记忆增强自监督跟踪器:MAST在视频密集跟踪中的应用
155 浏览量
更新于2025-01-16
收藏 18.95MB PDF 举报
"MAST:一种记忆增强的自监督跟踪器"
在计算机视觉领域,目标跟踪是至关重要的一环,特别是对于视频分析和理解。传统的跟踪方法往往依赖于大量的人工注释数据进行监督学习,例如ImageNet预训练的ResNet作为特征编码器,再在如COCO、Pascal、DAVIS和YouTube-VOS等具有精细像素级分割标注的数据集上进行微调。然而,这种自顶向下的训练策略并不符合人类视觉系统的发展规律,因为婴儿可以在不具备语义理解能力的情况下跟踪移动物体。
近年来,研究者们开始探索自监督学习的方法,以减少对人工标注的依赖。"记忆增强自监督跟踪器"(MAST)正是这一趋势的产物,它旨在通过自我监督的方式提高跟踪性能,同时利用记忆组件来增强模型的学习能力。在MAST中,关键的记忆组件扮演了重要的角色,它能够存储和检索历史信息,帮助模型在视频序列中保持对目标对象的持续追踪。
自监督训练和重建损失是MAST的核心机制。在没有明确的标签情况下,模型通过对连续帧中的同一对象进行预测,并尝试重建原始输入,从而学习到表示目标的有用特征。这种自我监督的方式允许模型从无标注数据中学习,减少了对外部注释的依赖。同时,通过引入记忆模块,模型可以处理目标遮挡、形变以及光照变化等问题,提高跟踪的鲁棒性。
MAST的密集跟踪模型不仅关注对象的粗略位置,还致力于实现像素级别的精细化追踪,即半监督视频对象分割(Semi-VOS)。这种方法要求模型能够在整个视频中精确地框出目标,并生成像素级的分割掩模,极大地提升了跟踪的精度和细致度。
MAST通过记忆增强的自监督学习策略,提供了一种新颖且有效的目标跟踪解决方案。它挑战了传统依赖于大量注释数据的训练方式,朝着更符合人类视觉发展规律的方向迈进,为未来无监督或弱监督的视觉跟踪研究开辟了新的路径。通过不断迭代和优化,这种技术有望在自动驾驶、监控系统以及其他需要实时目标识别和追踪的场景中发挥重要作用。
10
0
10
1
10
2
10
3
10
4
10
5
10
6
10
7
30
40
50
60
70
80
90
with bounding boxes throughout the video; the other aims
for more fine-grained tracking, i.e. relocalize the objects
with pixel-level segmentation masks, also known as Semi-
supervised Video Object Segmentation (Semi-VOS) [48].
In this paper, we focus on the latter case, and will refer to it
interchangeably with dense tracking from here on.
In order to train such dense tracking systems, most re-
cent approaches rely on supervised training with extensive
human annotations (see Figure
1). For instance, an Ima-
geNet [10] pre-trained ResNet [18] is typically adopted as a
feature encoder, and further fine-tuned on images or video
frames annotated with fine-grained, pixelwise segmenta-
tion masks, e.g. COCO [40], Pascal [13], DAVIS [48] and
YouTube-VOS [71]. Despite their success, this top-down
training scheme seems counter-intuitive when considering
the development of the human visual system, as infants can
track and follow slow-moving objects before they are able
to map objects to semantic meanings. With this evidence, it
