任务自适应神经过程:元学习解决用户冷启动推荐
PDF格式 | 1.1MB |
更新于2025-01-16
| 49 浏览量 | 举报
"用户冷启动推荐:任务自适应神经过程的元学习模型及验证"
这篇论文主要探讨了在推荐系统中解决用户冷启动问题的新方法,即任务自适应神经过程(Task-Adaptive Neural Process,简称TaNP)。用户冷启动推荐是指在推荐系统中,对于新用户或交互数据有限的用户,由于缺乏足够的历史行为数据,推荐系统难以准确地理解和预测用户的兴趣和偏好,从而导致推荐效果不佳的问题。传统的推荐策略往往依赖于大量的用户行为数据,但在用户刚接触系统时,这样的数据通常是稀缺的。
元学习(Meta-learning)是一种应对这一问题的潜在解决方案,通过学习多个相关任务的通用知识,使得模型能快速适应新的任务,即在冷启动用户推荐场景中,模型能利用之前用户的数据快速理解新用户的行为模式。大多数现有的元学习模型采用参数初始化的方式,通过几轮梯度更新来调整模型参数,以适应新任务。然而,这些模型在将全局知识有效地应用于冷启动用户推荐时仍存在局限。
为此,论文提出了TaNP,这是一种基于神经过程的元学习推荐模型。神经过程是一类可以学习并生成概率分布的模型,它们能够为每个用户生成与随机过程相关的推荐。TaNP的独特之处在于,它将每个用户的交互数据直接映射到预测分布,避免了基于梯度的元学习模型中的训练难题。此外,TaNP引入了一种任务自适应机制,这种机制允许模型学习不同任务之间的关联性,并根据任务特性定制解码器参数,以更好地估计用户的偏好。
通过在多个基准数据集上的实验,TaNP在与多个最先进的元学习算法的比较中显示出了显著的性能提升,证明了其在处理用户冷启动推荐问题上的有效性。实验结果进一步支持了TaNP在模型容量和自适应能力之间取得的良好平衡。
该研究对推荐系统领域具有重要意义,它提供了一个新的视角和工具来解决冷启动问题,特别是在数据有限的情况下,能够快速且准确地为新用户提供个性化推荐。此外,TaNP的提出也为元学习在其他领域的应用提供了新的可能,比如适应性强、快速学习的任务型智能系统。
1308
∈
j
=
1
j
=
1
j
=
1
j=1
∈
不
T {
| ∈
}
T {
| ∈
}
冷启动问题 它使用任务依赖的方式来生成针对不同任务的决策层的
不同偏差,但它易于
欠拟合并且不够灵活以处理各种
推荐场景
[2]
。
MeLU [25]
采用了
