无监督3D点云去噪:空间先验驱动的完全噪声清除
164 浏览量
更新于2025-01-16
收藏 1.25MB PDF 举报
本文探讨了3D点云的完全去噪问题,一项创新的研究工作由乌尔姆大学和伦敦大学学院的蒂莫·罗平斯基教授团队进行。他们提出了一种无监督学习方法,旨在从原始的、充满噪声的3D点云数据中自动学习去噪过程,无需依赖噪声和干净数据对的监督。传统的无监督图像去噪技术基于像素值的随机噪声假设,但这在非结构化的3D点云上并不适用,因为3D点云的噪声是全面的,包括坐标偏移,没有像像素网格那样的结构。
传统上,处理3D点云的噪声是具有挑战性的,因为它涉及到空间范围和属性(如坐标)的双重噪声影响。作者将这种噪声称为“总噪声”,借鉴了线性非深度设置下的总最小二乘法概念。然而,他们发现现有的深度学习应用于3D点云和无监督图像去噪技术无法直接融合,因为这两种方法的适用场景不同。
为了解决这个问题,研究人员引入了一个空间先验项,这个先验项能够引导学习过程向最接近的噪声模式收敛,从而避开多个可能的噪声模式。他们的研究结果显示,在有足够的训练样本时,无监督去噪的效果可以与有监督学习在干净数据上的表现相当,即使只使用噪声数据也能实现点云的清洗。
文章的核心贡献在于提出了一种新的无监督学习策略,它能够在不依赖于噪声和干净样本对的前提下,有效地去噪3D点云。这对于日益增长的3D扫描数据处理具有重要意义,例如城市街景、建筑物内部和商品扫描,它们往往受到各种噪声的影响,而这种方法提供了一种新的可能性,使得数据预处理更加自动化和高效。这项研究为3D点云的处理和分析领域开辟了新的研究方向。
54
y
z
X
域
p
(z|)
的方
式
y
域
域
J
S
S
YX
J
YY
i-1
ii+1
b
)
c
)
q(z|y)
y
X
观察其他像素
观察
唯一模式
曲面
像素
分布
域
非唯一模式
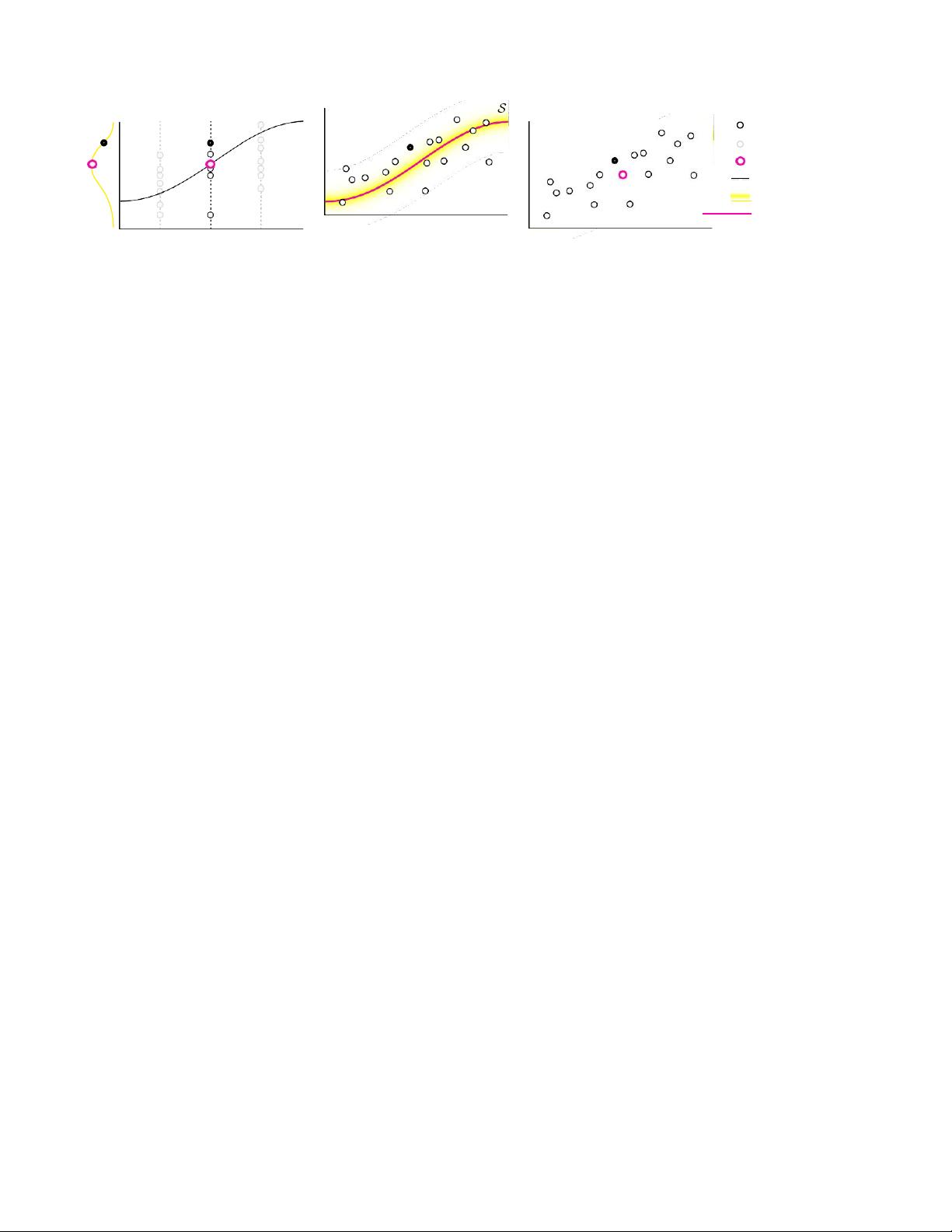
图3.在对结构化和非结构化数据进行去噪时存在实质性差异。
(
a
)
对于结构化数据,每个像素值遵循
采样分布
p
(
z
|
x
i
)(
黄
色曲线
)围绕真实值(粉色圆圈)。
(
b
)
对于非结构化数据,分布p(z| S)有一
个模式的流形(
粉红线
)。
(
c
)
通过使用所
提出的邻近外观先验,确定最接近表面的唯一模式
这里,
f
是一种特殊形式的-不完全[2]映射,当对像素i
进行回 归时 , f无法 访问 像素 i 。例如,“盲点” 。与
Noise 2Noise中相同的均值/中值/众数和损失之间的关
系也注意,该公式不需要两个图像,因此我们将其称
为
讨论上述所有三种方法都在以下假设下工作:在结构
化像素网格中,范围(图1B中的垂直轴)在图1B中的
垂直轴上。2,左和图。a)轴i和主z(水平轴)具有不
同的语义。噪声仅在该范围内:不确定像素
的
位置,
仅确定其真实
值
。
3.2.
