VLC-BERT:上下文常识提升视觉问答性能
PDF格式 | 1.04MB |
更新于2025-01-16
| 14 浏览量 | 举报
VLC-BERT是一项针对视觉问答(Visual Question Answering,VQA)任务的创新研究,它着重于解决需要常识推理的问题。传统的VQA模型往往依赖于静态知识库,但这种方法往往缺乏准确性和覆盖率,因为常识知识范围广泛且难以捕捉。 VLC-BERT(Visual Language Commonsense Transformer-BERT)引入了上下文常识知识,通过融合现有的知识模型COMET(Commonsense Knowledge Transformer)以及视觉和文本线索。
VLC-BERT的核心创新在于其设计了一个方法,能够生成、选择和编码来自COMET等人工策划的知识库中的常识知识,使之适应视觉和文本输入。它采用了Transformer架构,这种预训练模型在大规模多模态数据集上进行训练,如大规模视觉语言数据,从而提高了模型在处理复杂情境时的能力。
在实验中,VLC-BERT在知识密集型的OK-VQA和A-OKVQA数据集上的表现超越了那些依赖静态知识库的现有模型,显示出上下文常识知识的有效性。然而,值得注意的是,并非所有问题都能同等受益于上下文常识,因为可能存在某些特定领域的问题,比如文本中可能存在的报告偏见,使得某些常识性知识并不适用。
通过深入分析,研究人员揭示了哪些类型的问题可以从上下文常识中获益,以及如何在实际应用中优化模型,使其更贴近人类的常识推理能力。VLC-BERT的代码开源,可供研究者进一步研究和改进,这对于提升视觉问答系统的智能水平具有重要意义。
VLC-BERT的出现标志着视觉问答研究的一个新阶段,它强调了常识知识在模型性能提升中的关键作用,同时也提出了如何更有效地结合和利用外部知识库的挑战和机遇。随着技术的发展,未来的研究可能会探索更多元、更具深度的常识集成策略,以实现更真实的跨模态交互和理解。
1157
-
-
×
雨伞可以遮阳,
雨伞可以防雨
(a)
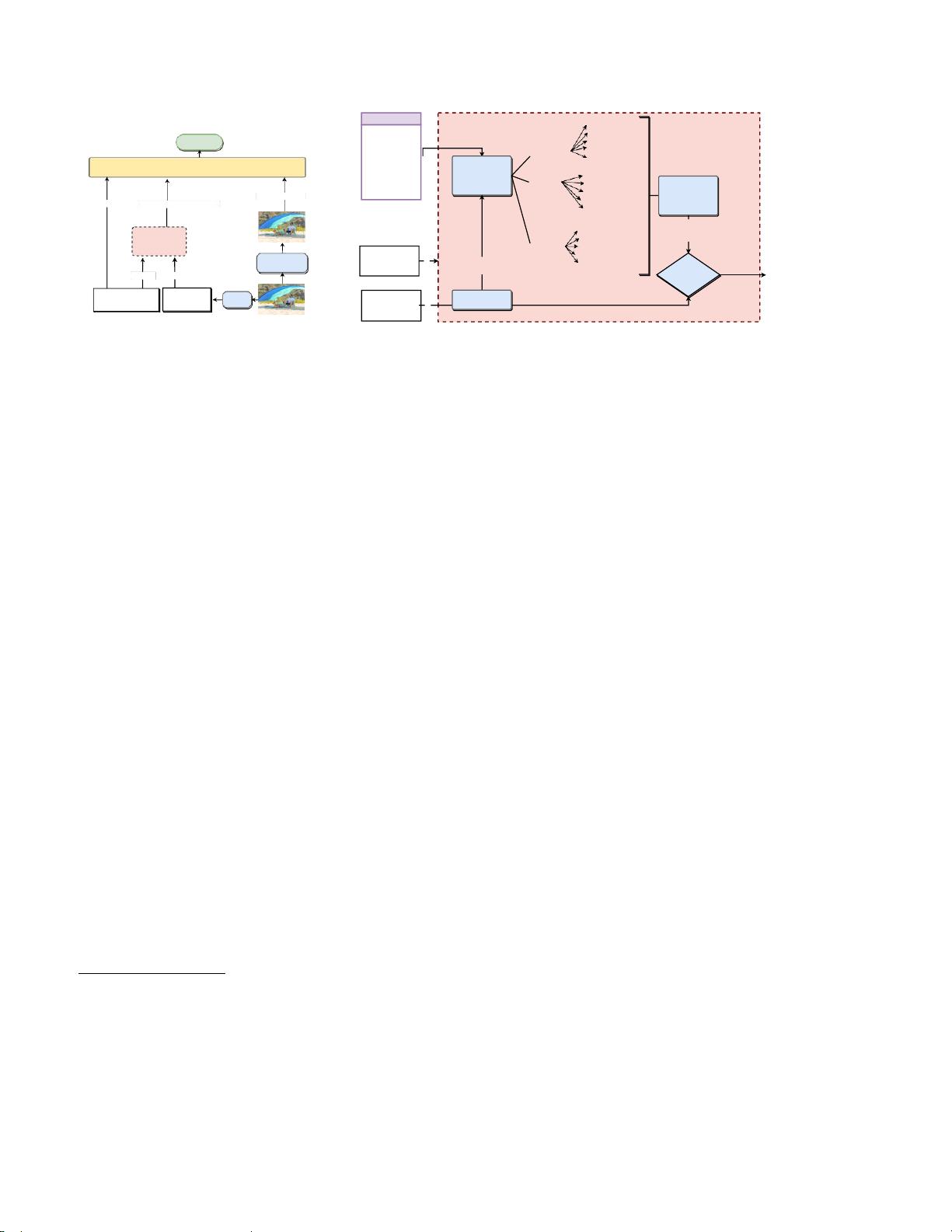
整体架构
图像
(b)
知识生成和选择
图
2
:
VLC-BERT
的架构
:给定一个图像,
VLC-BERT
使用
COMET
为问题对象短语生成常识推理这些推断是
相关性排名的,并且顶部的推断被选择并与图像区域一起馈送到
VL-
变换器中以便产生答案。我们利用
Q
和
C
之间的语义相似性来选择进入
VLC-BERT
的最终
K
图
2a
示出了
VLC-BERT
流水线。给定
具有使用
快速
RCNN [10]
预先计算的对应图像区域
I
的图像和与图像相
关的问题
Q
,我们生成关于问题短语和两个对象标签
O
中的事件和实体的常识推断
C
,并选择最用于回答
问题的常识推断集合
C
=
C
1
,C
2
,
.
