编码器-解码器架构:线条画驱动的3D形状重建与编辑
PDF格式 | 18.74MB |
更新于2025-01-16
| 39 浏览量 | 举报
"《从线条绘画中重建和编辑3D形状的编码器/解码器架构》一文探讨了一项前沿技术,旨在解决从2D草图中重建和编辑3D形状这一长期存在的挑战。文章介绍了一种基于编码器/解码器结构的方法,该结构允许将二维草图转化为可编辑的三维网格,从而实现对设计、工程和艺术领域中的CAD系统交互方式的革新。
传统的深度学习方法虽然在合成数据上表现出良好性能,但当应用于实际手绘草图时,它们往往生成粗糙的3D点云或受限于特定视图的重建结果。相比之下,单视图重建(SVR)方法近年来取得了显著进步,利用新颖的形状表示和图像特征的池化技术,使得从单张图片恢复3D形状成为可能。
作者提出的Sketch2Mesh方法,采用编码器/解码器架构,从合成草图中生成高质量的表面网格。该网络学习到一种紧凑的3D形状表示,使得即使面对不同风格的线条绘画,也能确保投影的外轮廓与输入草图保持一致。此外,这种方法的优势在于其易于部署,对风格变化具有鲁棒性,并且能处理单个笔画的形状优化,极大地扩展了用户在2D绘制环境下的交互体验。
通过与当前最先进的方法进行比较,研究者展示了他们的方法在处理手绘草图(包括手绘和合成的草图)时表现出优越性,能够生成更精细、易于编辑的3D形状。这项工作对于提高CAD系统的易用性和效率具有重要意义,有望在未来的设计和创作流程中发挥关键作用。"
13023
0
Sketch2Mesh:从草图中重建和编辑3D形状
0
BenoitGuillard*,EdoardoRemelli*,PierreYvernay,PascalFua
0
CVLab,EPFL
0
name.surname@epfl.ch
0
摘要
0
从2D草图中重建3D形状长期以来一直是一个悬而未决的问题。
0
因为草图只提供了非常稀疏和模糊的信息,所以从2D草图中
重建3D形状一直是一个悬而未决的问题。在本文中,我们使
用了一个编码器/解码器架构来进行草图到网格的转换。当
集成到为草图提供相机参数的用户界面中时,这使我们能够
利用其潜在参数化来表示和优化3D网格,使其投影与草图中
的外轮廓相匹配。我们将展示这种方法易于部署,对风格变
化鲁棒,并且有效。此外,它可以用于仅给出单个笔画的形
状优化。
0
我们将我们的方法与最先进的方法进行比较,
0
我们比较了手绘草图(包括手绘和合成的草图)的现有方法
,并证明我们的方法优于它们。
0
1.引言
0
从手绘草图中重建3D形状一直是一个悬而未决的问题。
0
有潜力彻底改变设计师、工业工程师和艺术家与计算机辅助
设计(CAD)系统互动的方式。它不仅可以解决工业界需要
将大量遗留模型数字化的需求,这是一项无法克服的任务,
而且还可以让从事者通过2D绘制与形状进行互动,这对他们
来说是自然的,而不是必须通过笨重的3D扫描仪来雕刻3D
形状。
0