MAML
的框架具体而言,它将模型参数分
为两组,即,
个性化参数和嵌入参数。 个性化
参数被表征为全连
接
DNN
以估计用户偏好。嵌入参数被称为从边信息学习的用户和
项目的嵌入一个内部
-
外部循环用于更新这两组参数
。 在内部循环
中,个性化参数
通过当前任务的预测支持集损失进行局部更新。 在
外
循环中,这些参数根据多个任务中查询集的预测损失进行全局更
新。 通过局部
-
全局更新的方式,
MeLU
可以为不同的任务提供共
享的初始化
。
后来的工作MetaCS [2]与MeLU非常相似,
主要区别在于局
部
-
全局更新涉及
从输入嵌入到模型预测的所有参数。 为了很好
地概括
不同的任务,两个最新的作品
MetaHIN [30]
和
MAMO [9]
提出了不同的任务特定的适应策略。特别地
,
MetaHIN
将异构信息
网络(
HIN
)并入
MAML
中以捕获元路径的丰富语义。
MAMO
引
入了两个基于用户配置文件的记忆矩阵:一个是为共享参数初始化
提供特定偏置项
的特征特定记忆
;
一个是指导模型进行预测的任务特
定记忆。然而,这两种基于梯度的
Meta
学习模型在
MAML
中仍然存
在潜在的训练问题
,并且它们的模型级创新
与边信息密切相关,这
限制了它们的应用场景。
2.3 神经过程
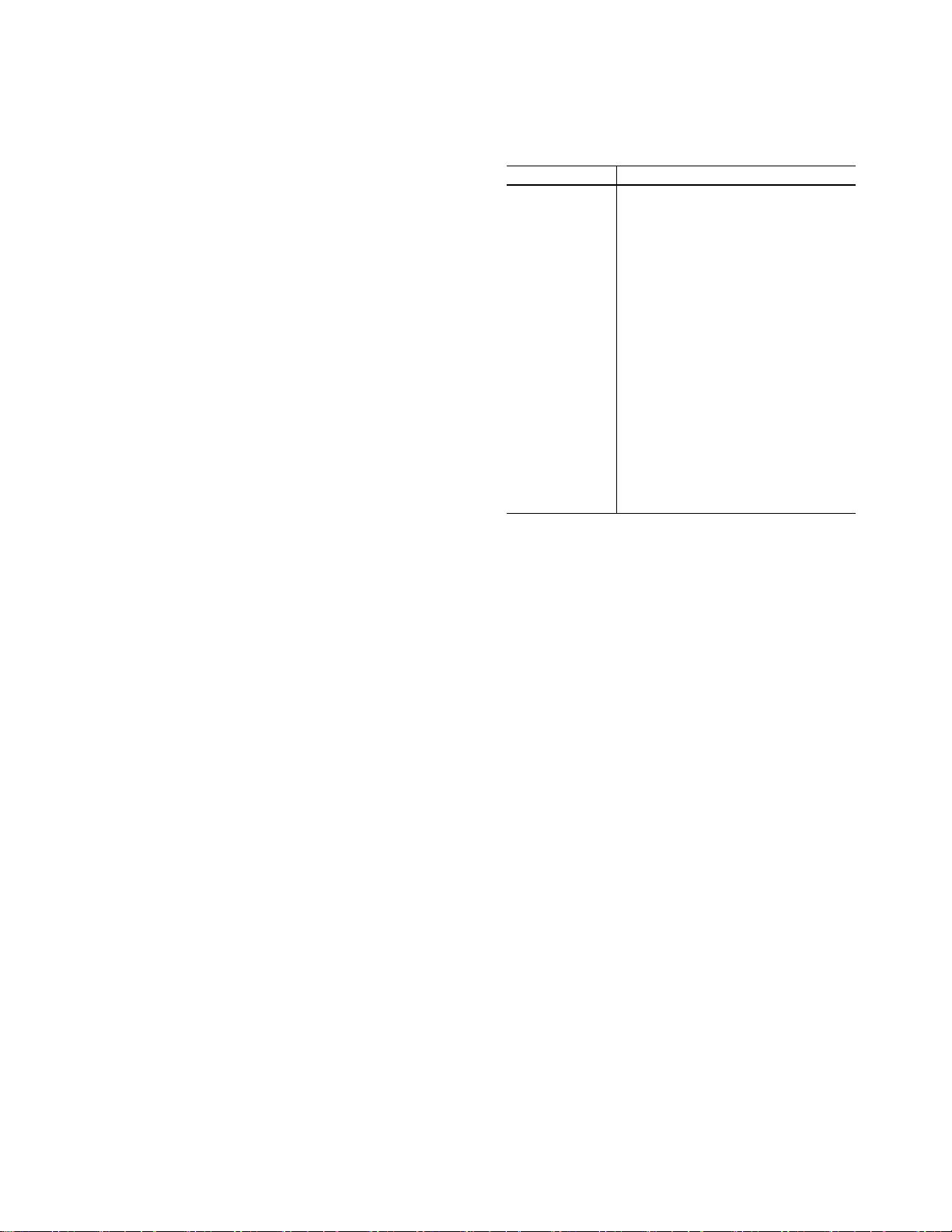
表1:符号
符号
描述
U和V U
tr
和U
te
T
tr
和
T
te
τ
i
,
S
i
和
Q
i
x
i
,
j
=
(
u
i
,
v
j
)
y
i
,
j
N
i
N
S
i
而N
Q
i
c
i
,
nE
n
h
θm
A
C
D
德
哥
伊
γ
l
、
β
l
、
η
l
和
δ
l
i
i i i
用户集和项集
训练用户集和测试用户集训练任
务集和测试任务集任务
i
、支持
集i和查询集iu
i
和v
j
之间的交互
x
i,j
的实际评级
τ
i
中的相互作用数
S
i
和
Q
i
中的交互数u
i
的独热内容向量
所有任务的
嵌入层
共享编码器
任务标识网络
全局池
软簇分配矩阵聚类目标分布
自
适应译码器
特征调制参数
对于第
l
层
定义
3.1. 给定用户集合U、项目集合V和特定用户u
i
U,为ui
进行个性化推荐
被定义为任务
τ
i
。
τ
i
包括
u i
的可用交互
,即,
{
x
i
,
j
,
y
i
,
j
}
N
i
.
