Transformer与CNN结合的高保真多元图像补全技术
PDF格式 | 2.16MB |
更新于2025-01-16
| 24 浏览量 | 举报
"多元图像的高保真补全方法"
这篇研究论文主要关注的是利用深度学习技术,特别是结合卷积神经网络(CNN)和Transformer架构,来实现多元图像的高保真补全。图像完成,或者叫做图像修复,是计算机视觉领域中的一个重要任务,其目标是填补图像中的缺失部分,使之看起来既真实又具有语义合理性。这个任务广泛应用于对象移除、照片恢复、图像编辑和重定位等场景。
传统的图像修复方法,如PatchMatch,依赖于在图像内部寻找相似的块并复制到缺失区域,这种方法对于输入图像中必须包含类似结构或元素的情况效果有限。随着深度学习的发展,尤其是CNN的引入,图像修复技术取得了显著的进步。CNN能够学习大量的纹理模式,并用这些模式来填充丢失的区域,同时因为其稀疏连接性,计算效率较高。
然而,CNN存在两个主要限制。首先,其局部归纳先验导致它在理解图像全局结构时面临困难;其次,CNN的空间不变性意味着相同的滤波器在不同位置应用,无法捕捉空间变化的细节。为了克服这些局限,论文提出了一种新的方法,结合Transformer的全局关系建模能力和CNN的纹理补充能力。
Transformer以其对长期依赖性的出色建模,可以恢复多元图像的连贯结构,并初步填充纹理。接着,CNN用于精细化这部分粗略的先验,特别是在高分辨率掩模图像引导下增强局部纹理。这种方法不仅提升了图像的保真度,而且在处理大规模掩模和通用数据集,如ImageNet时,表现出了强大的泛化能力。
实验结果显示,该方法在图像保真度上超越了现有的确定性和多样化的图像完成方法,尤其在处理大面积缺失和跨类别场景时,其性能优势更加明显。论文的代码和预训练模型已在GitHub上公开发布,供研究者和开发者使用。
总结来说,这项工作创新性地融合了Transformer和CNN的优势,为图像修复提供了更高质量的解决方案,特别是在处理复杂和多变的图像缺失问题上。这不仅推动了技术的发展,也为实际应用,如图像编辑和恢复,提供了更强大的工具。
4694
N
∈
∈
|
|
|
×
×
×
|
|
−
代币嵌
入
Transformer
层
...
Transformer
层
FC
层
Softmax
Gibbs抽样
...
...
...
引导上采样网络
:[面具]
:
位置编码
:逐元素加法:离散化
:
双线性上采样
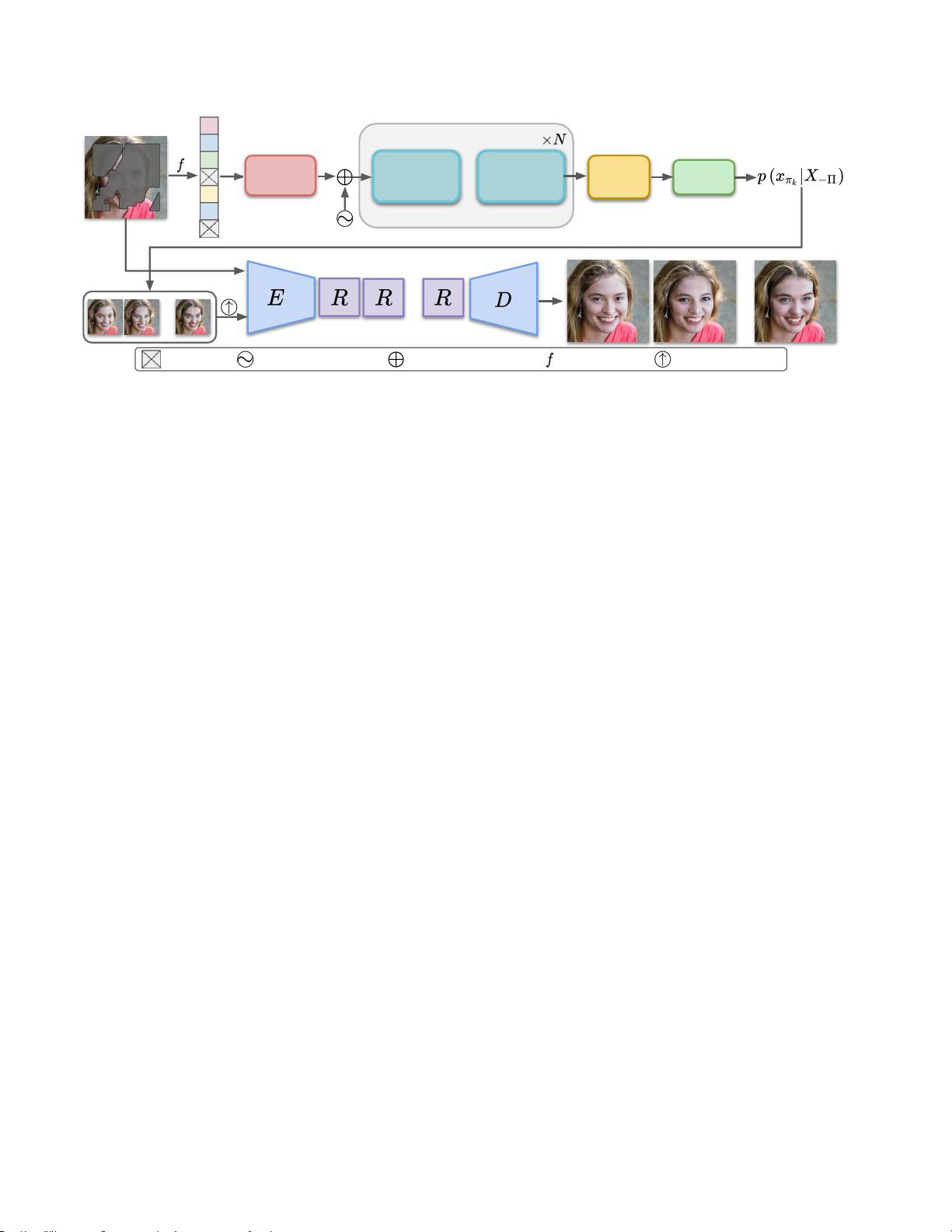
图2:管道概述。 我们的方法包括两个网络。第一个是双向Transformer,它负责产生缺失区域的概率分布,然后
从这个分布中进行多样性采样随后,我们采用另一个CNN在输入掩码图像的指导下在原始分辨率之前对外观进行
上采样我们的方法结合了Transformer和CNN的优点E:编码器,D:解码器,R:残差块。
通过联合最大化下界,从重构路径和生成路径的条件
先验中提取匹配分布。与[41]类似,UCTGAN [39]通
过优化编码特征和(0
,
I)分布之间的KL散度将掩蔽
的输入和参考图像投影到公共空间中,以实现多样化
的采样。虽然他们在一定程度上取得了一定的多样
性,但他们的完成质量是有限的,由于变化的训练。
与这些方法不同的是,我们直接优化的对数似然在离
散空间中,通过变换器没有辅助假设。
3.
方法
图像补全的目的是将具有缺失像素的输入图像
Im
R
