无监督玻尔兹曼机驱动的时间感知推荐系统:革新内容推荐
PDF格式 | 1.57MB |
更新于2025-01-16
| 119 浏览量 | 举报
本文主要探讨的是"基于无监督玻尔兹曼机的时间感知推荐系统"(UBMTR),这是一项创新性的研究,发表在沙特国王大学学报上,由Harshvardhan先生、Mahendra Kumar Gourisaria、Siddharth Swarup Rautaray和Manjusha Pandey等学者共同贡献。在计算机工程学院,位于印度奥里萨邦的KIIT大学背景下,研究团队针对当前社会中视觉媒体广泛使用的现状,提出了一种新颖的推荐系统方法。
传统的推荐系统通常依赖于协同过滤、关联规则学习或基于内容的过滤等技术。然而,UBMTR引入了玻尔兹曼机这一强大的机器学习工具,特别是无监督的形式,以捕捉用户对内容的喜好与时间因素之间的潜在关系。在实际应用中,受限玻尔兹曼机(RBM)以其在特征提取、神经成像、目标识别等领域中的表现,被用于解决复杂问题。
UBMTR模型将用户对电影的评级和时间信息作为双重输入,通过蒙特卡罗采样算法结合对比发散计算,生成二进制值,以预测用户可能的兴趣变化。这种方法特别适合处理时间敏感的推荐场景,因为它们考虑了内容的接收时间。相比于仅依赖协同过滤(CF)或深度学习模型,UBMTR的优势在于其能够利用RBM处理不平衡数据集和非结构化数据的能力,以及有效地填充缺失值,从而提高推荐的准确性。
值得注意的是,虽然玻尔兹曼机在推荐系统的应用相对较少,但UBMTR的研究填补了这一领域的空白。论文指出,许多现有工作并未充分整合时间信息,这使得UBMTR成为一个具有前瞻性和实用价值的研究成果。此外,该研究遵循CC BY-NC-ND许可证,意味着作者的原创内容可以被广泛分享和引用,但需注明版权和限制商业用途。
UBMTR展示了如何将无监督玻尔兹曼机与时间感知相结合,以提升推荐系统的性能,尤其是在处理动态变化的用户行为时。这项研究对于推动个性化推荐系统的未来发展具有重要意义,特别是在多媒体内容推荐领域。
GM Harshvardhan
