引入尺度一致性约束减少不同尺度预测结果的差异。实验结果证明,即使没有视频标签,该方法在ViSha数据集和自注释数据集上也优于大多数现有的监督、半监督或无监督的图像/视频阴影检测方法。"
在计算机视觉领域,阴影检测是关键任务之一,广泛应用于各种场景,如目标识别、场景理解等。传统的阴影检测方法主要依赖于静态图像,但在视频处理中,由于连续帧之间的变化,直接应用静态图像的检测模型可能导致泛化误差和时间不一致。为了解决这些问题,本文提出的STICT框架创新性地引入时空插值一致性训练。
首先,STICT通过空间ICT在空间维度上扩展了训练数据,通过定义空间内插策略,将未标记的视频帧与标记图像相结合,增加了模型的训练样本,有助于模型学习更多的场景信息。其次,时间ICT则关注时间维度,利用时间内插来保持连续帧间的预测一致性,减少时间上的漂移现象。
为了处理不同尺度的阴影,文章还介绍了尺度感知网络(SANet),这是一种能够捕捉图像中不同尺度阴影特征的网络结构。通过尺度一致性约束,该网络能够在不同尺度上提供更稳定和一致的阴影检测结果。
实验部分,作者在ViSha数据集和自构建的标注数据集上验证了STICT的有效性,对比了其他先进方法,显示了其在无视频标签情况下的优越性能。这为未来无监督或弱监督的视频阴影检测提供了新的思路和解决方案。
这项工作为视频阴影检测提供了一个创新的训练策略,通过时空插值和尺度感知,提高了模型的泛化能力和时间一致性,对于推动计算机视觉领域的阴影检测研究具有重要意义。
3116
连续帧
基于时空插值一致性训练的视频阴影检测
Xiao Lu
1
,
Yihong Cao
1
,
Sheng Liu
1
,
Chengjiang
Long
2
,
Zipei Chen
3
,
Xuanyu Zhou
1
,
Yimin Yang
4
,
5
,
Chunxia Xiao
3
*
1
湖南师范大学工程设计学院,长沙,中国
2
Meta Reality Labs,Burlingame,CA,美国
3
武汉大学计算机科学学院湖北武汉4加拿大湖首大学计算机科学
系
5
加拿大
Vector Institute for Artificial Intelligence
{卢晓,曹义红,刘生,周喜义}@ hunnu.edu.cn,clong1@fb.com,
{czpp19,cxxxiao} @ whu.edu.cn,yyang48@lakeheadu.ca
摘要
带标签
SANet
(a)
SANet结果
对于监督视频阴影检测方法来说,对大规模数据集
进行注释是一个挑战。将基于标记图像训练的模型直
接应用于视频帧可能会导致较高的泛化误差和时间不
一致的结果。 在本文中,我们通过提出时空插值一致
性训练(
STICT
)框架来解决这些挑战,以合理地将未
标记的视频帧与标记的图像一起馈送到图像阴影检测
网络训练中。具体来说,我们提出了空间和时间
ICT
,
其中我们定义了两个新的插值方案,即,空间内插和