H×W ×
3
变换为完整的图像I
R
H×W ×
3
。该任务本
质上是随机的,这意味着给定掩蔽图像I
m
,存在
条件分布p(I I
m
)。由于在给定I和I
m
的情况下获
得粗略先验X是确定性的,则p(I I
m
)可以重写
为,
p
(
I
|
I
m
)=
p
(
I
|
I
m
)
·
p
(
X
|
I
,
I
m
)
像素,表示为
p
(
I X
,
I
m
)(在第
2
节中描述)。
3.2
)。总体管线如图所示二、
3.1.
外观先验重建
离散化考虑到变换器架构中多头注意力[33]的计算成
本呈二次增加,我们用其对应的低分辨率版本(在我
们的实现中为
32 32
或
48 48
)表示自然图像的外观先验
然而,RGB像素的维数(
2563
)仍然太大.为了进一步降
低维度并忠实地重新表示低分辨率图像,使用整个
ImageNet [8]像素空间的K-Means聚类中心生成空间大
小为
512_3
的额外视觉词汇表然后,对于每个像素的外
观先验,我们从视觉词汇表中搜索最近的元素的索
引,以获得其离散表示。此外,表示序列中与孔洞区
域相对应的元素将被替换为一个特殊的令牌[MASK],
这也是为此,我们将-
=
p
(
X
,
I
|
I
m
)
=
p
(
X
|
I
m
)
·
p
(
I
|
X
,
I
m
)
。
(一)
将先前的外观转换为离散序列。
Transformer 对于离散化序列
X
={x
1
,
x
2
,
· · ·
,
x
L
},其中L是X的长度,
代替直接从p(I I
m
)采样,我们首先使用Transformer
来对给定I
m
的出现先验的底层分布建模,表示为p(X
I
m
)(在第2节中描述)。第3.1节)。这些重建的外观
先验包含大量的线索的全球结构和粗糙的纹理,由于
Transformer的强大的表示能力。随后,我们采用另一
个CNN补充纹理细节的指导下,外观先验和unmasked
我们通过前置可学习的嵌入将其投影到D维特征向量
中。为了对空间信息进行编码,额外的可学习位置嵌
入将被添加到每个位置
1≤
i
≤L
的令牌特征中
以形成Transformer模型的最终输入E∈
RL×d
遵循GPT-2 [28],我们使用仅解码器Transformer作
为我们的网络架构,它主要由N个基于自注意力的转
换器层组成在每一个跨-
剩余10页未读,继续阅读
相关推荐





cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 普天身份证阅读器新版二次开发包发布
- C# 实现文件的数据库保存与导出操作
- CkEditor增强功能:轻松实现图片上传
- 掌握DLL注入技术:测试工具使用与探索
- 实现带节假日农历功能的jQuery日历选择器
- Spring循环依赖示例:深入理解与Git代码仓库实践
- ABB PLC液压阀门控制程序开发指南
- 揭秘4核旋风密版626象棋引擎的超牛实力
- HTML5实现的经典游戏:小霸王坦克大战源码分享
- 让Visual Studio兼容APM硬件信息的方法
- Kotlin入门:创建我的第一个应用
- Android语音识别技术研究报告与应用分析
- 掌握JavaScript基础:第8版教程源代码解析
- jQuery制作动态侧面浮动图片广告特效教程
- Android PinView仿支付宝密码输入框源码分析
- HTML5 Canvas制作的围住神经猫游戏源码分享
