自互蒸馏提升连续手语识别:融合视觉与上下文模块
PDF格式 | 1.52MB |
更新于2025-01-16
| 67 浏览量 | 举报
连续手语识别(Continuous Sign Language Recognition, CSLR)是深度学习领域的一个重要研究方向,特别是在视频信号处理中,它旨在理解和翻译手语表达。近期,深度学习技术极大地推动了CSLR的发展,特别是通过构建复杂的网络结构,如结合视觉模块和上下文模块来捕捉空间、短时和长时信息。传统的CSLR模型通常包括:
1. 视觉模块:专注于捕捉手势的空间布局和短期时间特征,它通过深度神经网络(DNN)学习手部、身体动作和环境背景等视觉元素。然而,由于反向传播中的链式规则限制,视觉模块的优化可能受到限制,无法完全适应最佳视觉特征提取。
2. 上下文模块:负责关注更长时间序列中的上下文信息,如手势之间的关联性和动态变化。主流方法使用条件随机场(Conditional Random Field, CRF)或连接主义时间分类(Connectionist Temporal Classification, CTC)损失函数来训练网络,使得上下文模块在优化过程中主要关注上下文而非视觉特征。
为了克服这种不平衡,本文提出了自互蒸馏学习(Self Mutual Knowledge Distillation, SMKD)方法。SMKD的主要创新在于:
- 共享分类器:视觉和上下文模块共享同一分类器的权重,这样两个模块可以相互学习,增强对时空信息的理解,同时提高它们区分短期和长期特征的能力。
- 光泽度分割:引入到视觉模块中的技术,用于减少图像中的峰值现象,如饱和度,从而更好地提取和利用关键帧的视觉信息。
- CTC损失优化:尽管CTC损失有助于选择关键帧,但它可能导致其他帧信息丢失。SMKD通过改进的策略,保持了整体序列的信息完整性。
在实验部分,作者在两个CSLR基准测试集,即PHOENIX14和PHOENIX14-T上验证了SMKD的有效性。结果表明,与传统方法相比,SMKD不仅提升了识别准确率,还实现了视觉和上下文模块的均衡优化,从而在连续手语识别任务中取得了显著的进步。这一研究对于提高手语识别系统的性能,特别是对于促进听力障碍人群的无障碍沟通具有实际意义。
11305
视觉模块
模块
2D
CNN
Δt
1D
CNN
BiLSTM
2D
CNN
光泽分割
...
分类器
分享
分类器
Δt
1D
CNN
...
...
...
...
BiLSTM
2D
CNN
Δt
1D
CNN
...
BiLSTM
Δt
1D
CNN
...
分类器
分享
分类器
2D
CNN
推断结果
分类器
分享
分类器
i
=1
Σ
∈
R
ΣΣ
∥
∥
t
=1
关于
我
们
t
=1
不
上下文
HEUTE / NACHT / FLUSS /DREI
不
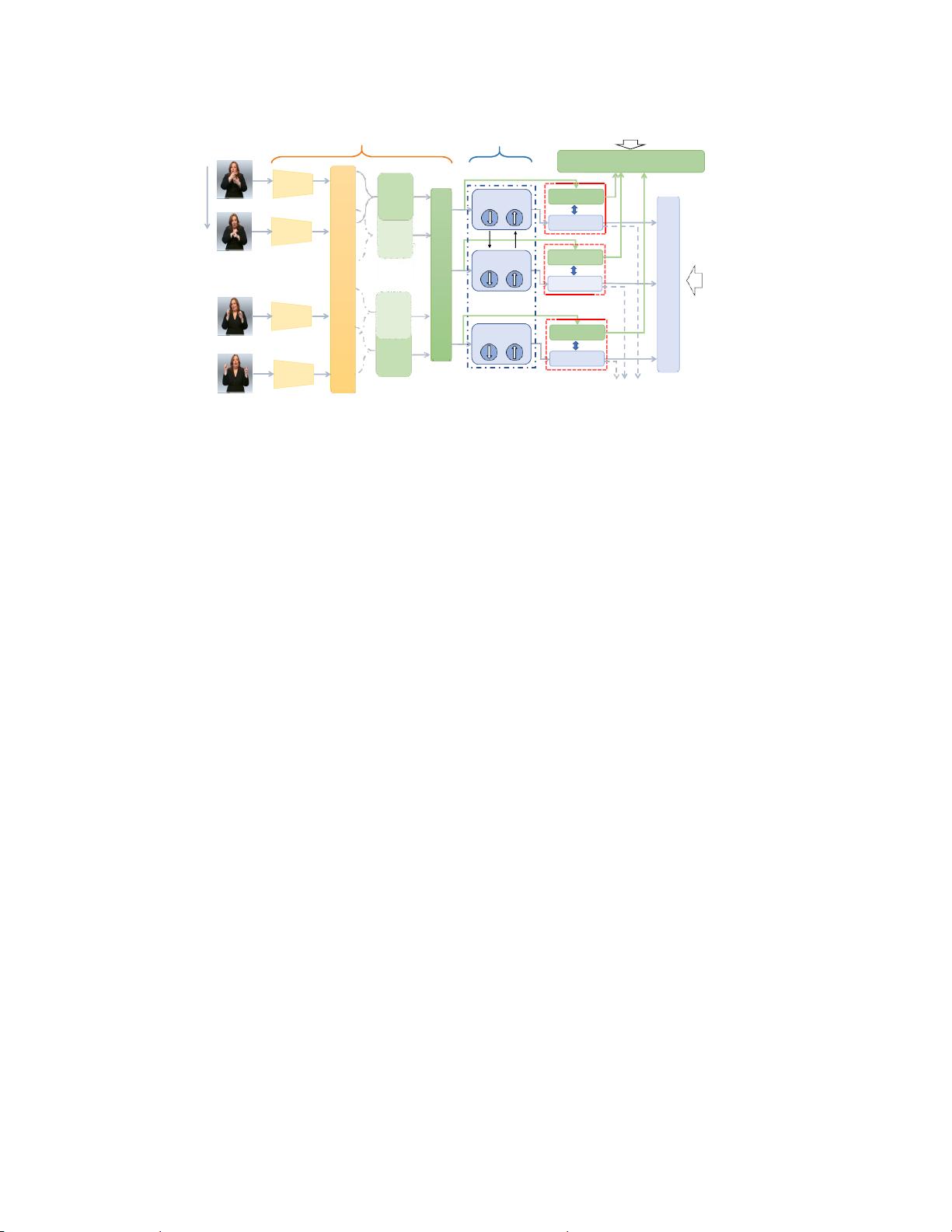
图
2.