非结构域
点噪声。 至于像素,我们将表示干净点 作为
x
,噪
声点作为
y
,噪声模型作为p。 我们推导中的所有点都
可以是XYZ坐标的位置,也可以是外观的位置,表示
为XYZRGB点。
据我们所知,尚未提出彩色点云的深度去噪。我们
不仅将展示我们的技术如何应用于此类数据,而且还
将展示颜色如何在训练点云去噪器的无监督学习时令
人惊讶的是,即使在测试时不存在颜色,也可以在训
练期间利用这种益处。如果可用,它将有所帮助,我
们还可以联合对位置和外观进行
监督。 点云降噪意味着学习
arg min E
y
p
(
z
| S
)
l
(
f
Θ
(y)
,
)
,
Θ
损失的总和L(e.例如,在一个实施例中,倒角)。已
经提出了这样的监督方法,但它们仍然受到可用训练
数据量的限制[22,20],因为它们需要访问干净的点
云。
4.
无监督三维点云去噪
我们将首先描述为什么配对方法不适用于非结构化
数据,然后再介绍我们的非配对,无监督方法。
4.1. “配对”方法的不适用性
学习从一个噪声点云实现
Y1
到另一个噪声点云实
现
2
的
映射
f
Θ
(
Y1
)
=
Y2
其中两个点云中的第i
个
点是实现 的第i
个
地面真值,
将是 Noise2Noise [17]意义上的 降噪 器 。 遗憾 的是,
Noise2Noise不能应用于非结构化点云的无监督学习,
原因有二。
首先,与图像相同的这种配对设计将需要以被不同
噪声实现破坏的相同点云的两个实现的形式的监督虽
然这对于2D图像传感器已经很难实现,但对于3D扫描
仪来说是不可行的。
第二,这将需要网络架构来知道哪个点是哪个点,
类似于由明确编码每个像素的身份i的图像的规则结构
给出的对于以点为单位的总噪声,情况永远不是这
样。与此相反,现代卷积深度点处理[19,12]正是关
于在点的重新排序下变得不变。
为了克服这个问题,在监督设置,Rakotosaona等
人。[20]通过为每个噪声观测选择干净点云中的最近
点作为损失的目标来模拟这种配对。然而,这仅仅是
真实表面的近似,其精度取决于干净数据的采样质
量。幸运的是,我们可以证明不需要配对假设,使得
我们的方法不仅在无监督的情况下操作,而且在无配
对的情况下操作,如我们接下来将详细描述的。
4.2.
未配对
学习从噪声实现到其自身的映射
f
Θ
(
)
=
在
Noise2Void [15]或Noise2Self [2]的意义上是无监督和未
配对的去噪器。定义点云中的不完整性并不困难:只
需防止
a
)
、
p
(y|x
)
范围
域
剩余10页未读,继续阅读
283 浏览量
358 浏览量
2090 浏览量
183 浏览量
378 浏览量
216 浏览量
2024-10-28 上传
128 浏览量
455 浏览量

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- C#实现程序A的监控启动机制
- Delphi与C#交互加密解密技术实现与源码分析
- 高效财务发票管理软件
- VC6.0编程实现删除磁盘空白文件夹工具
- w5x00-master.zip压缩包解析:W5200/W5500系列Linux驱动程序
- 数字通信经典教材第五版及其答案分享
- Extjs多表头设计与实现技巧
- VBA压缩包子技术未来展望
- 精选多类型导航菜单,总有您钟爱的一款
- 局域网聊天新途径:Android平台UDP技术实现
- 深入浅出神经网络模式识别与实践教程
- Junit测试实例分享:纯Java与SSH框架案例
- jquery xslider插件实现图片的流畅自动及按钮控制滚动
- MVC架构下的图书馆管理系统开发指南
- 里昂理工学院RecruteSup项目:第5年实践与Java技术整合
- iOS 13.2真机调试包使用指南及安装
