结直肠癌共有生物标志物及途径的生物信息学分析揭示286个重叠的差异表达基因
117 浏览量
更新于2025-01-16
收藏 2.39MB PDF 举报

医学信息学解锁20(2020)100376
结直肠癌共有的新生物标志物和途径的确定
通过全面的生物信息学分析,
Foyzur Rahman
a
,
*
,Mahmud王子
b
,Rezaul Karim
a
,Tofazzal Hossain
c
,
Farhadul Islam c
,
d
a
Khwaja Yunus Ali
大学生物医学学院生物化学和生物技术系,
Sirajganj
,
6751
,孟加拉国
b
Khwaja Yunus Ali
大学科学工程学院计算机科学与工程系,
Sirajganj
,
6751
,孟加拉国
c
Rajshahi
大学理学院生物化学和分子生物学系,
Rajshahi
,
6205
,孟加拉国
d
澳大利亚昆士兰州黄金海岸格里菲斯大学黄金海岸校区糖组学研究所,邮编
4222
A R T I C L E I N FO
关键词:
生物信
息学结直肠癌
差异表达基因子宫内膜癌
基因本体
A B S T R A C T
背景:子宫
内膜癌(Endometrial cancer,EC)是女性常见的生殖道恶性肿瘤,结直肠癌(colorectal cancer,
CRC)是其危险因素之一。然而,这两种疾病共有的共同基因和分子通路尚未确定。
目的:
在本研究中,我们的目的是揭示候选生物标志物和CRC和EC之间的分子相互作用,以了解共同的疾病机
制。
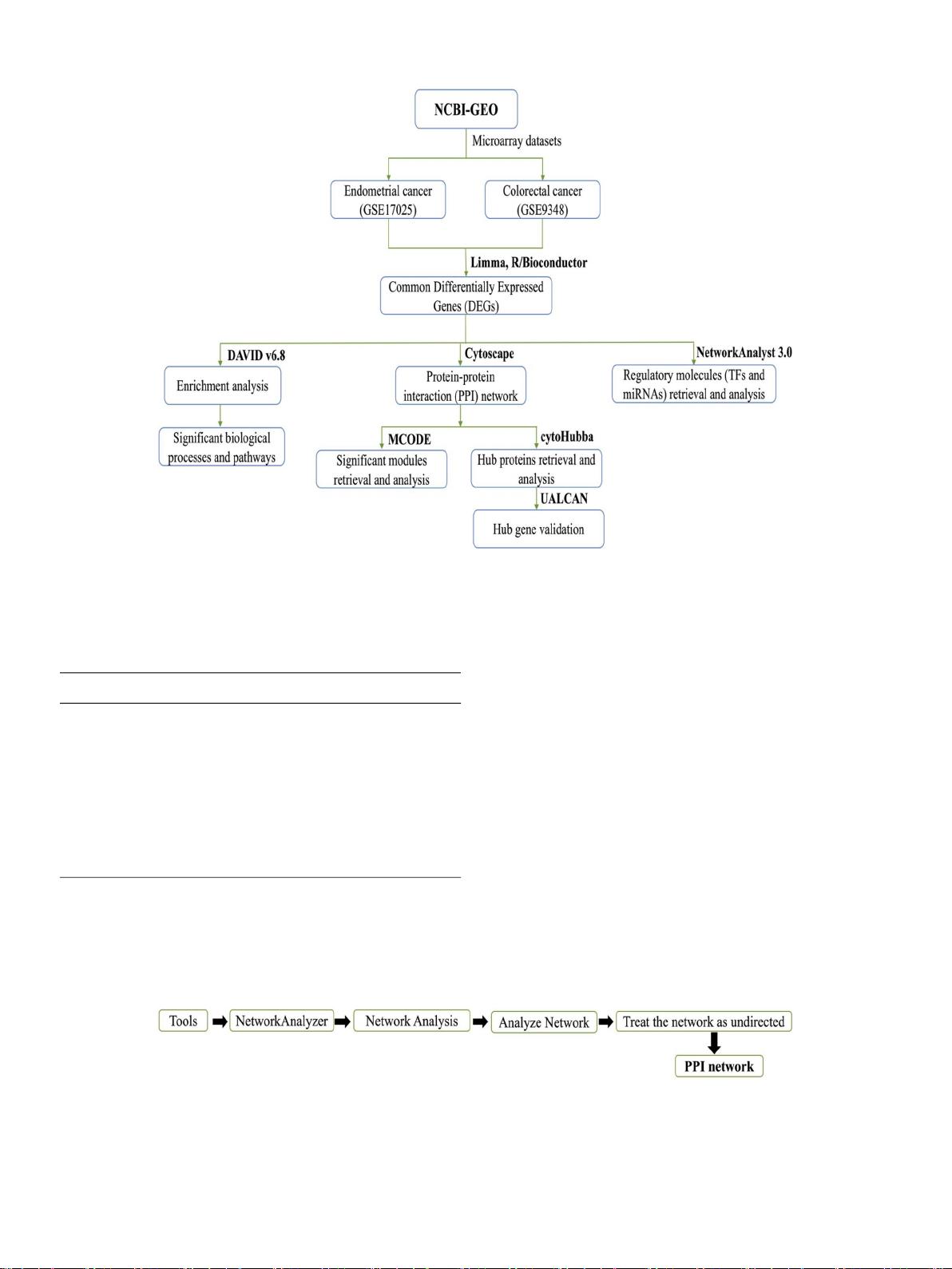
材料和方法:
我们进行了差异分析CRC和EC微阵列数据采用limma揭示差异表达基因(DEG)。然后,我们使用
这些疾病之间的相互DEG,通过富集分析获得重要的生物过程和途径。此外,为了揭示候选生物标志物和调控
转录物,我们使用生物信息学工具分析了不同的网络
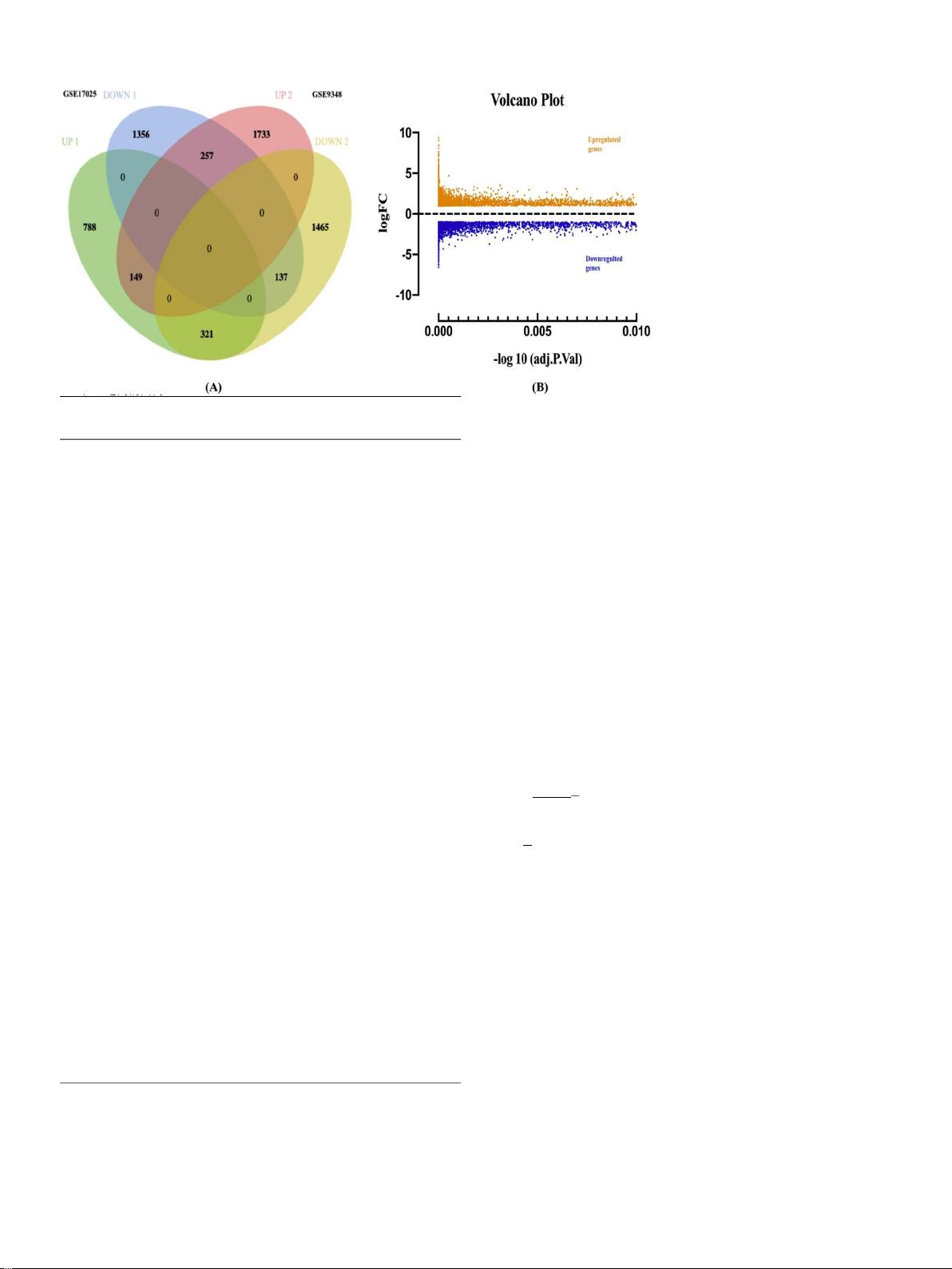