当前的深度学习方法[26,6,45,46]
0
尽管这些方法在合成数据上进行训练,但是从2D草图中回归
3D点云和体积网格显示出了希望,但是得到的3D表面表示
粗糙且难以编辑。此外,它们需要有效重建的多视图草图[6]
或仅限于固定的视图集[26]。
0
与此同时,单视图重建(SVR)方法-
0
由于引入了新的形状表示[11,33,30,36]以及利用图像平面特征池化对齐重建到输入图像的新颖架构[43,10,
13,44],这些方法取得了快速进展。
0
*相等贡献
0
(a)重建
0
(b)编辑
0
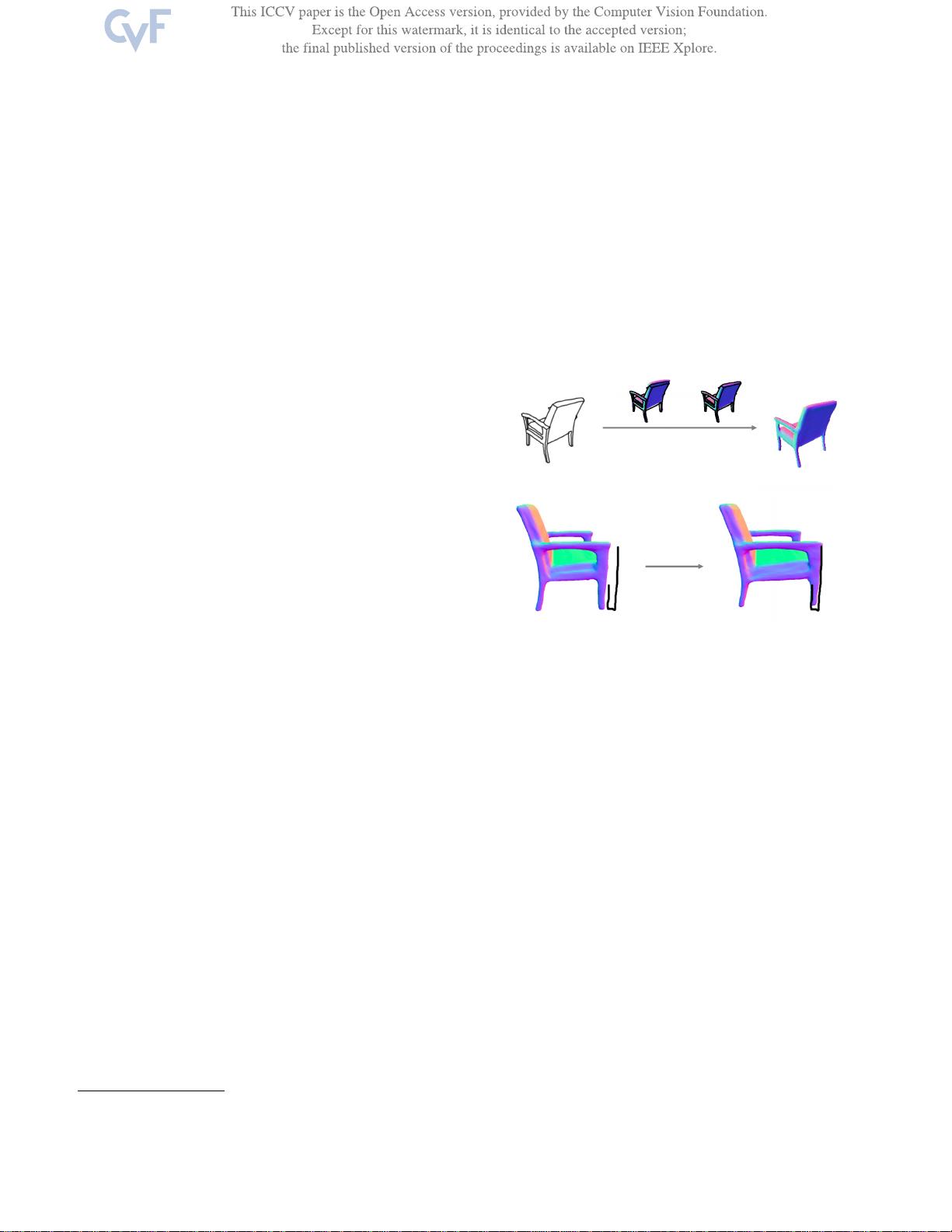
图1.Sketch2Mesh.
我们提出了一个从线条绘画中重建和编辑3D形状的流程。我们训练
了一个编码器/解码器架构,从合成的草图中回归出表面网格。我们
的网络学习到了适用于下游优化的3D形状的紧凑表示:(a)当呈现给
与训练样本不同风格的线条绘画时,将投影的外轮廓与输入线条绘
画对齐可以弥合领域差距。(b)相同的公式可以用于使经验不丰富的
用户通过简单的2D笔画来编辑重建的形状。在补充视频中最好看到
。
0
通过引入新的形状表示[11,33,30,
36]以及利用图像平面特征池化对齐重建到输入图像的新颖
架构[43,10,13,
44],我们克服了这些挑战。因此,似乎也可以将它们用于
从草图中进行重建。不幸的是,正如我们将展示的那样,草
图图像的稀疏性使得依赖于从图像平面进行局部特征池化的
最先进的SVR网络难以表现良好。这种困难加剧了不同人的
不同绘画方式,这在训练过程中引入了很大的变异性,并使
得泛化变得困难。此外,这些架构不能学习到3D形状的紧凑
表示,这使得学习的模型变得不够理想。
下载后可阅读完整内容,剩余9页未读,立即下载
相关推荐




cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 2016版四级行政区划SQL数据库及其应用
- Android入门小白的webService访问实践Demo
- 自动清理浏览器搜索历史的Search Privately-crx插件
- Python+MySQL实现的教务管理系统课程设计
- Swydo自定义集成教程:让在线平台数据无缝接入
- 如何查看文件后缀及了解其应用
- iOS实现简易webView加载功能
- Nest框架:高效可扩展的Node.js服务器端开发
- SourceTree 1.8.3版本发布,功能优化与更新
- Web Cache Viewer:浏览器扩展浏览历史缓存
- 《笨办法学Python 3》英文原版教程解析
- 探索Shell扩展技术及其应用
- Java项目中Geocoder相关依赖jar文件导览
- 系统窗口枚举与句柄获取及关闭技术解析
- Docker代码演示:Python和Node.js环境配置示例
- iOS APP版本更新弹窗提醒功能