xi
,
j
表示元组(
ui
,
vj
),其中
vj
∈
V
表示项
目,
yi
,
j
是
ui
对项目
vj
的实际评级
。 N
i
表示
τ i
中相互作用的数量。 为
了符号简单,我们
还表示
τ
i
={
xi
,
j
,
yi
,
j
}
N
i
。
τ
i
包含少量交互作为
支持集
Si
,剩余交互作为查询集
Q
i
,即,
NP
是一个基于神经的随机过程的公式,
{x
i
,
j
,
y
i
,
j
}
N
i
=S
i
Q
i
. 这里,我们表示
Si
={
xi
,
j
,
yi
,
j
}
N
Si
,
并且
函数的分布[13,14]。它是一类神经潜在
Q
i
={x
i
,
j
,y
i
,
j
}
N
S
i
+N
Q
i
。
N
S
表示交互
变量模型,结合了高斯过程的优势
,
j
=
N
S
i
+
1
i
(
GP
)和
DNN
来实现灵活的函数近似。
NP
主要集中在低维函数
回归和不确定性估计领域
[29]
。与此同时,
关于提高
vanilla NP
模型表达能力的研究也越来越多
.
例如,
ANP [20]
引入了
自注意
NP
来减轻
NP
的欠拟合
; CONVCNP [15]
对数据中的翻译等方差进行
建模,并将任务表示扩展到函数空间。
NP
也适用于元学习
问题
[39],因为它提供了一种有效的方法来建模
预测分布,该预测分
布以
从上下文观察中学习的置换不变表示为条件。我们的模型是
第一个研究,利用
NP
的原则来解决用户冷启动推荐,涉及学习离
散的用户项关系数据,这是很大程度上不同于以往的作品。此
外,
TaNP
包括一个新的任务自适应机制,以更好地平衡模型容
量和自适应可靠性之间的权衡
3 预赛
我们从元学习的角度阐述了用户冷启动推荐问题
。 遵循传统的情景
学习方式,我们首先给出了任务(情景)的正式定义。
S
i
,其通常被设置为具有小值,并且
N
Q
i
是
Q
i
中的交互的数
量,其中
N
S
i
+
N
Q
i
=
N
i
。
注意,元学习推荐器首先在每个支持集上学习(学习过程),
然后根据多个查询集上的预测损失进行更新(学习到学习过
程)。 通过在多次迭代中第二个过程的指导,该元学习模型可以
获得跨不同任务的全局知识,并且可以很好地将这些知识适应于
只有
Si
可用的新
任务τ
i
。
为此,我们将
U
分成两个不相交的集合:训练用户集合
U
tr
和测
试(冷启动)用户集合
U
te
。 所有训练任务的集合
表示为
tr
=τ
i
u
i
U
tr
,所有测试任务的集合表示为
te
=τ
i
u
i
U
te
。在训练阶段,我们可以
按照学习到学习的
方式为每个训练
任务训练在测试阶段,当一个冷启动用户
u
i
′
U
te
到来时,我们的
目标是根据
Si′
中的
少量交互
和从
tr
中学习到的全局知识
,找到
ui′
会对哪些项目感兴趣
。表
1
总结了本文中
使用的符号此外,根据
y
i
,
j
的具体值,个性化推荐可以被视为指
示
u
i
是否与
v
j
接合的二元分类,或者可以被视为回归问题,
Vj
具有需要由
Ui
评估的不同评级。
剩余13页未读,继续阅读
相关推荐





cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- ITween插件实用教程:路径运动与应用案例
- React三纤维动态渐变背景应用程序开发指南
- 使用Office组件实现WinForm下Word文档合并功能
- RS232串口驱动:Z-TEK转接头兼容性验证
- 昆仑通态MCGS西门子CP443-1以太网驱动详解
- 同步流密码实验研究报告与实现分析
- Android高级应用开发教程与实践案例解析
- 深入解读ISO-26262汽车电子功能安全国标版
- Udemy Rails课程实践:开发财务跟踪器应用
- BIG-IP LTM配置详解及虚拟服务器管理手册
- BB FlashBack Pro 2.7.6软件深度体验分享
- Java版Google Map Api调用样例程序演示
- 探索设计工具与材料弹性特性:模量与泊松比
- JAGS-PHP:一款PHP实现的Gemini协议服务器
- 自定义线性布局WidgetDemo简易教程
- 奥迪A5双门轿跑SolidWorks模型下载
