室内环境中动态物体实例的3D重定位:RIO方法与3RScan基准
137 浏览量
更新于2025-01-16
收藏 17.83MB PDF 举报
RIO(3D物体实例重新定位)是一项前沿的计算机视觉任务,目标是在室内环境中,给定一个或多个在先前RGB-D扫描中的物体,精确估计它们在稍后时间点的另一个3D扫描中的6DoF(六度自由度)姿态,即位置和旋转。这个任务的重要性在于它能支持各种实际应用,比如AI助手和机器人在三维空间中寻找特定物体,对于动态场景理解和室内导航等领域具有重要意义。
为了推动这一领域的研究,研究者开发了名为3RScan的新数据集,包含1482个RGB-D扫描,跨越478个不同的环境,且每个场景都记录了随着时间推移物体位置的变化,还提供了物体实例的精确标注以及与后续扫描的6DoF映射。这些数据集的创建是为了模拟真实世界中物体可能遇到的复杂变化,如不同部分的观察角度和环境的动态影响。
解决RIO任务的关键挑战在于处理部分观测和环境变化导致的特征匹配难题。传统的特征匹配方法往往在这样的情况下表现不佳。因此,研究团队提出了一个创新的数据驱动方法,采用全卷积3D对应网络在多空间尺度上操作,有效地找出匹配特征。这种网络架构能够适应复杂的空间结构和动态场景,提高了特征匹配的准确性。
为了评估其性能,研究者设计了专门的基准,并通过6DoF姿态优化进一步提升了方法的精度。结果显示,他们的方法在3RScan基准上达到了30.58%的准确率,相较于现有基线方法有显著优势。这标志着他们在解决动态室内环境中3D物体实例重新定位问题上取得了突破,为未来的研究者提供了一个有价值的研究平台和技术参考。
7658
0
RIO:在变化的室内环境中的3D物体实例重新定位
0
JohannaWald1ArmenAvetisyan1NassirNavab1FedericoTombari1,2,MatthiasNießner1,
0
1慕尼黑工业大学2谷歌
0
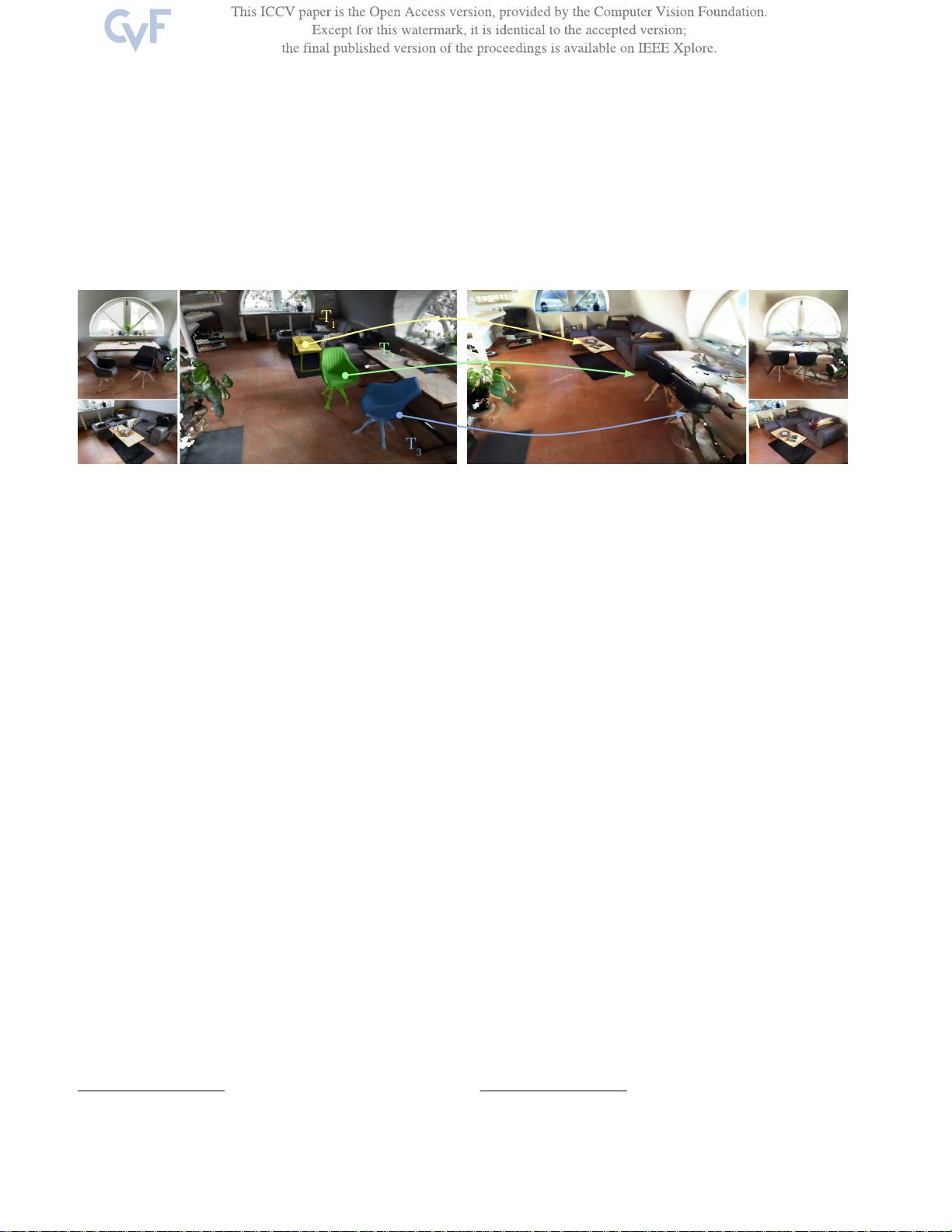
图1:3D物体实例重新定位基准:我们希望从分割的源扫描到稍后时间点拍摄的目标扫描中鲁棒地估计改变的刚性物体实例的6DoF姿态(T1
,T2,...Tn)。
0
摘要
0
在这项工作中,我们引入了3D物体实例重新定位(RIO)的
任务:给定一个或多个物体在RGB-D扫描中,我们希望估计
它们在同一环境的稍后时间点拍摄的另一个3D扫描中的相应
的6DoF姿态。我们认为RIO是3D视觉中一项特别重要的任
务,因为它可以实现广泛的实际应用,包括要求AI助手或机
器人在3D场景中找到特定物体。为了解决这个问题,我们首
先引入了3RScan,这是一个新的数据集和基准,它包含了1
482个跨多个时间步骤的478个环境的RGB-D扫描。每个场
景包括几个物体,它们的位置随时间变化,以及物体实例的
地面真值注释和它们在重新扫描中的相应的6DoF映射。自动
找到6DoF物体姿态导致了一个特别具有挑战性的特征匹配任
务,因为存在不同的部分观测和周围环境的变化。为此,我