结果:
我们在CRC和EC转录组数据集之间确定了286个重叠的DEG。对这些异常表达基因的富集分析显示,它们
在癌症信 号传导途 径中显著 富集。 基于PPI网 络的拓扑 分析,我 们发现了 11个中 心蛋白, 包括JUN,MYC ,
FOS,EGR1,LEF1,CDC42,CTGF,ADAM 10,CYR61,FOXA 1和UBE 2I。我们还鉴定了7种重要的转录因子
(TF),即FOXC 1、GATA 2、YY 1、E2 F1、CREB 1、HINFP和FOXL 1,以及5种调节DEG表达的miRNA,包括
hsa-miR-124- 3 p、hsa-miR-106 b-5 p、hsa-miR-501- 3 p、hsa-miR-29 b-3 p和hsa-miR-145- 5 p。
结论:
我们已经确定了新的生物标志物和分子途径,共同的CRC和EC,这将有助于了解潜在的共同分子机制,
并开发潜在的治疗方法。
1.
介绍
子宫内膜癌(EC)发生在子宫内膜,是女性最致命的妇科癌症之
一,特别是那些处于绝经后阶段的女性。近年来,食管癌的发病率和死
亡率在世界范围内呈惊人的上升趋势。根据美国癌症协会(ACS)2019
年发布的最新统计数据,美国估计有61,880例新病例和约12,160例
死于EC,此外全球每年还有76,000例死亡。这些结果使该疾病在发达
国家(排名第四)和发展中国家(排名第二)的致命癌症中脱颖而出[1
肥胖、糖尿病、
雌激素水平,增生等,在女性中起关键作用[9此外,Brooks等报道结直
肠癌(CRC)在EC发病中起着至关重要的作用;因此,它可能被视为EC的
关键风险因素之一[12]。
结直肠癌影响人体的结肠和直肠,是世界研究表明,患有CRC的
女性可能在其一生中发生EC,这表明CRC是EC的主要危险因素之一
[12,15,16]。然而,据我们所知,潜在的分子机制,CRC如何影响
女性EC的发生和发展,尚未研究。因此,迫切需要鉴定CRC之间相互
的新生物标志物和共享途径。
* 通讯作者。
电子邮件地址:
