神经运动控制:基于物理模拟器的精确人体运动捕捉
PDF格式 | 4.08MB |
更新于2025-01-16
| 90 浏览量 | 举报

6417
Neural MoCon:用于物理上合理的人体运动捕捉的神经运动控制
王
步珍
*
中国东南大学
摘要
由于视觉模糊性,单目人体运动捕捉的纯运动学公
式通常在物理上是不正确的,生物力学上是不可信
的,并且不能重建精确的交互。在这项工作中,我们
专注于利用高精度和不可微的物理模拟器,将动态约
束的运动捕捉。我们的核心思想是使用真实的物理监
督训练的目标姿态分布之前,基于采样的运动控制,
以捕捉物理上合理的人体运动。为了获得精确的参考
运动与地形的交互采样,我们首先引入了一个基于
SDF
(有符号距离场)的交互约束,以执行适当的地
面接触建模。然后,我们设计了一种新的两分支解码
器,以避免来自伪地面实况的随机误差,并使用不可
微物理模拟器训练分布最后,我们从当前状态的物理
特征与训练的先验和样本满意的目标位姿回归的采样
分布,以跟踪估计的参考运动。定性和定量的结果表
明,我们可以得到物理上合理的人体运动与复杂的地
形相互作用,人体形状的变化,和多样化的生物。更
多 信 息 可 以 在
www.yangangwang.com/papers/HBZ-NM-2022-
03.html
上找到
1.
介绍
近年来,无标记运动捕捉技术得到了长足的发展,
其应用范围从角色动画到人机交互、个人健康和人类
行为理解等。大量现有的工作可以从单目运动学上捕
捉准确的人体姿势
*
通讯作者。电子邮箱:yangangwang@seu.edu.cn。这项工作得到
了中国国家重点研发计划基金2018YFB1403900、国家自然科学基金
(编 号 : 62076061)、 “ 中国 科 协 青年精 英 资 助 计划” (编号 :
YES20200025 ) 和 东 南 大 学 “ 至 善 青 年 学 者 ” 计 划 ( 编 号 :
2018YFB1403900)的部分支持。2242021R41083)。
图
1.
我们的方法通过神经运动控制从单目
RGB
视频中捕获物
理上合理的人体
通过网络回归的视频和图像[22,25,26,66,67]
或优化[6,38,41,51]。然而,由于一系列不满足生
物力学和物理可接受性的伪像(
例如
,抖动和地板穿
透)。
为了提高运动质量和物理可扩展性,一些工作集中
于使用基于物理的约束来捕获人体运动[42,46,47,
53,57]将物理定律作为软约束纳入数值优化框架并减
少伪影。为了使优化易于处理,他们只能采用简单和
可微的物理模型,这可能会导致很高的近似误差。其
他方法[40,60,63]利用具有深度强化学习(DRL)
的不可微物理模拟器然而,训练一个理想的策略需要
复杂的配置[1,5,31],并且它可能对环境变化敏感
[39,60]。上述限制使得它们不可行的估计与场景交
互的人体姿势然而,运动控制,通常是基于采样的方
法[35],在再现高度动态和杂技运动方面取得了令人
印象深刻的性能,并且对接触丰富的场景具有鲁棒
性,这为基于一般物理的运动捕捉提供了一种方法。
在本文中,我们的目标是构建一个基于物理的运动

