




SDE生成器——基于SDE的瞬时流建模方法
29 浏览量
更新于2025-01-16
收藏 1.83MB PDF 举报

11635
·
-
-
神经TMDlayer:通过SDE生成器建模要素的瞬时流
孟梓航
1
Vikas Singh
1
Sathya N.
拉维
2
1
威斯康
星大学麦迪逊分校
2
伊利诺伊大学芝加
哥分校
网址:zihangm@cs.wisc.edu,vsingh@biostat.wisc.edu,网址:www.example.com,sathya@uic.edu
摘要
我们研究了如何随机微分方程(
SDD
)为基础的想
法可以激发新的修改现有的一组问题在计算机视觉的
出租。松散地说,我们的配方是有关的显式和隐式的
数据扩充和组
equivariance
的战略,但来自新的结果估
计无穷小发电机一类随机过程的
SDE
文献。如果并且
当在应用程序
/
任务的需求与我们可以有效处理的过程
类型的固有属性和行为之间存在名义上的协议时,我
们获得了可以被并入任何现有网络架构内的非常简单
和有效的插件层,具有最小的修改和仅几个附加参
数。我们在一些视觉任务上展示了有前途的实验,包
括几个镜头学习,点云变换器和深度变分分割,以提
高效率或性能。
1.
介绍
考虑具有参数
我们使用下面的更新规则来训练它,
W
←
W
−
η
W
E
z
R
(
W
,
z
)
(
1
)
其中z是表示数据的随机变量,R()表示损失函数。
现在,考虑同一更新公式的稍微一般的形式,
W
←
W
− η
W
E
z
R
(
W
,
T z
)
.
(
二)
这里唯一的变化是引入了T,可以假设T是
某个
数据转
换矩阵。如果T=I,我们看到随机梯度下降(SGD)是
(2)的特殊情况,假设我们用有限的iid样本(或小批
量)近似(2)中的期望。让我们稍微打开数据转换符
号,看看它提供了什么如果选择一组变换T
由于Tz是预先确定的,并且在训练开始之前被应用于
数据样本,因此Tz简单地表示经由数据增强导出的数
据样本。另一方面,Tz可以不必如上所述被显式地实
例化。例如,球形CNN[16]表明,当点云类型的数据
嵌入到具有球形卷积算子的球体上时,可以学习与旋
转的群作用等变的数据表示,而无需显式数据增强过
程。特别地,这些方法
将
每个数据点配准在标准
模板
(如球体)上,在标准模板上可以基于微分几何构造
来定义从概念上讲,关于等方差的许多结果[16,48,
42]表明,通过在训练期间考虑每个样本(3D点云)的
整个
轨道,对于特殊类型的T,可以避免显式数据增
强。
我们可以从更广阔的角度来看待上述观点。在数
据点
z
