ChamNet: 平台感知神经网络架构优化
187 浏览量
更新于2025-01-16
收藏 975KB PDF 举报
ChamNet: 一种创新的平台感知神经网络(NN)架构设计方法,由戴晓亮等人提出,旨在解决在资源受限的设备上部署深度学习模型的挑战。不同于传统的构建新块或依赖于计算密集型强化学习,ChamNet侧重于现有高效网络组件的利用,并通过智能调整计算资源来适应目标的延迟和能耗约束。
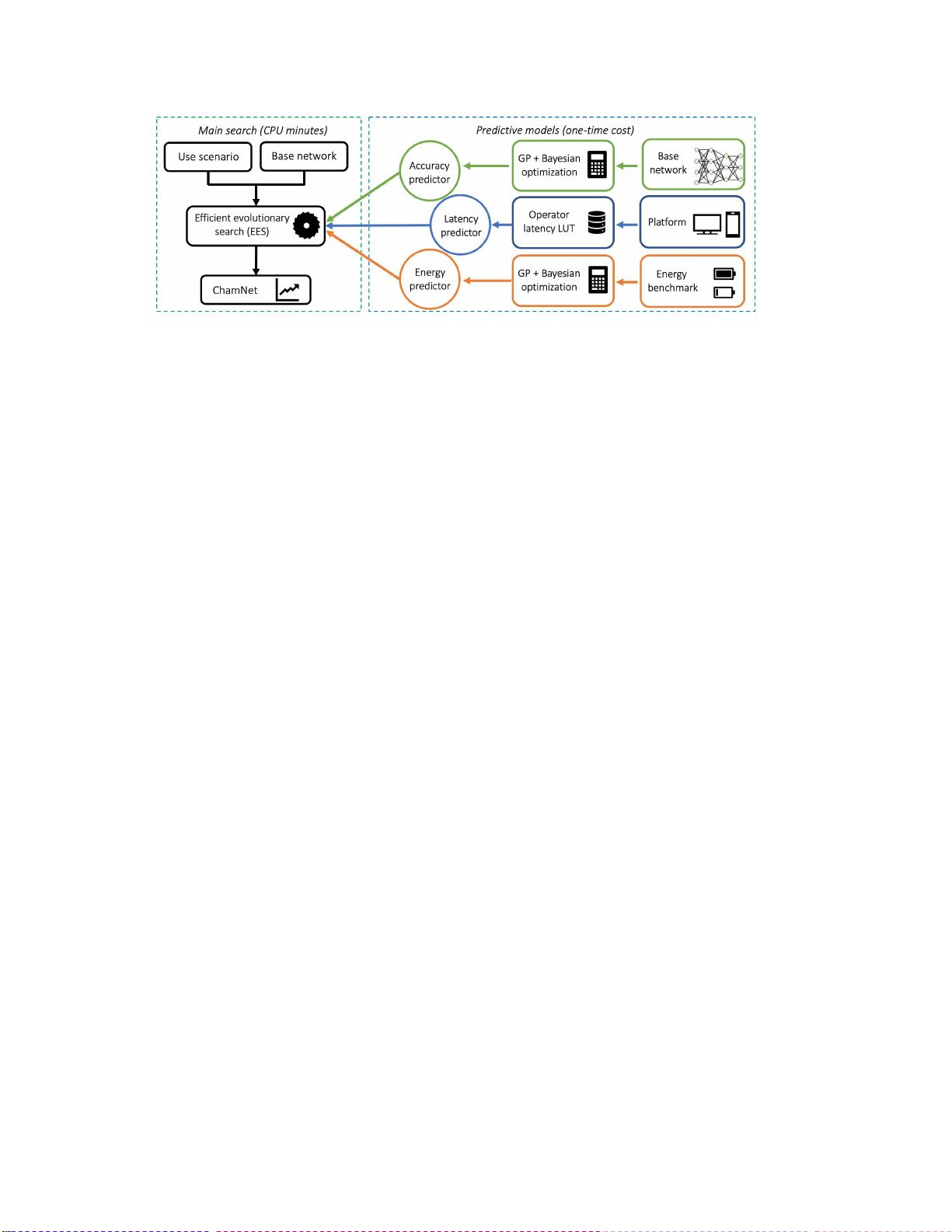
核心亮点是该方法采用了一个精度预测器,基于高斯过程和贝叶斯优化的迭代采样策略。这个预测器允许算法在几分钟内生成先进的模型架构,满足指定的硬件限制。其优势在于,一次性构建预测器的成本使得整个搜索过程高效且快速。
实验结果显示,ChamNet在保持模型先进性的前提下,显著提高了准确性。例如,在移动CPU和DSP上,它实现了73.8%和75.3%的ImageNet top-1精度,与MobileNetV2和MnasNet相比,分别有8.2%和4.8%的提升,即使在降低延迟条件下也能保持较高的性能。在Nvidia GPU和Intel CPU上,与ResNet-101和ResNet-152相比较,ChamNet分别提升了2.7%和5.6%的精度,证明了其在不同平台上的通用性和优化效果。
ChamNet的研究背景强调了针对特定硬件平台进行模型设计的重要性,因为不同的硬件有着独特的特性和限制。尽管已有紧凑模型如[24, 21]减少了计算成本,但在实际部署中,单一的模型结构往往难以兼顾所有平台的需求。ChamNet的方法通过平台感知,为解决这一问题提供了一种有效且高效的解决方案。通过集成现有高效构建块和智能资源管理,ChamNet展示了在资源约束条件下,如何实现模型性能的显著提升,从而推动了在移动设备和其他资源受限环境下的深度学习应用发展。
11400
图
1.