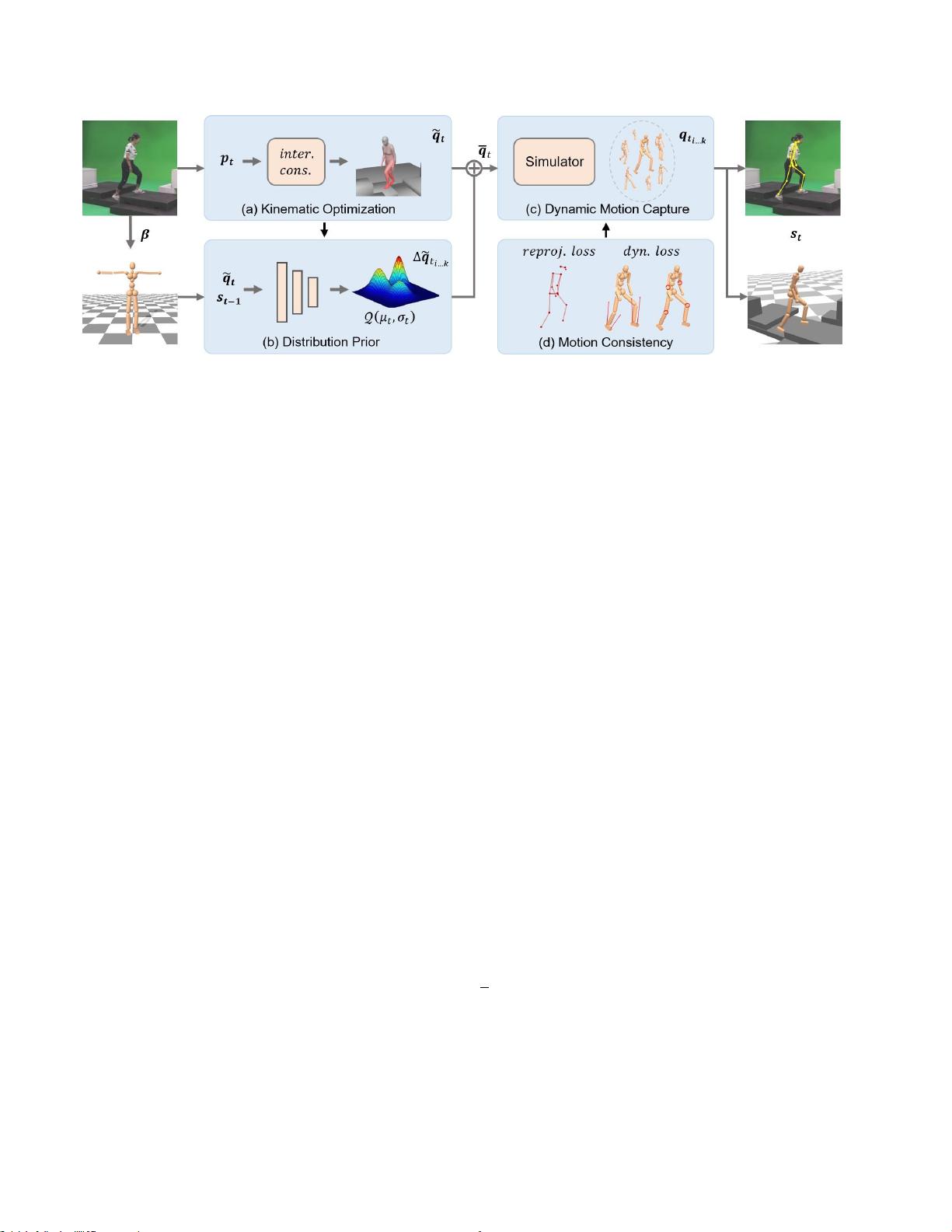
剩余11页未读,继续阅读
相关推荐





cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全面详实的大学生电工实习报告汇总
- 利用极光推送实现App间的消息传递
- 基于JavaScript的节点天气网站开发教程
- 三星贴片机1+1SMT制程方案详细介绍
- PCA与SVM结合的机器学习分类方法
- 钱能版C++课后习题完整答案解析
- 拼音检索ListView:实现快速拼音排序功能
- 手机mp3音量提升神器:mp3Trim使用指南
- 《自动控制原理第二版》习题答案解析
- 广西移动数据库脚本文件详解
- 谭浩强C语言与C++教材PDF版下载
- 汽车电器及电子技术实验操作手册下载
- 2008通信定额概预算教程:快速入门指南
- 流行的表情打分评论特效:实现QQ风格互动
- 使用Winform实现GDI+图像处理与鼠标交互
- Python环境配置教程:安装Tkinter和TTk