gmail.com,foyzur_bcbt@kyau.edu.bd(法文)。Rahman)。
https://doi.org/10.1016/j.imu.2020.100376
接收日期:2020年3月17日;接收日期:2020年6月8日;接受日期:2020年
在线预订
2020
年
2352-9148/©
2020
的 自行 发表 通过 Elsevier 公司 这 是 一个 开放 接入 文章 下 的 CC
BY-NC-ND
许可证
(
http://creativecommons.org/licenses/by-nc-nd/4.0/
)中找到。
可在ScienceDirect上获得目录列表
医学信息学
期刊主页:http://www.elsevier.com/locate/imu

剩余15页未读,继续阅读
267 浏览量
108 浏览量
114 浏览量
322 浏览量
2022-12-15 上传
192 浏览量

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现ART与SART算法在医学CT重建中的应用
- S2SH整合版:快速搭建Struts2+Spring+Hibernate开发环境
- 托奇卡项目团队成员介绍
- 提升外链发布效率的SEO推广神器——搜易达网络推广大师v2.035
- C#打造简易记事本应用详细教程
- 探索虚拟现实地图VR的奥秘
- iOS模拟器屏幕截图新工具
- 深入解析JavaScript在生活应用开发中的运用
- STM32F10x函数库3.5中文版详解与应用
- 猎豹浏览器v6.0.114.13396 r1:安全防护与网购敢赔
- 掌握JS for循环输出的最简洁代码技巧
- Java入门教程:TranslationFileGenerator快速指南
- OpenDDS3.9源码解析及最新文档指南
- JavaScript提示框插件:鼠标滑过显示文章摘要
- MaskRCNN气球数据集:优质图像识别资源
- Laravel日志查看器:实现Apache多站点日志统一管理