等
.
沙特国王大学学报
6402
1/4
f
g
⊂
)
f
m m m
m
喜欢
)
f
g
喜欢
)
f
g
我
J
N
m
i
)
f
g
N
图二
.
(
Yang
等人,基于时间感知
CNN
的个性化推荐(
TC-PR
)与其他推荐方法的性
能。
Salakhutdinov等人(2007)使用RBM进行协同过滤,并且使用相同的
模型,Liu等人(2015)将项目类别信息纳入RBM的条件层中,以基本
上建立
项目类别感知
模型。同样,Xie等人(2016)认为,传统的CF方
法没有考虑人口的生命统计数据(年龄,职业,性别等),因此,他们
提出了一种RBM模型,该模型具有额外的层来处理占用信息并实现
用户
占用感知
模型。
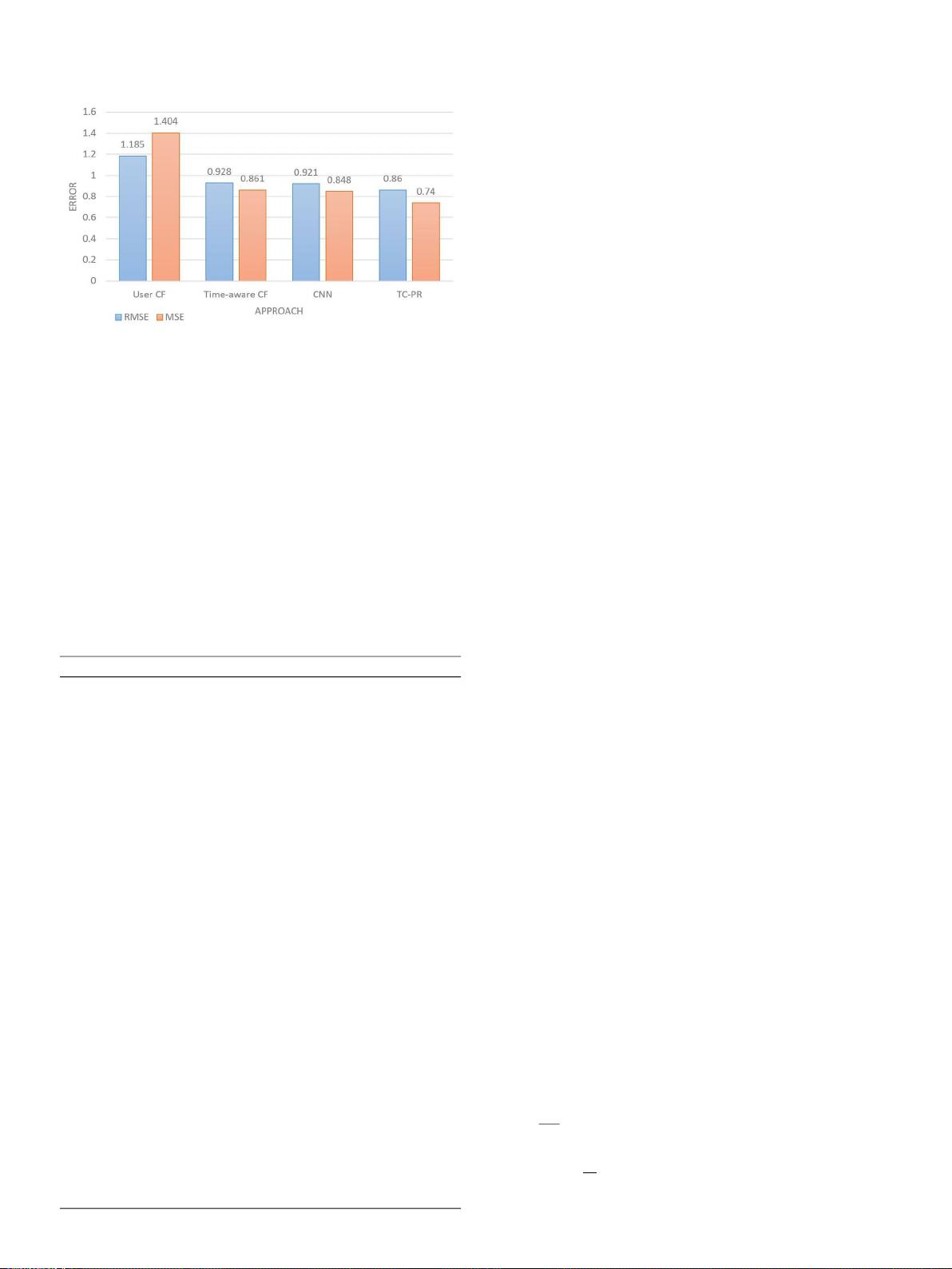
在基于时间感知卷积神经网络的推荐系统中,
Yang
等人进行了最
全面的尝试。(
2019
),他通过考虑时间数据来关注用户个性化推
荐,这些时间数据在
MSE
(均方误差)和
RMSE
(均方根误差)方
面 超 过 了 大 多 数 其 他 推 荐 算 法 (
User CF
,
time-aware-CF
,
CNN
)(图
1
)。
2
)的情况。
表1
所有相关工作的总结。
斯诺
工作参考
所有相关工作的摘要见表1。
我们注意到,在通过使用无监督深度学习技术(或无向神经网
络)实现时间感知推荐系统方面几乎没有任何工作,这正是我们在本
文中尝试的。
4.
背景
在本节中,我们首先在
4.1
小节中描述推荐系统的不同类别,然后
我们继续到
4.2
小节并介绍玻尔兹曼机和所有相关术语。本节可以被
认为是初步的。
4.1.
推荐系统
推荐系统的两大类是透明推荐方法和更流行的深度学习方法。传
统的推荐系统包括基于关联规则的推荐算法、基于内容的推荐算法、
协同过滤算法和混合推荐算法。
基于内容的推荐系统
:基于内容的推荐系统背后的概念围绕着创
建项目配置文件和找到用户可能喜欢的共同方面。假设一组项目被定
义为
I i
1
;
i
2
;
i
3
;
.
