自动合成数据高效任务级的弱监督源
PDF格式 | 1.91MB |
更新于2025-01-16
| 176 浏览量 | 举报
2211
用于行为分析的多种弱监督源的自动综合
Albert Tseng
Nuro
,
†
詹妮弗
·J Sun
Caltech
Yisong Yue
Caltech,Argo
AI
摘要
获取大型训练集的注释是昂贵的,特别是在需要领
域知识的设置中,例如行为分析。已经研究了弱监督
以通过使用来自任务特定的标签函数(
LF
)的弱标签
来增强地面真值标签来降低注释成本。然而,领域专
家仍然需要为不同的任务手工制作不同的
LF
,这限制
了可扩展性。 为了减少专家的工作量,我们提出了
AutoSWAP
: 自动合成数据高效任务级
LF
的框架。我
们的方法的关键是有效地表示专家知识在一个可重用
的领域特定的语言和更一般的领域级的
LF
,我们使用
国家的最先进的程序合成技术和一个小的标记数据集
生成任务级的
LF
。此外,我们提出了一种新的结构多
样性成本,允许有效地合成不同的
LF
集,进一步提高
AutoSWAP
我们评估
AutoSWAP
在三个行为分析领域,
并证明了
Au- toSWAP
优于现有的方法,只使用一小部
分的数据。我们的研究结果表明,
AutoSWAP
是一种有
效的方法来自动生成
LF
,可以显着减少专家的努力,
行为分析。
1.
介绍
近年来,机器学习已经使许多行为分析领域的大规
模数据集研究成为可能,例如神经科学[24,27],体
育分析[30,37]和运动预测[7]。然而,获得标记数据
来训练模型可能是困难和昂贵的,特别是当注释需要
专业知识时,例如许多行为分析任务[24]。降低注释
成本的一种方法是通过弱监督,其使用有噪声的任务
级启发式特定任务的LF(任务级LF)由领域专家提
供,并应用于获得一组弱标签。弱标记数据可以用于
下游设置,例如主动学习[4]和自我训练[17]。
*
作者在加州理工学院工作期间所做的工作
[2]电子邮件
:atseng@caltech.edu。
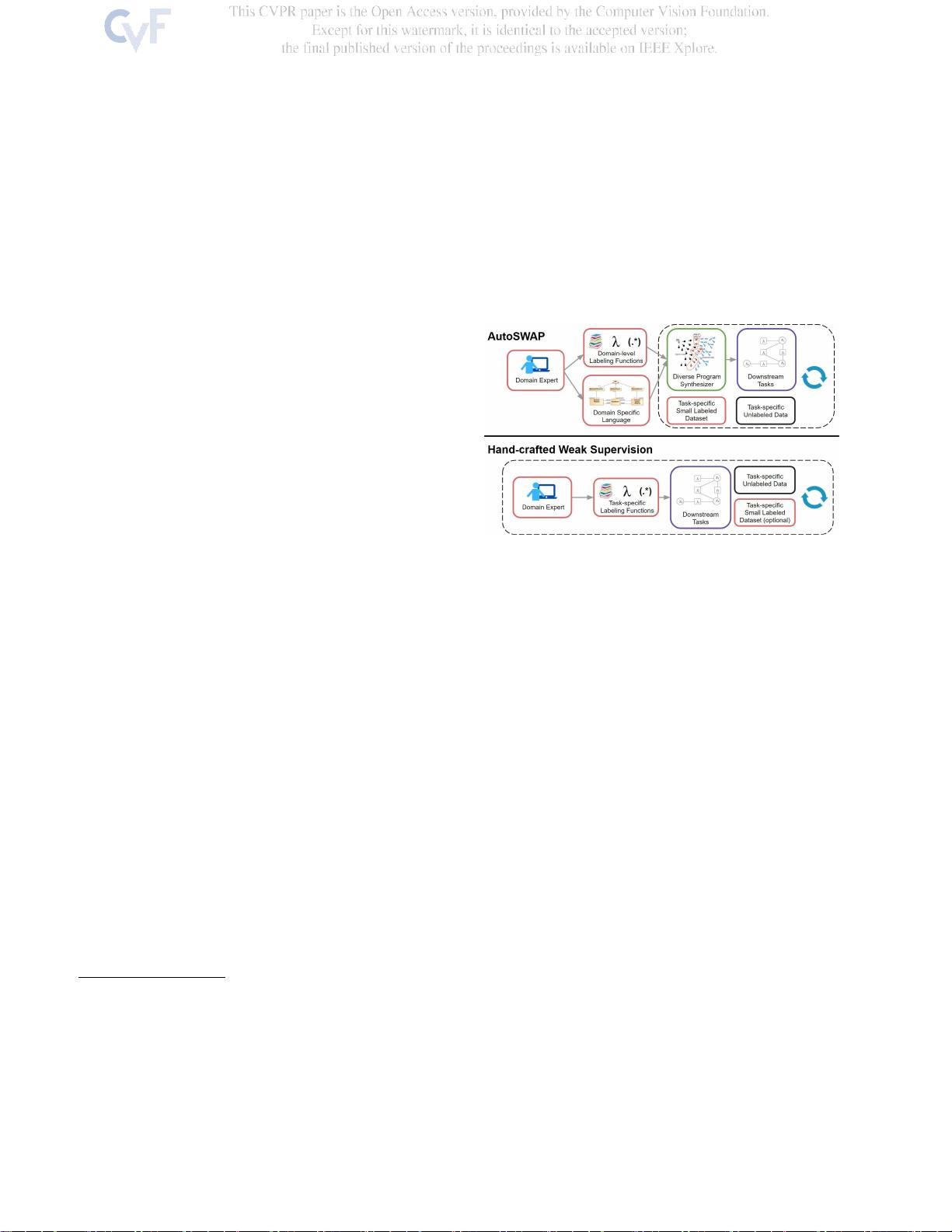
图
1.
我们提出了
AutoSWAP
,一个框架,用于自动合成不同
的
任务级
标签功能(
LF
)与一个小的标记数据集和领域知识
