变换判别式自编码器在低分辨率未对齐噪声人脸图像超分辨率中的应用
PDF格式 | 1.18MB |
更新于2025-01-16
| 11 浏览量 | 举报
"这篇论文提出了一种新的方法,利用变换判别式自编码器来处理极低分辨率、未对齐且包含噪声的人脸图像的超分辨率问题。传统的超分辨率技术通常要求输入图像清晰、对齐且无噪声,但在实际场景中,这样的条件很难满足。论文中的方法采用了解码器-编码器-解码器网络架构,首先通过变形的歧视性解码器网络进行上采样和去噪,然后使用transformative编码器将处理后的高分辨率(HR)人脸投影到对齐且无噪声的低分辨率(LR)空间,最后由第二个解码器生成超分辨率图像。实验结果表明,该方法在大规模人脸数据集上表现优越,相比于最先进的技术提升了1.82dB的峰值信噪比(PSNR)。"
这篇研究是针对人脸识别领域的,尤其是处理低质量和未对齐的人脸图像。人脸超分辨率技术的目标是从低分辨率图像中恢复高分辨率图像,这对于身份识别、监控视频分析等应用至关重要。传统的自动编码器和卷积神经网络(CNN)方法在处理噪声和未对齐的图像时效果受限。论文中提出的方法创新性地采用了解码器-编码器-解码器结构,将去噪和对齐步骤与超分辨率结合起来,以解决这些挑战。
首先,变形的歧视性解码器网络用于同时提升分辨率和去除图像噪声。接着,transformative编码器网络将处理后的高分辨率图像转换到一个理想的低分辨率空间,这里图像已对齐且没有噪声。最后,通过第二个解码器,生成最终的超分辨率人脸图像。这种方法的优势在于它能够处理输入条件较差的情况,且在实际测试中表现出了显著的性能提升。
论文指出,这种方法的实施得益于澳大利亚研究委员会的资助,并且通过与现有最佳方法URDGN的对比,证明了其优越性。URDGN虽然也能进行超分辨率,但它依赖于去噪和对齐的LR图像,而新方法直接处理原始LR输入,效果更佳。
该研究提供了一种有效的解决方案,用于处理在实际应用中常见的低质量、未对齐的人脸图像,对于提升人脸识别系统的性能具有重要意义。通过结合去噪、对齐和超分辨率步骤,该方法展示了在复杂条件下重建高清晰度人脸图像的强大能力。
3762
§
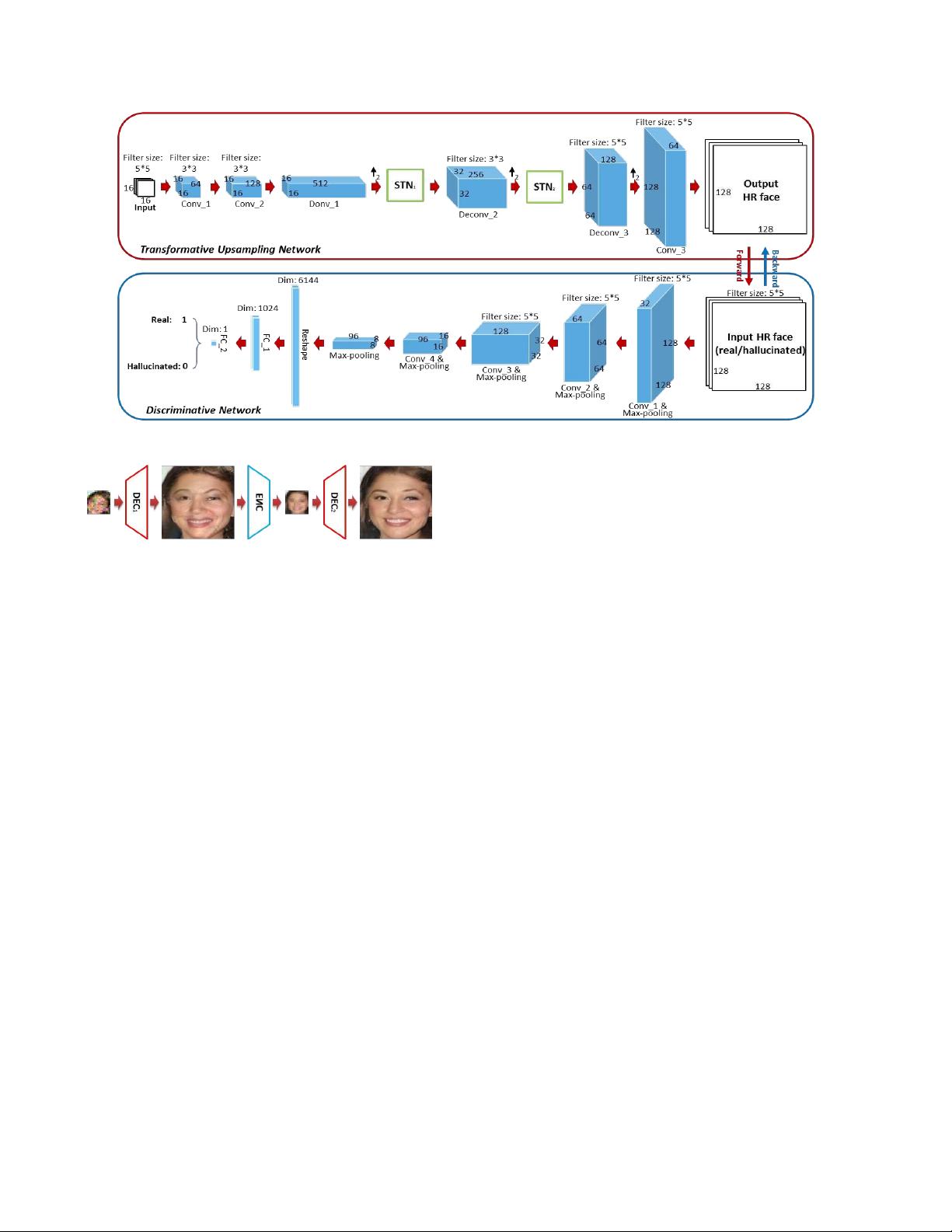
图2. 我们的变换判别解码器由两部分组成:一个变换上采样网络(红色框)和一个判别网络(蓝色框)。
图4. 我们的变革判别式自动编码器的工作流程。方框的颜色
参考图中的网络
2
和图
3 .