时间内插。然后,我们推导出相应的空间和时间插值
一致性约束,以提高泛化的像素分类任务和鼓励时间
一致的预测,分别。此外,我们还设计了一个用于图
像中多尺度阴影知识学习的尺度感知网络,并提出了
一个尺度一致性约束,以最小化不同尺度下预测结果
的差异。我们提出的方法在
ViSha
数据集和自注释数据
集上进行了广泛的验证。实验结果表明,即使没有视
频标签,我们的方法是优于大多数国家的最先进的监
督,半监督或无监督的图像
/
视频阴影检测方法和其他
方 法 在 相 关 的 任 务 。 代 码 和 数 据 集 可 在
https://github.com/yihong-97/STICT
上 获
得。
*
通讯作者。
(b)
STICT结果
利用科技创新和信通
技术促进知识
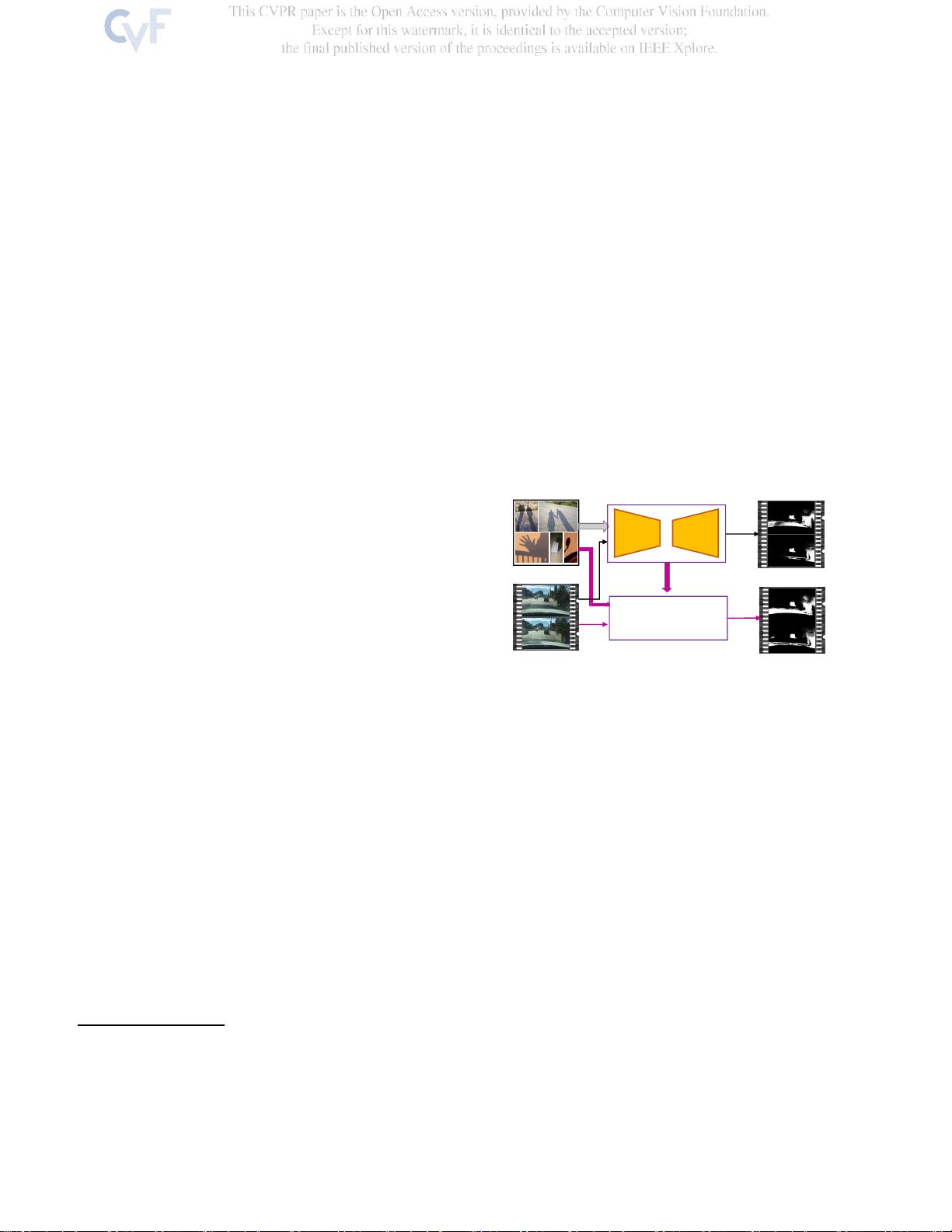
图1.由我们的图像阴影检测网络SANet生成的阴影图(a)在
标记的图像上训练,(b)在标记的图像和未标记的视频上
训练。
1.
介绍
阴影检测是许多计算机视觉和图形任务的重要问题,
并且在广泛的 视觉应用中引 起了兴趣[4, 20,40,
41],例如对象识别[13,23-最近,由于深度卷积神经
网络(CNN)的发展,阴影检测在图像基准数据集
[33,35,44]上取得了显著进展[6,7,12,19,35,
43,45],而缺乏大规模注释数据集是基于深度学习的
方法在视频阴影检测(VSD)中应用的主要原因
如何将未标记的视频样本合理地输入到网络训练
中,并有效地将知识从标记的图像转移到视频中,对
于提升基于深度学习的方法在无监督数据上的能力至
关重要然而,现有的半监督方法很少和具有挑战性的
转移阴影模式在im-vector中。
编码解码
下载后可阅读完整内容,剩余9页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入解析JavaWeb中Servlet、Jsp与JDBC技术
- 粒子滤波在视频目标跟踪中的应用与MATLAB实现
- ISTQB ISEB基础级认证考试BH0-010题库解析
- 深入探讨HTML技术在hundeakademie中的应用
- Delphi实现EXE/DLL文件PE头修改技术
- 光线追踪:探索反射与折射模型的奥秘
- 构建http接口以返回json格式,使用SpringMVC+MyBatis+Oracle
- 文件驱动程序示例:实现缓存区读写操作
- JavaScript顶盒技术开发与应用
- 掌握PLSQL: 从语法到数据库对象的全面解析
- MP4v2在iOS平台上的应用与编译指南
- 探索Chrome与Google Cardboard的WebGL基础VR实验
- Windows平台下的IOMeter性能测试工具使用指南
- 激光切割板材表面质量研究综述
- 西门子200编程电缆PPI驱动程序下载及使用指南
- Pablo的编程笔记与机器学习项目探索