编码在
域级
LF和DSL。AutoSWAP通过自动化LF生成显著减
少了
虽然弱监督在广泛的环境中效果良好[4,10,23],
但尚未充分探索其用于组织或分析任务。首先,LF必
须提供
标签
而不是
特征
的要求阻止了更一般的领域知
识的使用[22](例如[14,24]中的行为特征)。此外,
新的LF必须由领域专家为新任务(例如要研究的新行
为)手工制作,限制了人工弱监督的可扩展性[33]。
为了应对这些挑战,我们研究了有效的领域知识表示
和开发自动化弱监督方法,以减少行为分析设置中的
注释瓶颈。
我们的方法。我们提出了AutoSWAP(自动S合成
WeA k SuP ervision),一个数据高效的框架,自动生
成任务级LF使用一种新的多样化的程序合成公式。如
图1所示,专家为给定域提供域特定语言(DSL)和域
级LF(特定于任务域的LF),例如鼠标行为或车辆运
动规划。对于该领域中要研究的每个任务,专家提供
一个小的标记数据集来指定任务,AutoSWAP返回一
组结构上不同的任务级LF,可以在弱监督框架中使
用。域级LF(图2)提供了良好的
下载后可阅读完整内容,剩余9页未读,立即下载
相关推荐





cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- WebDrive v16.00.4368: 简易易用的Windows风格FTP工具
- FirexKit:Python的FireX库组件
- Labview登录界面设计与主界面跳转实现指南
- ASP.NET JS引用管理器:解决重复问题
- HTML5 canvas绘图技术源代码下载
- 昆仑通态嵌入版ASD操舵仪软件应用解析
- JavaScript实现最小公倍数和最大公约数算法
- C++中实现XML操作类的方法与应用
- 设计编程工具集:材料重量快速计算指南
- Fancybox:Jquery图片轮播幻灯弹窗插件推荐
- Splunk Fitbit:全方位分析您的活动与睡眠数据
- Emoji表情编码资源及数据库查询实现
- JavaScript实现图片编辑:截取、旋转、缩放功能详解
- QNMS系统架构与应用实践
- 微软高薪面试题解析:通向世界500强的挑战
- 绿色全屏大气园林设计企业整站源码与多技术项目资源
