燃料电池混合动力汽车能量管理的模糊REINFORCE函数逼近强化学习
194 浏览量
更新于2025-01-16
收藏 1.98MB PDF 举报

能源与人工智能
13
(
2023
)
100246
燃料电池混合动力汽车能量管理的模糊
REINFORCE
函数逼近强化学习
郭亮
a
,
*
,李忠良
a
,
b
,
*
,拉希德·奥特比b
a
,高
飞
c
a
艾克斯
-
马赛大学,
LIS UMR CNRS 7020
,法国
b
Universit'e
de
Franche-Com
t'e
,
UTBM
,
CNRS
,
institut
FEMTO-ST
,
F-90000
Belfort
,
France
c
UTBM
,
CNRS
,
institut FEMTO-ST
,
F-90000 Belfort
,
France
H I G H L I G H T S G R A P H I C A L A B标准
•
应用强化学习解决能源管理问题:一种
传统的序贯决策优化方法
约束问题。
•
无模型的REINFORCE是一个蒙特卡洛策
略梯度强化学习,可以通过与
环境,没有建模或历史数据。
•
功能 辅 助 器 与 模糊
推理 系统 到 approX imate the
加强政策功能。
•
在不影响策略梯度方向的前提下,提出
了模糊基线函数来
A R T I C L E I N FO
保留字:
能源管理策略燃料电池混合动力
汽车强化学习
模糊推理系统模糊策略
梯度硬件在环
A B标准
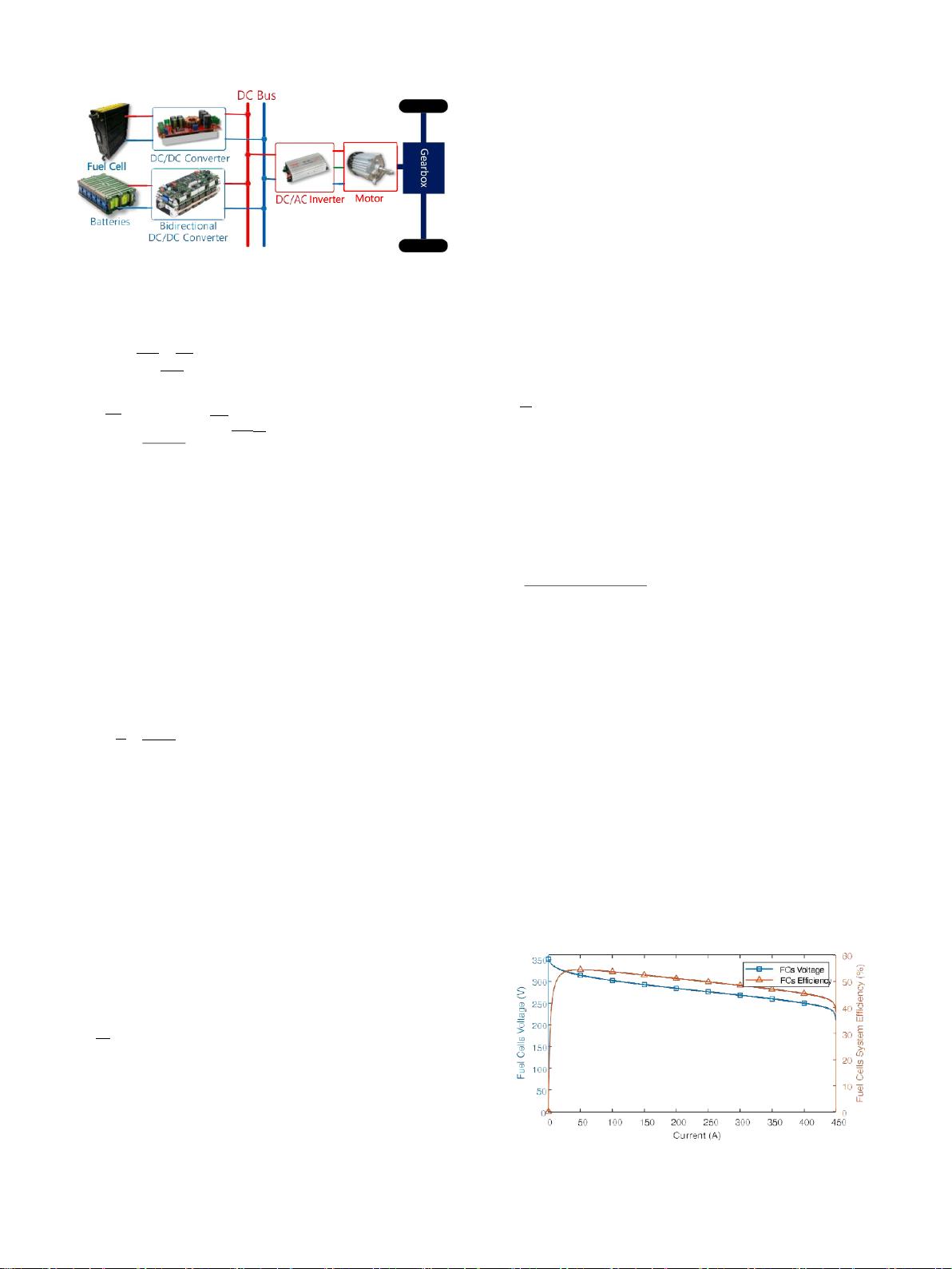
针对燃料电池混合动力汽车(FCHEV),提出了一种新的自学习能量管理策略(EMS),以实现燃料电池混合
动力汽车(FCHEV)的氢气节约和电池的正常运行。在EMS中,提出用模糊推理系统(FIS)来近似EMS策略函
数 ,并通过策略梯度强化 学 习 ( PGRL) 来 学 习 策 略 参 数 。 因 此 , 本 文 首 次 提 出 并 研 究 了 EMS问 题 的 模 糊
REINFORCE算法。模糊REINFORCE是一种无模型的方法,EMS代理可以通过与环境的交互来学习自己,这使得
它不依赖于模型的准确性,先验知识和专家经验。同时,为了稳定训练过程,在不影响策略梯度方向的情况
