深度强化学习的人员重新识别方法
PDF格式 | 722KB |
更新于2025-01-16
| 169 浏览量 | 举报

6122
† ‡
§
†‡
深度强化主动学习用于人在环人员重
新识别
⋆ ⋆
刘子墨 王静雅 ,龚绍刚,胡川路 *,陶大成
†大连理工大学,‡UBTECH Sydney AI Center,The University of Sydney,§伦敦玛丽女王大学
lzm920316@gmail.com
,
jingya.wang @ sydney.edu.au
,
s.gong@wwwqmul.ac.uk example.com
,
wwwlhchuan@dlut.edu.cn. com
,
dacheng.tao@wwwsydney.edu.au
摘要
大多数现有的人员重新识别(
Re-ID
)方法基于大量
预先标记的数据通常是可用的并且可以一次全部放入
训练短语的假设来实现优异的然而,这种假设并不适
用于
Re-ID
任务的大多数实际部署。在这项工作中,我
们提出了一种基于强化学习的人在环模型,它释放了
预标记的限制,并通过逐步收集的数据保持模型升
级。目标是最大限度地减少人工注释工作,同时最大
限度地提高
Re-ID
性能。它通过交替地细化
RL
策略和
CNN
参数来在迭代更新框架中工作。特别是,我们制
定了一个深度强化主动学习(
DRAL
)方法,以指导代
理(强化学习过程中的模型)在选择训练样本的飞行
由人类用户
/
注释器。强化学习奖励是每个人类选择样
本的不确定性值。由人类注释者标记的二进制反馈
(正或负)用于选择样本,该样本用于微调预训练的
CNN Re-ID
模型。大量的实验表明,与现有的无监督
和迁移学习模型以及主动学习模型相比,我们的
DRAL
方法对于基于深度强化学习的人在回路中的人
Re-ID
的
优越性。
1.
介绍
人员重新识别(Re-ID)是在分布在不同位置的非
重叠相机视图上匹配人员的问题大多数现有的有监督
人Re-ID方法采用一次训练和部署方案,即手动收集和
注释成对训练数据
* 通讯作者
同等贡献
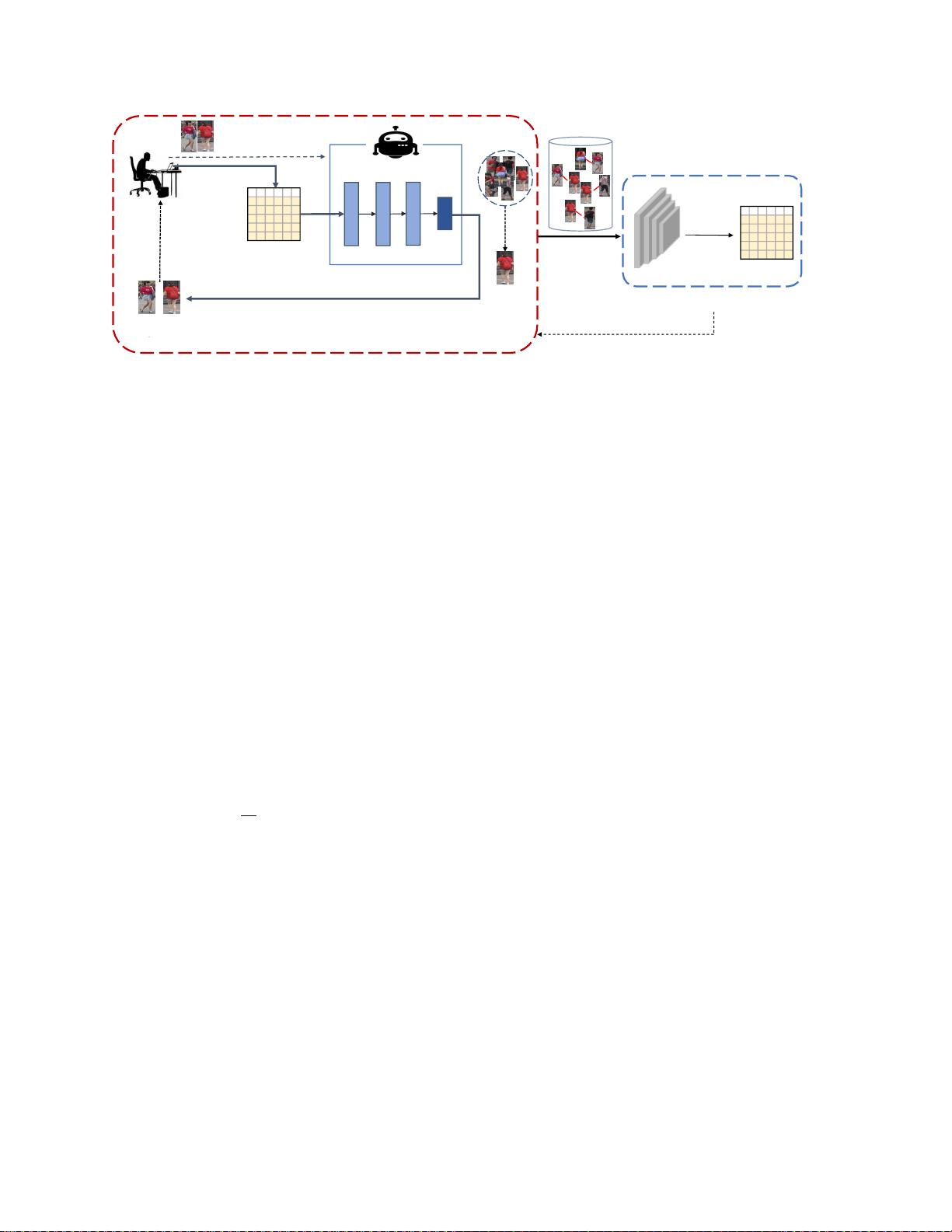
人类注释器
图1:深度强化主动学习(DRAL)的示意图。对于每
个查询锚(探针),代理(强化主动学习器)将在主
动学习过程中从图库池中选择顺序实例以用于具有二