第三章。
提取的特征。由于人脸特征提取的要求,输入的分辨
率不能低。最近,[25]提出了一种判别生成网络来超
分辨率LR人脸图像。这种方法解决了不同的面部表情
和头部姿势,不需要面部标志,但它需要眼睛提前对
齐。 [29]提出了一种级联双网络来超级解析非常低分
辨率和未对齐的人脸。然而,当LR图像中存在噪声
时,该方法可能无法准确地定位面部部分,从而在输
出中产生伪影。
3.
拟定方法:TDAE
我们的变革性判别式自动编码器有三个互补的组
件:两个变换的判别式本地解码器(如图1B所示)。
2)和一个变换编码器(如图所示)。(3)第三章。
在训练阶段,TDAE的参数分三步学习(. 3.3)。在测
试阶段,我们将第一解码器DEC
1
、编码器ENC和第二
解码器DEC
2
的变换上采样网络级联在一起,以端到端
的方式对最终的HR面进行超分辨率处理。整个流水线
如图所示。4
3.1.
解码器的体系结构
我们的解码器架构由两个子
网络组成,一个变换
上采样网络(TUN)和一个判别网络。 在变换上采样
网络中,我们首先应用两个具有较大感受野的卷积层
来部分减少噪声伪影,而不是将噪声图像直接馈送到
去卷积层中。去卷积层可以由上采样层和卷积层的
级联 组 成, 或者 是具有 分 数步 长 的卷 积层
[27
,
26]
。因此,去卷积层的输出图像的分辨率大于其输
入图像的分辨率我们采用了
102
回归损失,也称为欧
几里德距离损失,以约束
hallucinated HR
面部和他们
的
HR
地面实况版本之间的相似性
如
[25]
中
所
报告的,由
102
损失监督的去卷积层往
往会产生过度平滑的结果。 为了解决
这个问题,我
们通过判别网络将特定于类的判别信息嵌入到去卷积层
中
(如图中的蓝色框所示)。
2
)的情况。判别网络
能够区分图像(其输入)是从真实的面部图像还是
幻觉图像中采样
相应的判别信息被反向
传播到去卷积
层。因此,反卷积层可以生成更类似于真实面部的
HR
面部图像
我们注意到LR人脸图像的旋转和尺度错位将导致
[25]中上采样人脸图像中的明显伪影相比之下,我们
的解码器可以自动对齐LR的脸,并同时幻觉的脸图
像 。 为 了 对 齐 LR 面 , 我 们 将 空 间 变 换 网 络
(spatialtransformation network)[10]合并到我们的网络
中,如图中的绿色框所示。二、马达加斯加估计,
剩余10页未读,继续阅读
相关推荐

467 浏览量



cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现ART与SART算法在医学CT重建中的应用
- S2SH整合版:快速搭建Struts2+Spring+Hibernate开发环境
- 托奇卡项目团队成员介绍
- 提升外链发布效率的SEO推广神器——搜易达网络推广大师v2.035
- C#打造简易记事本应用详细教程
- 探索虚拟现实地图VR的奥秘
- iOS模拟器屏幕截图新工具
- 深入解析JavaScript在生活应用开发中的运用
- STM32F10x函数库3.5中文版详解与应用
- 猎豹浏览器v6.0.114.13396 r1:安全防护与网购敢赔
- 掌握JS for循环输出的最简洁代码技巧
- Java入门教程:TranslationFileGenerator快速指南
- OpenDDS3.9源码解析及最新文档指南
- JavaScript提示框插件:鼠标滑过显示文章摘要
- MaskRCNN气球数据集:优质图像识别资源
- Laravel日志查看器:实现Apache多站点日志统一管理