is unlikely the case that humans develop their tracking abil-
1
6479
0
MAST:一种记忆增强的自监督跟踪器
0
ZihangLaiErikaLuWeidiXieVisualGeometryGroup,
DepartmentofEngineeringScienceUniversityofOxford
0
{zlai,erika,weidi}@robots.ox.ac.uk
0
摘要
0
最近对自监督密集跟踪的兴趣取得了快速进展,但性能仍远
远落后于监督方法。我们提出了一种在没有任何注释的视频
上训练的密集跟踪模型,其在现有基准测试中显著超过了以
前的自监督方法(+15%),并且达到了与监督方法相当的
性能。在本文中,我们首先重新评估了用于自监督训练和重
建损失的传统选择,通过进行彻底的实验,最终阐明了最佳
选择。其次,我们通过关键的记忆组件增强了现有方法。第
三,我们在大规模半监督视频对象分割(又称密集跟踪)上
进行了基准测试,并提出了一个新的度量标准:泛化能力。
我们的前两个贡献产生了一个自监督网络,该网络首次在密
集跟踪的标准评估指标上与监督方法竞争。在测量泛化能力
时,我们表明自监督方法实际上优于大多数监督方法。我们
相信这个新的泛化能力度量标准可以更好地捕捉密集跟踪的
真实世界用例,并将激发对这个研究方向的新兴兴趣。代码
将在https://github.com/zlai0/MAST发布。
0
1.引言
0
尽管人类视觉系统的工作机制在神经生理学层面上仍然有些
不明确,但人们普遍认为追踪物体是婴儿在两三个月大时开
始发展的一种基本能力。同样,在计算机视觉系统中,追踪
在许多应用中起着关键作用,从自动驾驶到视频监控。给定
第一帧中定义的任意对象,跟踪算法旨在在整个视频序列中
重新定位相同的对象。在文献中,跟踪可以分为两类:第一
类是视觉目标跟踪(VOT),其目标是重新定位对象
0
像素级注释数量(对数刻度)
0
DA
VIS
-2
01
7J
&
F(
平
均
)
0
视频着色
0
CycleTime
CorrFlow
0
mgPFF
0
PReMVOS
0
OSVOS
0
OnAVO
00
RGMP
0
OSMN
0
FAVOS
0
FEELVOS
0
RANet
0
VOSwL
0
AGAME
0
RVOS
0
SiamMask
0
我们的方
法
0
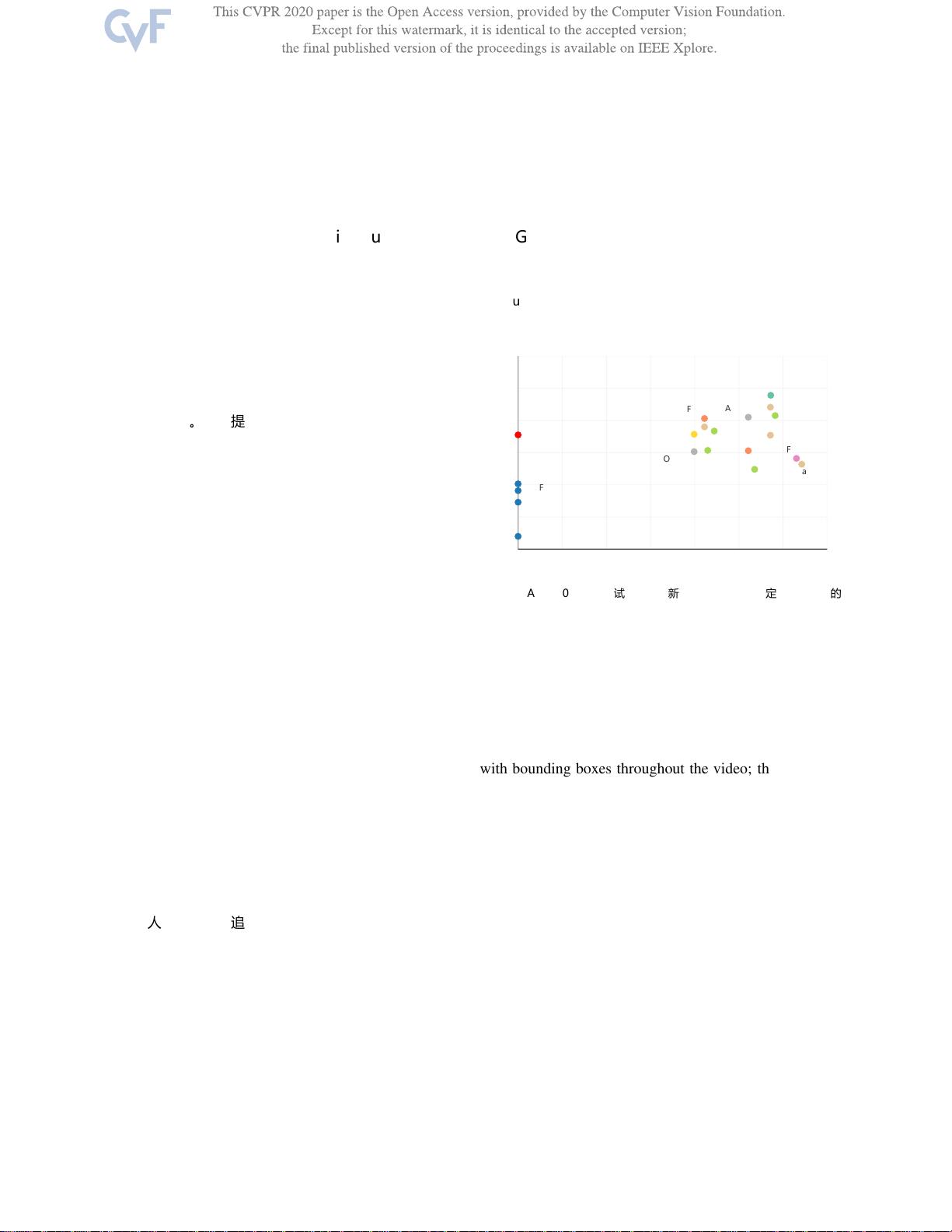
图1:与DAVIS-2017基准测试中其他最新工作的比较,即给定第一帧注释的
密集跟踪或半监督视频分割。所提出的方法在自监督方法中明显优于其他方
法,并且甚至与在ImageNet、COCO、Pascal、DAVIS、Youtube-VOS上
进行重度监督训练的方法相媲美。在x轴上,我们只计算像素级分割。符号说
明:CINM[3],OSVOS[6],FAVOS[8],AGAME[28],VOSwL
[31],mgPFF[33],CorrFlow[37],DyeNet[39],PReMVOS
[41]。OSVOS-S[42],RGMP[44],RVOS[54],FEELVOS
[56],OnAVOS[57],VideoColorization[59],SiamMask
[61],CycleTime[64],RANet[65],OSMN[73]。
下载后可阅读完整内容,剩余9页未读,立即下载
2021-03-19 上传
355 浏览量
2021-03-30 上传
207 浏览量
132 浏览量
207 浏览量
点击了解资源详情
点击了解资源详情

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 网页自动刷新工具 v1.1 - 自定义时间间隔与关机
- pt-1.4协程源码深度解析
- EP4CE6E22C8芯片三相正弦波发生器设计与实现
- 高效处理超大XML文件的查看工具介绍
- 64K极限挑战:国际程序设计大赛优秀3D作品展
- ENVI软件全面应用教程指南
- 学生档案管理系统设计与开发
- 网络伪书:社区驱动的在线音乐制图平台
- Lettuce 5.0.3中文API文档完整包下载指南
- 雅虎通Yahoo! Messenger v0.8.115即时聊天功能详解
- 将Android手机转变为IP监控摄像机
- PLSQL入门教程:变量声明与程序交互
- 掌握.NET三层架构:实例学习与源码解析
- WPF中Devexpress GridControl分组功能实例分析
- H3Viewer: VS2010专用高效帮助文档查看工具
- STM32CubeMX LED与按键初始化及外部中断处理教程
