自激励通信代理推动现实世界视觉对话导航
36 浏览量
更新于2025-01-16
收藏 1.06MB PDF 举报
本文主要探讨了现实世界视觉对话导航(Visual Dialogue Navigation, VDN)中的新型自激励通信代理(Self-Incentivized Communication Agent, SCoA)。传统的VND方法依赖于预定义位置的对话,这在实际应用中存在局限性,因为它们依赖于昂贵的对话注释,且限制了人与机器人的自然交流和协作。为了解决这个问题,研究者提出了SCoA,这是一种能够自主决定何时以及如何与人类进行沟通,从而获取引导信息的系统。
SCoA的核心创新包括两个关键组件:一是“是否要问”(WeTA)策略,它允许代理判断在特定情境下是否需要提问,这有助于节省不必要的交互;二是“问什么”(WaTA)策略,通过学习预测答案,代理能够挑选出最有利于导航的问题,同时模仿人类的回答,增强了在未知或难以察觉环境中的导航能力。这种方法不再受限于预先设定的对话场景,而是能够灵活地适应现实世界的交互。
论文通过在一个统一的模仿学习和强化学习框架中协同优化通信和导航,展示了SCoA在可见和不可见环境中的实际效果。实验结果显示,相比于没有对话注释的现有基准,SCoA表现更优,即使在人类协助不可用的情况下,也能通过自我问答的方式有效地引导导航,降低了通信成本。与基于丰富对话注释的模型相比,SCoA展现出具有竞争力的性能。
本文的工作革新了视觉对话导航领域的通信机制,为实现更加自然、高效的机器人与人类互动的导航系统提供了新的可能,对于推动人机交互技术的发展具有重要意义。
1596
不
不
不
Q
˜
˜
∈
∈
i
=1
一
联系
我们
联系
我们
在房间里找个床头柜
目标
当前
状态
WeTA
指导
行动
解码器
…
视觉视图
SCOA
如果问
WaTA
反馈
…
一
是的,你应该这样做。
Oracle
Wha tT oA sk
(
WaTA
)
问题候选
人
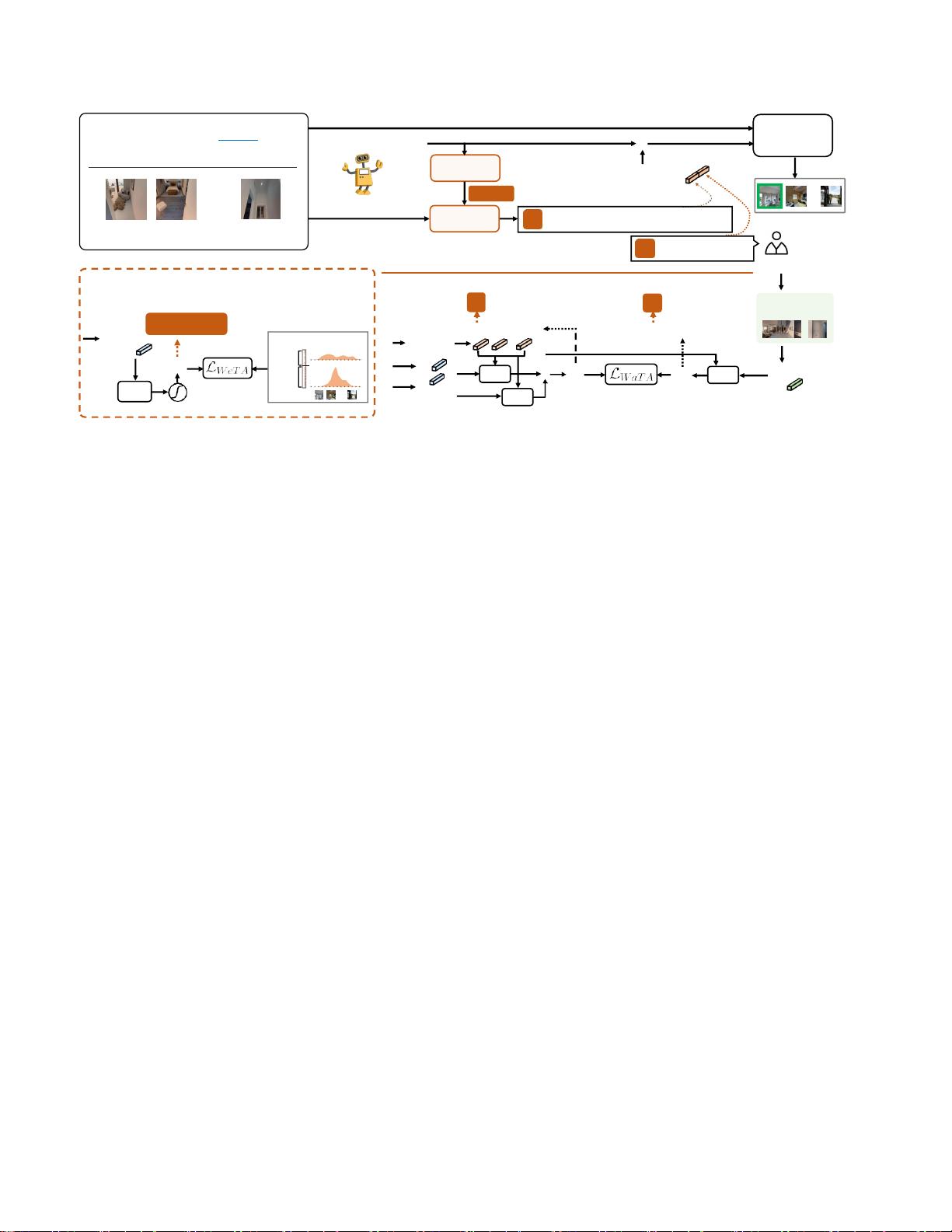
图2:SCoA的培训概述在每个步骤中,WeTA学习预测询问的概率
b
t
,由动作分布
p
a
的熵监督,该熵测量代理对如
果询问,WaTA首先生成
问题候选,然后考虑语言嵌入
to
和视觉特征
X
t
来学习
这些候选的问题分数
α
t
。此外,由观察到最优下一步的预言者提
供的问题的答案得分α
A
用于指导α
Q
。因此,我们的代理可以在一个自我问答的方式,即使在现实世界中的甲骨文
是不可用
不仅任务域中的方法,而且通信方案中的方法,其中
是否与Oracle通信以及与Oracle通信什么是自适应的,
而不涉及劳动密集型对话注释。
3.