元反馈(正/负)的人工注释
在学习一个模型之前,基于这一假设,监督Re-ID方法
近年来在几个基准上取得了进展[21,56,35,52,
25]。
然而,在实践中,由于以下几个原因,这种假设并
不容易适应:首先,成对的行人数据是禁止收集的,
因为它是不可能的,大量的行人可能会重新出现在其
他相机视图。其次,摄像机视图数量的增加加大了在
多个摄像机视图中搜索同一个人的难度。为了解决这
些困难,一个解决方案是设计无监督学习算法。一些
工作开始关注无监督Re-ID的迁移学习或域自适应技术
[11,44,28]。然而,与基于监督学习的模型相比,
基于无监督学习的Re-ID模型本质上较弱,从而在任何
实际部署中损害了Re-ID的有效性。
另一种可能的解决方案是遵循半监督学习方案,该
方案降低了对数据注释的要求。成功的研究已经完成
了基于词典学习[27]或自定进度学习[14]的方法。这些
模型仍然基于一个强烈的假设,即身份的一部分(例
如,的三分之一
动作
A
t
国家
奖励
剂
查询
锚
S
t
$
t
$
t%&
S
t%&
无标号图库库
标签查询

剩余10页未读,继续阅读
相关推荐




cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入解析JavaWeb中Servlet、Jsp与JDBC技术
- 粒子滤波在视频目标跟踪中的应用与MATLAB实现
- ISTQB ISEB基础级认证考试BH0-010题库解析
- 深入探讨HTML技术在hundeakademie中的应用
- Delphi实现EXE/DLL文件PE头修改技术
- 光线追踪:探索反射与折射模型的奥秘
- 构建http接口以返回json格式,使用SpringMVC+MyBatis+Oracle
- 文件驱动程序示例:实现缓存区读写操作
- JavaScript顶盒技术开发与应用
- 掌握PLSQL: 从语法到数据库对象的全面解析
- MP4v2在iOS平台上的应用与编译指南
- 探索Chrome与Google Cardboard的WebGL基础VR实验
- Windows平台下的IOMeter性能测试工具使用指南
- 激光切割板材表面质量研究综述
- 西门子200编程电缆PPI驱动程序下载及使用指南
- Pablo的编程笔记与机器学习项目探索