下,采用模糊基线函数对基于FIS的值函数进行逼近。此外,还可以克服传统强化学习计算量大、收敛时间长等
缺点。硬件在环实验验证了所提方法的有效性。同时验证了该方法对驾驶条件和系统状态变化的适应性。
* 通讯作者。
电子邮件地址:
liang. lis-lab.fr(L.Guo),zhongliang.li @ univ-fcomte.fr(Z.Li)。
https://doi.org/10.1016/j.egyai.2023.100246
2023年2月26日在线提供
2666-5468/© 2023作者。由爱思唯尔有限公司出版。这是一篇开放获取的文章,获得了CC BY-NC-ND许可证(http://creativecommons.org/licenses/by-nc-
nd/4.0/)。
可在ScienceDirect上获得目录列表
能源与AI
期刊主页:www.sciencedirect.com/journal/energy-and-ai

剩余12页未读,继续阅读
333 浏览量
179 浏览量
798 浏览量
509 浏览量
156 浏览量
410 浏览量

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- WebDrive v16.00.4368: 简易易用的Windows风格FTP工具
- FirexKit:Python的FireX库组件
- Labview登录界面设计与主界面跳转实现指南
- ASP.NET JS引用管理器:解决重复问题
- HTML5 canvas绘图技术源代码下载
- 昆仑通态嵌入版ASD操舵仪软件应用解析
- JavaScript实现最小公倍数和最大公约数算法
- C++中实现XML操作类的方法与应用
- 设计编程工具集:材料重量快速计算指南
- Fancybox:Jquery图片轮播幻灯弹窗插件推荐
- Splunk Fitbit:全方位分析您的活动与睡眠数据
- Emoji表情编码资源及数据库查询实现
- JavaScript实现图片编辑:截取、旋转、缩放功能详解
- QNMS系统架构与应用实践
- 微软高薪面试题解析:通向世界500强的挑战
- 绿色全屏大气园林设计企业整站源码与多技术项目资源