方法
3.1.
预赛
问题定义。
给定房屋扫描和起始位置,当智能体
变得困惑并且不知道该做什么时,智能体需要通过
与
oracle
通信来在目标区域中找到目标。在本文中,
Agent
需要
在没有任何问题注释
的情况下决定是否询
问以及询问什么。 我们通过单词嵌入对目标
to
进行编
码以获得
特征
to
R
d
w
,并且
d
w
被设置为
300
。在第
t
个
步骤,代理接收全景视图,然后根据它们的摄像机
航向角和仰角将全景视图划分为
N = 36
个子图像。
每个图像由特征
向 量 t或
x
t
,
i
表 示
从 预 先 训 练 的
Resnet-
152 [6]
中提取的
R d f
,附加有关于相机的航向
和
高度
的嵌入
。
d
f
被设置为2048。 整个
特征集表示为
Xt
=
Xt
,
iN
R
N
×
d
f
.
代理从动作集合
t
预测动作
a
t
,
该动作集合
t
由当前可导航的视点组成。另外,可以
航行的风景
-
点 要 素 集 表 示 为
Zt
=
Zt
,
i
|
i
A
=
|
1
R
|
的
t
| ×
d
f
,
也 从
ResNet-152
中提取。
学习框架。现有研究[26,35,20]中的VDN问题通
常使用强化学习进行优化,其中仅导航动作预测
它被组织成一个策略π
µ
(参见第二节)。3.3)。为了
支持我们的自我激励通信的动机,以在现实世界的不
可见环境中实现对话无注释导航,我们进一步引入了
是否询问(WeTA)策略π
ι
(参见第二节)。3.2.1)和
问什么(WaTA)策略π
κ
(参见第3.2.1节)。3.2.2)。
如图2 、 SCoA 首先决 定是否在不确定去哪里时 通过
WeTA策略寻求帮助如果询问,则代理经由WaTA策略
生成要询问的问题在训练过程中,预言机提取其关于
最佳下一步的知识,以指导智能体模仿预言机 的回
答。这使得我们的代理能够以自我问答的方式导航,
在统一的模仿学习和强化学习框架中,通信与导航联
合优化,驱动智能体以更少的通信成本到达目标第3.4
段)。
3.2.
自激励通信Agent
现有工作中的代理[26,18,35,20]只允许在预定
义的位置提问,不仅导致劳动密集型的学习成本,而
且在现实世界的应用中不灵活的人机通信。为了让代
理自适应地决定是否和问什么,我们提出了一个自我
激励的通信方案,通过引入两个政策,是否要问,问
什么。
3.2.1
是否要求
为了适应现实世界的应用程序,代理应该被委托自适
应地决定是否在过程中提出问题。
(
个
…
ToA sk
(
WeTA
)
问/不问
不确定性度量
状态
MLP
最优下一
步
…
Q
一
。 、
、、
…
。 ,
,,
联系
人
Attn
Attn
问题
评分
答案
分数
Q
我应该直接去沙发上吗?
剩余11页未读,继续阅读
3121 浏览量
2024-11-21 上传
2022-05-11 上传
点击了解资源详情
点击了解资源详情
2025-03-06 上传
2025-03-06 上传
2025-03-06 上传

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全面详实的大学生电工实习报告汇总
- 利用极光推送实现App间的消息传递
- 基于JavaScript的节点天气网站开发教程
- 三星贴片机1+1SMT制程方案详细介绍
- PCA与SVM结合的机器学习分类方法
- 钱能版C++课后习题完整答案解析
- 拼音检索ListView:实现快速拼音排序功能
- 手机mp3音量提升神器:mp3Trim使用指南
- 《自动控制原理第二版》习题答案解析
- 广西移动数据库脚本文件详解
- 谭浩强C语言与C++教材PDF版下载
- 汽车电器及电子技术实验操作手册下载
- 2008通信定额概预算教程:快速入门指南
- 流行的表情打分评论特效:实现QQ风格互动
- 使用Winform实现GDI+图像处理与鼠标交互
- Python环境配置教程:安装Tkinter和TTk