变色龙适应框架
rithm [26],其中NN架构的基因由超参数向量表示(例
如,#过滤器和#瓶颈),表示为
x∈R
n
,其中
n
是感兴
趣的超参数在每次迭代中,EES根据以下条件评估每
个NN架构候选者的适应度:
输入的预测模型,然后选择具有最高适应度的架构,
使用变异和交叉算子繁殖下EES在预定义的迭代次数
后终止最后,Chameleon基于目标平台和使用场景的适
应性NN架构。
我们制定EES作为一个约束优化问题。目标是在目
标平台上的给定资源限制下最大限度地提高准确性:
在F(x
,
plat)≤thres
(
1)的条件下最大化A(x)
其中
A
、
F
、
plat
和
thres
指的是
x
到网络准确度的映射,
x
到网络性能度量的映射(例如,等待时间或能量)、
目标平台,以及由使用场景确定的资源约束(例如,
20ms)。我们将资源约束合并为适应度函数
R
中的正
则化项,如下所示:
R
=
A
(
x
)
−
[
αH
(
F
(
x
,
plat
)
−
thres
)
]
w
(
2
)
其中
H
是Heaviside阶跃函数,
α
和
w
是正常数。因此,
目标是找到使R最大化的网络基因x:
然而,通过网络训练和硬件上的直接测量来提取上
述度量太耗时[19]。为了加快这个过程,我们通过利
用准确性,延迟和能量预测器来绕过训练和测量过
程,如图所示。1.这些预测器使度量估计在不到一个
CPU秒。接下来,我们将详细介绍我们的准确性、延
迟和能量预测器
3.2.
高效的精度预测器
为了显着加快NN架构候选评估,我们利用准确度预
测器来估计模型的最终准确度,而无需实际训练它。
这种预测器有两个期望的目标:
1.
可靠的预测:预测器应该最小化预测精度和实际
精度之间的距离,并按照与实际精度相同的顺序
对模型进行排序。
2.
样品效率:预测器应该用尽可能少的训练过的网
络架构来构建。这节省了计算资源。
接下来,我们将解释如何通过GP回归和基于贝叶斯优
化的样本结构选择来实现这两个目标。
3.2.1
高斯过程模型
我们选择一个GP回归量作为我们的准确性预测因子,
以模型
A
为:
x =argmax
(
R
)
(
3
)
A(x
i
)=
f
(x
i
)+f
(
x
i
)
,
i = 1
,
2
,
.
,
S
(
四
)
x
f
(
·
)
<$
G
P
(
·
|
0
,
K
)
,
中国
(
·
|
2
0
,
σ
)
我们接下来估计
F
和
A
来解决优化问题。
F
的选择取
决于兴趣约束 在这项工作中,我们主要研究基于直
接延迟和
能量测量的F,而不是间接代理,如
FLOP
,
已被证明是次优的
[33]
。因此,对于每个
NN
候选者
x,我们需要三个指标来计算其
R
(x):准确性,延
迟和能耗。
其中,i表示s个训练向量中的训练向量
的索引
,并且n
i
表示具有独立N(·)的噪声变量
。
|
0
,
σ
2
)
分
布。
f
(
·
)
是根据
由协方差矩阵K表征
的
GP
先验确定
的。我们对K使用径向基函数核:
K
(
x
,
x
′
)
=
e
x
p
(
−
γ
||
x
−
x
′
||
(
2
)
(
5
)
我
剩余10页未读,继续阅读
2025-03-06 上传
2025-03-06 上传
2025-03-06 上传
2025-03-06 上传

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Verilog实现的Xilinx序列检测器设计教程
- 九度智能SEO优化软件新版发布,提升搜索引擎排名
- EssentialPIM Pro v11.0 便携修改版:全面个人信息管理与同步
- C#源代码的恶作剧外表答题器程序教程
- Weblogic集群配置与优化及常见问题解决方案
- Harvard Dataverse数据的Python Flask API教程
- DNS域名批量解析工具v1.31:功能提升与日志更新
- JavaScript前台表单验证技巧与实例解析
- FLAC二次开发实用论文资料汇总
- JavaScript项目开发实践:Front-Projeto-Final-PS-2019.2解析
- 76云保姆:迅雷云点播免费自动升级体验
- Android SQLite数据库增删改查操作详解
- HTML/CSS/JS基础模板:经典篮球学习项目
- 粒子群算法优化GARVER-6直流配网规划
- Windows版jemalloc内存分配器发布
- 实用强大QQ机器人,你值得拥有
