"基于视觉对话模型的心理记分研究:对话表示增量编码与共享知识"
PDF格式 | 1.17MB |
更新于2025-01-16
| 90 浏览量 | 举报

+v:mala2277获取更多论
文
视觉对话模型可以记分吗?探索对话表示如何增量编码共享知识
Brielen Madureira David Schlangen计算
语言学
德国波茨坦大学
{madureiralasota,david.schlangen}@ uni-potsdam.de
摘要
认知上合理的视觉对话模型应该在对话语
境中保持一个共享的既定事实的
心理记分
牌
我们提出了一种基于理论的评估方法,
用于调查在VisDial数据集上预训练的模型
在多大程度上逐步构建适当
记分
的代表。
我们的结论是,在分析的模型中,区分对
话中共享的和私下知道的陈述的能力是适
度的,但并不总是增量一致的,这可能部
分是由于在原始任务中对
基础交互的
1
介绍
“There’s 你在电话里对朋友说的“太好了。“狗
是什么颜色的?”他们说的 你回答从你第一次
说话开始,你就已经承诺了自己是一只狗;一
个你以后不能简单地忽略的承诺。语言学和心
理语言学的对话模型把这种基础或记分的过
程
--
使命题相互了解
-
在这篇简短的论文中,我们调查了最近的视
觉对话的
NLP
模型是否具体来说,我们使用
VisDial
数据集(
Daset al.
,
2017 a
),它由英
语对话组成,对话是关于类似于第一段中的非
对称设置中的图像,并从中得出诊断命题,这
些诊断命题应被视为对话中给定点处的相互知
识,以及在给定时间只有一个参与者知道其真
值的其他命题。然后,我们探测由在
VisDial
任务上预训练的模型构建的
2
相关文献
自 Vinyals and Le ( 2015 ) 、 Sor-doni et al.
(
2015
)和
Serban et al.
(
2016
)的工作以来,
将对话上下文隐式表示为以端到端方式训练的
神经网络的连续隐藏状态该范例还使得多模态
输入(如图像)能够被容易地集成(Shekhar
等人,,
2019 b
)。然而,有证据表明,在这
些模型中,人类的
协作基础
能力仍然缺乏,部
分原因是培训制度和数据集的限制(
Benotti
和
Blackburn,2021)。
我们见证了广泛的努力,看看这些模型如何
编码和利用对话历史,捕捉显着的信息,并产
生 视 觉 接 地 表 示 ( 桑 卡 尔 等 人 。 , 2019;