我,
这些物品中的每一个都将有一个关于物品拥有的特
征的物品简介
例如,电影最后一步是推荐最符合该用户配置文件的项目。
基于关联规则的推荐系统:
基于关联规则的学习的两个主要类别
是
Apriori
和
Eclat
算法。我们从
Apriori
开始,它可以被最好地描述
为
“
买
x
的人也买
y”
。
. ” or ‘‘
1.
(
Levandos
ki
等人,
2012
年)
2.
(Noulas等
人, 2012
年)
使用基于位置的评级来产生建议。
提出了一种基于用户位置图的个性化随机游走模
型,用于改进基于位置服务网络(LBSN)的位置推
荐。
即U和M分别包括n
个
用户和m
部
电影,如U
^f
u
1
;
u
2
;
···
;
u
n
g
和
M
^f
m
1
;
m
2
;
···
;
m
n
g
。假设我们
有这样的数
据:
喜欢
11
;
二
、
3
;
4
喜欢
3.
(Wang等
人,
2013
年度)
利用LBSN用户签入的独特属性
位置建议的数据。
u
2
m
1
;
m
2
喜欢
u
4.
(Li等人, 2017) 提出时间感知产品推荐
模型通过利用网络表示学习技术使用产品图嵌入模
型。
3
)
fm
1
;
m
2
;
m
4
g
u
4
m
1
;
m
2
喜欢
u
5.
(张和
Chow,2016年)
6.
(
Yuan
等
人,
2013
年
度)
提出了一个概率框架,
时间影响相关性(TIC)来布局时间感知位置推
荐。
使用时间感知的兴趣点框架进行位置推荐。
5
)
fm
2
;
m
4
g
u
6
m
1
;
m
3
我们可以制定以下潜在规则:
m
1
?
m
2
m
2
?
M
4
7.
(
Wu
等人,(
2016
年) 使用
RNN
跟踪当前用户浏览数据,
电子商务系统。
m
1
?
M
3
8.
(Campos等
人, 2013年
度)
9.
(
Georgiev
和
Nakov
,
2013
)
10.
(萨拉胡季诺夫
例如,(
2007
年)
列出了一个详尽的分类国家的最先进的时间感知推荐
系统,并提供了评估这些系统的指导方针将RBM用
于CF并对用户-用户和项目-项目评级进行建模。
使用
RBM
实现
CF
,通过具有高斯隐藏单元的
RBM
和条
件
RBM
来优于奇异值分解(
SVD
)模型。
这里,潜在规则意味着如果用户u喜欢m
1
,则他们也可能喜欢m
2
,并
且对于其他两个规则类似,这是如何在最频繁使用或一起购买的物品之
间创建关联规则。Apriori算法有三个组成部分:
支持度
S
、置信度
C和
提
升度
L。 在我们的例子中,这些可以计算如下:
11.
(Liu等人,2015) 实现项目类别感知条件
成果管理制模式。
12.
(Xie等人,(2016年) 利用人口统计数据的职业,
使用成果管理制的用户进行推荐。
S
m
i
N
m
i
;
1
N
m m
13.
(
Yang
等
人,
2019
年
实现基于时间感知CNN的个性化
推荐系统
C
.
m
!
m
m
i
;
j
;
102
u
G
剩余13页未读,继续阅读
相关推荐





cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机组成原理期末试题及答案(2011参考)
- 均值漂移算法深入解析及实践应用
- 掌握npm与yarn在React和pg库中的使用
- C++开发学生信息管理系统实现多功能查询
- 深入解析SIMATIC NET OPC服务器与PLC的S7连接技术
- 离心式水泵原理与Matlab仿真教程
- 实现JS星级评论打分与滑动提示效果
- VB.NET图书馆管理系统源码及程序发布
- C#实现程序A监控与自动启动机制
- 构建简易Android拨号功能的应用开发教程
- HTML技术在在线杂志中的应用
- 网页开发中的实用树形菜单插件应用
- 高压水清洗技术在储罐维修中的关键应用
- 流量计校正方法及操作指南
- WinCE系统下SD卡磁盘性能测试工具及代码解析
- ASP.NET学生管理系统的源码与数据库教程