,
C
k
(
§3.1
)。最
后,我们将
Q
、
I
和
C
作为输入嵌入到
VLC-BERT
中,
并训练它来预测答案
A
到
Q
(
§3.2
)。
3.1.
结构化知识生成与选择
3.1.1
知识生成
为了生成常识知识,我们采用了最新版本的COMET
[15],该 版本在 零触 发设置 中使用BART[19]初始化
COMET被训练来完成来自ConceptNet [40](如AtLoca-
tion,Madeof)和ATOMIC [35](如xNeed,xWants)
的50种关系类型,从而捕获概念以及面向事件的知
识。我们生成的30个关系类型的基础上最相关的evant
我们的工作和支持COMET的推理。
[1]
考虑图2b所示 对
于给定的问题,“
雨伞的用途是什么?
” 我们首先使用
AllenNLP的选区解析器[17]处理每个问题,并将其转换为
陈述句,因为COMET主要是在陈述句上训练的。在所示
的示例中,“伞的用途是什么
?
“改为然后,我们采用
最先进的对象检测模型YOLOv5 [16],将相应的图像
转换为COMET可以理解的对象标签。我们选择前两个
最有信心的对象标签,并将其与问题短语相结合,以
获得一个问题对象(QO)短语,
[1
]我们在补充材料中包括了关系类型的完整列表
“
狗和椅子
我们将COMET的输入中使用的对象标签的
数量以这种方式,我们可以获得可以向VLC-BERT提
供关于视觉和语言输入的附加知识的推断。
我们使用波束搜索来解码每个关系类型的前5个推
理,根据模型的置信度进行排名。总的来说,对于每
个输入短语,我们得到30 5
=
150个推断。 最后,我们
使用[7]中定义的在所示的示例中,断言
<
雨伞,
位于
,商店
>
表示为“你很可能在商店找到雨
伞”。为了去除相同关系类型的冗余句子,我们通过测
量两个给定句子之间的公共词的百分比来测量词汇重
叠我们排除了与先前构建的相同关系的句子重叠超过
70%的句子。
3.1.2
知识选择
由于计算的高成本,以及与馈送如此大量的文本标
记相关联的噪声,将多达
150
个
COMET
推断馈送到
VL
变换器模型中是不切实际的。为了排名和选择推
理,我们采用基于句子转换器(
SBERT
)的语义搜
索
[31]
,这些句子转换器在检索搜索查询的候选答
案的任务上进行了预训练在该方法中,使用
SBERT
[31]
将问题和推理嵌入到相同的向量空间中,并使
用问题和推理嵌入之间的余弦相似度我们通过挑选
K
=
5个推断来修剪推断句子集合
C
回答
VLC-BERTTransformer
图像区域(
I
)
问题(
Q
)
常识推理(C)
知识生成选
择
Fast
(
er
)
R-
CNN
问题对象标签
为什么他们有雨
伞?
YOLOv5
狗椅子
地点
彗星
雨伞伞架店
车库停
车场
伞柄
MadeOf伞头伞
...
伞骨
...
伞帽
...
...
防雨防晒
句子结构
你很可能会发现伞在商店伞是由伞头
...
UsedFor
O
保护自己
C1
C
n
保持狗干燥
雨伞的用途
狗和椅子
用作武器
语义
C
1
. C
K
搜索
(
SBER
Q
问题陈述
知识 生成选择
雨伞的用途是
什么?
CapableOf
具有属性
AtLocation
导致
xWant
...
关系
狗,椅子
剩余10页未读,继续阅读
相关推荐

363 浏览量

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 自动生成CAD模型文件的测试流程
- 掌握JavaScript中的while循环语句
- 宜科高分辨率编码器产品手册解析
- 探索3CDaemon:FTP与TFTP的高效传输解决方案
- 高效文件对比系统:快速定位文件差异
- JavaScript密码生成器的设计与实现
- 比特彗星1.45稳定版发布:低资源占用的BT下载工具
- OpenGL光源与材质实现教程
- Tablesorter 2.0:增强表格用户体验的分页与内容筛选插件
- 设计开发者的色值图谱指南
- UYA-Grupo_8研讨会:在DCU上的培训
- 新唐NUC100芯片下载程序源代码发布
- 厂家惠新版QQ空间访客提取器v1.5发布:轻松获取访客数据
- 《Windows核心编程(第五版)》配套源码解析
- RAIDReconstructor:阵列重组与数据恢复专家
- Amargos项目网站构建与开发指南