Agarwal et al. , 2020; Greco et al. , 2020a ,
b ) 。 对 当 前 对 话 模 型 的 分 析 和 评 估 ( 如
Hupkes et al.
(
2018 a
),
Shekhar et al.
(
2019
a
),
Parthasarathi et al.
(
2020
),
Saleh et al.
(
2020
),
Wu
和
Xiong
(
2020
)
等
)通常依赖
于诊断分类器(Hupkes et al. ,2018 b)和探
测任务(Belinkov和Glass,2019),这是检查
神经网络构建的表征是否编码语言信息的常用
工具。
另一个有目的的对话研究领域
Zhang
和
Chai
(2009,2010)讨论了
会话蕴涵
,
即
判断一个
会话话语是否蕴涵一个假设。在对话数据集中
注释或生成蕴涵、矛盾和中性陈述在最近的作
品中是常见的(
Welleck et al.
,
2019; Dogli et
al.
,
2019; Galetzka et al.
,
2021
年)。
从这三个支柱的见解,我们提出了一个探索
任务记分(刘易斯,1979年)的视觉对话,正
式在下一节。
3
问题陈述
基于这样一个前提,即人类保持着一个预先假
设的命题和每
-
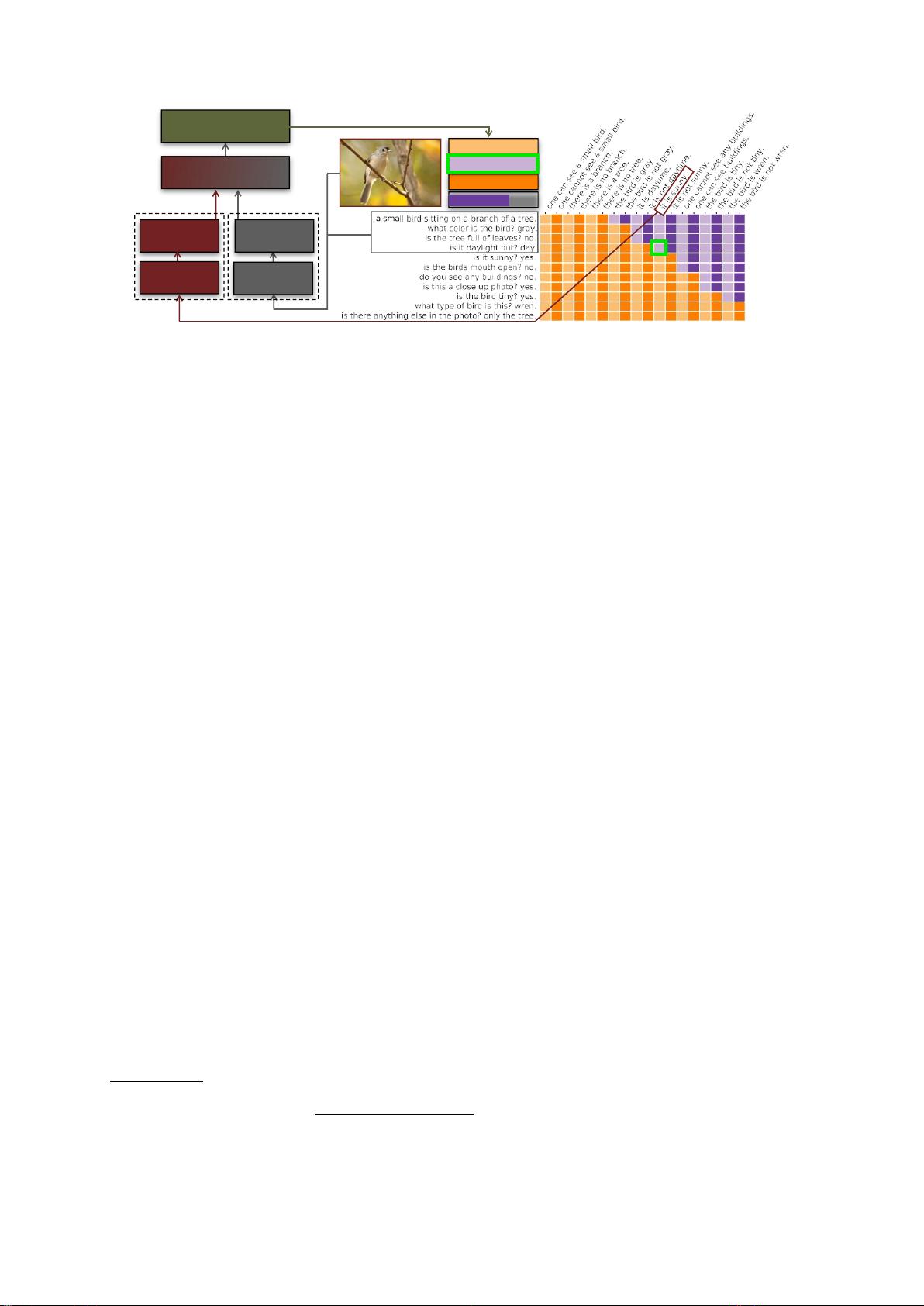

剩余14页未读,继续阅读
相关推荐





cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Saber仿真下的简化Buck环路分析与TDsa扫频
- Spring框架下使用FreeMarker发邮件实例解析
- Cocos2d捕鱼达人路线编辑器开发指南
- 深入解析CSS Flex布局与特性的应用
- 小学生加减法题库自动生成软件介绍
- JS颜色选择器示例:跨浏览器兼容性
- ios-fingerprinter:自动化匹配iOS配置文件与.p12证书
- 掌握移动Web前端高效开发技术要点
- 解决VS中OpenGL程序缺失GL/glut.h文件问题
- 快速掌握POI技术,轻松编辑Excel文件
- 实用ASCII码转换工具:轻松实现数制转换与查询
- Oracle ODBC补丁解决数据源配置问题
- C#集成连接器的开发与应用
- 电子书制作教程:你的文档整理助手
- OpenStack计费监控:使用collectd插件收集统计信息
- 深入理解SQL Server 2008 Reporting Services