们引入了一种新的数据驱动方法,使用在多个空间尺度上操
作的全卷积3D对应网络高效地找到匹配特征。结合6DoF姿
态优化,我们的方法在我们新建立的基准上优于现有的基线
方法,达到了30.58%的准确率。
0
*作者共享高级作者资格。
0
1.引言
0
室内环境的3D扫描和理解是计算机视觉中的一个基础研究方
向,为从室内机器人到增强和虚拟现实等各种应用奠定了基
础。特别是,RGB-D扫描系统的快速进展[17,18,31,
6]使得可以仅使用低成本的扫描设备(如微软Kinect、英特
尔Real
Sense或谷歌Tango)获得室内场景的3D重建。随着捕捉3
D地图的能力,研究人员对使用这些表示进行3D场景理解表
现出了显著的兴趣,并发展了一系列快速发展的研究,专注
于诸如3D语义分割[4,19,
26]或3D实例分割[10]等任务。然而,这些工作之间的共同
之处在于它们只考虑静态场景环境。在这项工作中,我们关
注的是随时间变化的环境。具体而言,我们引入了物体实例
重新定位(RIO)的任务:给定一个或多个物体在RGB-D扫
描中,我们希望估计它们在同一环境的另一个不同时间点拍
摄的3D扫描中的相应的6DoF姿态。因此,捕获的重建自然
涵盖了各种时间变化;见图1。我们认为这对于许多室内应
用来说是一个关键任务,例如,对于机器人或虚拟助手来在
其周围环境中找到特定物体。RIO中的主要挑战-找到每个物
体的6DoF-在于建立重扫描之间的良好对应关系,这是一个
非常困难的问题,因为不同的扫描模式和不断变化的几何上
下文。
0
https://waldjohannau.github.io/RIO/
下载后可阅读完整内容,剩余9页未读,立即下载
2021-04-08 上传
2021-05-27 上传
2021-05-01 上传
2021-05-15 上传
2021-05-27 上传
115 浏览量
2021-05-12 上传
2021-03-06 上传

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Ruby语言集成Mandrill API的gem开发
- 开源嵌入式qt软键盘SYSZUXpinyin可移植源代码
- Kinect2.0实现高清面部特征精确对齐技术
- React与GitHub Jobs API整合的就业搜索应用
- MATLAB傅里叶变换函数应用实例分析
- 探索鼠标悬停特效的实现与应用
- 工行捷德U盾64位驱动程序安装指南
- Apache与Tomcat整合集群配置教程
- 成为JavaScript英雄:掌握be-the-hero-master技巧
- 深入实践Java编程珠玑:第13章源代码解析
- Proficy Maintenance Gateway软件:实时维护策略助力业务变革
- HTML5图片上传与编辑控件的实现
- RTDS环境下电网STATCOM模型的应用与分析
- 掌握Matlab下偏微分方程的有限元方法解析
- Aop原理与示例程序解读
- projete大语言项目登陆页面设计与实现