上重复应用变换
T
产生离散序列
z
(
t
)
∞
t
=0
其
中
z
(0)
=
z
,
z
(
t
)
=T
t
−
1
z
。通常,由
T
(
t
)表示的
第
t
步处的变换矩阵甚至不需要从固定矩阵生成。实
际上,在实践中
,
T
(
t
)是从一组适当的变换(例
如旋转、模糊等)中选择的,具有某种排序,其甚
至可以是随机的。 在高层次上,诸如
[16
,
12]
的方法
可以被视为(
2
)的特例。要使这一论证精确,需要
添加适当数量的辅助变量,并通过对所有可能的可
实现
T
进行平均
--
具体步骤并不是特别相关,因为除了帮助
建立我们刚刚描述的直觉之外,特定群体行为的等方差算法
并不直接告知我们的发展。为了方便起见,我们将主要
关注连续时间系统,因为在相同的初始条件下,两
个(连续和离散)系统的轨迹在所有整数
t
处重合。
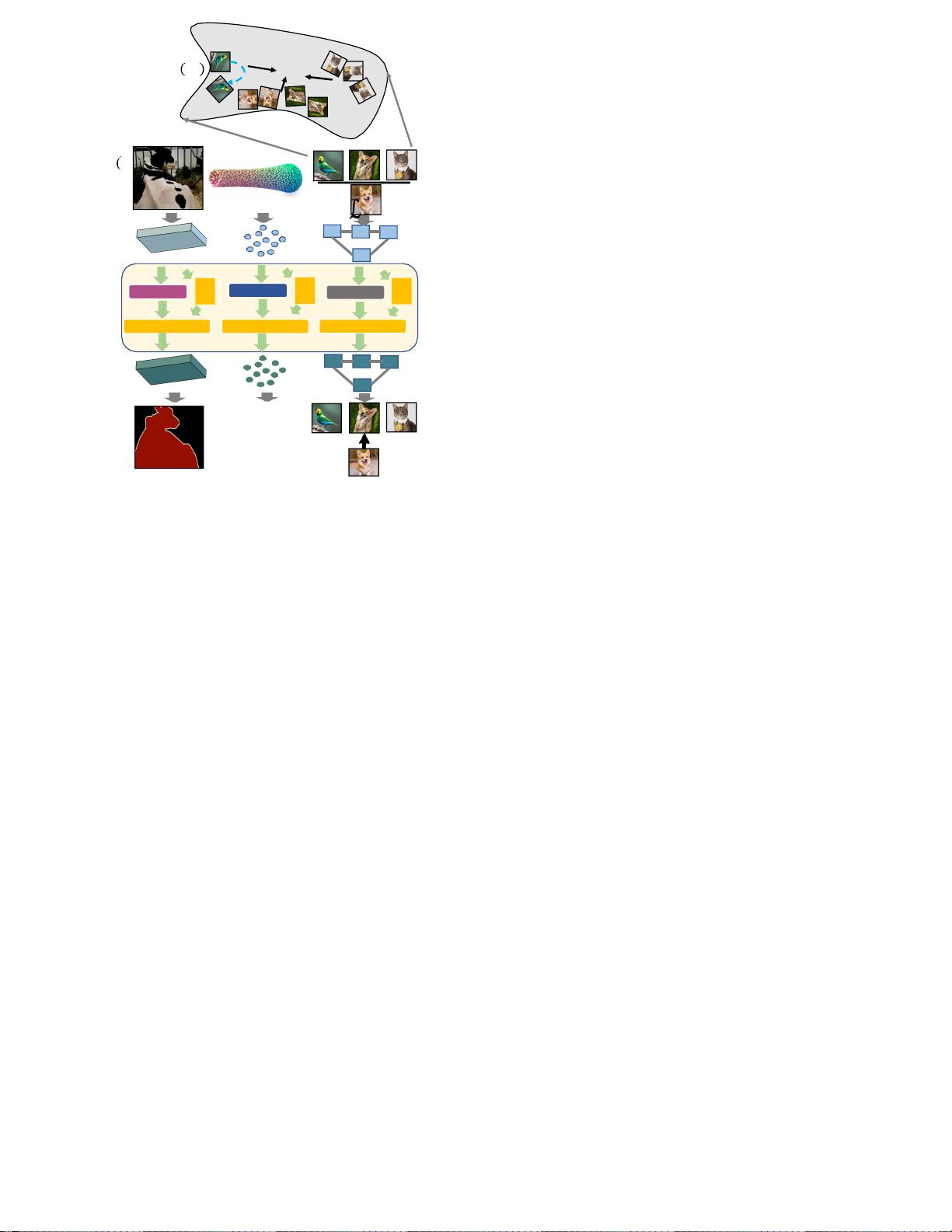
z(t)实际上代表什么?z(t)有两种解释:(i)
它形式化为on-the-fly或instan-

剩余13页未读,继续阅读
查看更多
2021-11-21 上传
2752 浏览量
638 浏览量
505 浏览量
2021-05-17 上传
2021-03-30 上传
122 浏览量
2023-04-04 上传
123 浏览量

cpongm
- 粉丝: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- React和Redux打造的Addressbook应用教程
- AvaloniaUI中的Material设计自定义主题指南
- imageCarousel.js: 实现图像div到美丽轮播的转变
- STM32F4实现AD采集与FFT转换的深入解析
- C++模板类实例化与文件分离引发的LNK2019错误解决方案
- 未来科技风商务计划PPT模板——机械手臂与触控创新设计
- Infobrothers-crx插件:快速获取新技术更新
- Angular项目开发指南:Environment-Metrics-App
- 深入定制MINIX 3:探索CSC-502课程操作系统原理
- LeetCode学习与系统设计开源实践
- 精选8款jQuery评分插件,打造酷炫用户评价系统
- Python实现社会选择获胜者计算方法详解
- 解决PB开发工具连接数据报错丢失DLL问题
- 适体算法的实现与应用研究
- 硕士学位最终作品:深入分析bookings_analysis项目
- 儿童节特色——月亮上的童话动态PPT模板





