拟定
SMKD
的流程图。该过程包括使用
2D-CNN+1D-CNN
(视觉模块)的视觉提取和使用
BiLSTM
(上下文模块)的上下
文集成。视觉和上下文模块共享其相应分类器的权重,并同时使用
CTC
和光泽分割进行训练注意,只有来自上下文模块的预测
序列有助于推断阶段期间的识别,如虚线框所示。
学生 模型, 通过 提供软 目标 [11]或 直接继 承教师 然
而,如[32]所示,朴素知识蒸馏存在两个问题:知识
转移效率低,教师模式设计困难。为了解决这些问
题,Zhang
等
。[32]提出了自蒸馏的思想,即从模型本
身提取知识,以提高泛化性能。此外,一些作品[33,
31]建议完全免除教师,并允许学生合奏教每个
bel序列l
=
L
i
G
N
其中G是注释词汇表。为了对映
射进行建模,所提出的方法包含如Sect.2.1.所提出的方
法的结构如图所示。2,详情如下。
特征提取。视觉模块
Ev
由分别编码空间和短期时间信
息的2D-CNN和1D-CNN形成。然后,我们得到局部视
觉特征(LVF):
另一种称为互蒸馏。在这项工作中,我们建议将模型
的不同模块视为多个模块。
V
=
.
v
t
D
T
t
=1
⇒
v
t
=E
v
.Σ
x
t
−
r/
2
、
...
、
X
t
+
r/
2
、
(一
)
通过共享学生网络的权重矩阵实现知识转移
3.
自互知识蒸馏
提出了一种SMKD方法,以充分利用视觉模块的能
力我们首先提出的框架和制定所提出的方法(节。第
3.1节)。然后,我们重新审视CTC损失(第二节)。
3.2)
其中
,
T
=
T/S表示LVF的持续时间,S是下采样率,并
且r表示视觉模块的时间接收场。对于上下文模块
Eg
,
利用两层BiLSTM来编码视觉信息。
在一些实施例中,所述方法包括:存储由视觉模块提
供的长期上下文信息,并且将所述长期上下文信息与
内 部 状 态 一 起 存 储 。 然 后 , 获 得 全 局 上 下 文 特 征
(GCF):
T
并给出了权重分配的细节,以促进视觉模块的贡献
(Sect.3.3)。之后,我们显示
G
=
.
g
t
∈
R
d
Σ
t
=1
⇒
g
t
=
E
g
.Σ
v
1
,
…
,
v
T
Σ
Σ
.
(二
)
Sect.3.4,随后是添加光泽分割以强制视觉模块在更多
帧中提供视觉特征的所提出的解决方案(Sect.3.5)。
最后,我们提出了一个三阶段的优化方法的网络的训
练(节。3.6)。
识别. 与A-softmax损失类似[20],我们不-
将分类器的权重
W
平均化并忽略其偏置项(即
,
w
i
=
l
,
b
i
=
0
)。给定学习的特征向量
,
类别
c
处的
f
t
z
c
=
w
c
·
f
t
=
f
tcosθ
c
,
(
3
)
3.1.
框架和制定
给定图像序列
X
=
.
X
t
∈
R
h
×
w
×
c
Σ
T
其中
Z
=
。
z
t
不
E
∈
R
|
G
|
+1
Σ
T
不
是在软-
通过T图像,CSLR旨在学习
将图像序列变换为其对应的光泽度la-
最大激活函数,θ
c
表示
w
c
和
f
t
。基于提取的fea-
逐帧特征
视觉特征
连接时态分类
HEUTE NACHT FLUSS DREI
剩余10页未读,继续阅读
相关推荐



cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Verilog实现的Xilinx序列检测器设计教程
- 九度智能SEO优化软件新版发布,提升搜索引擎排名
- EssentialPIM Pro v11.0 便携修改版:全面个人信息管理与同步
- C#源代码的恶作剧外表答题器程序教程
- Weblogic集群配置与优化及常见问题解决方案
- Harvard Dataverse数据的Python Flask API教程
- DNS域名批量解析工具v1.31:功能提升与日志更新
- JavaScript前台表单验证技巧与实例解析
- FLAC二次开发实用论文资料汇总
- JavaScript项目开发实践:Front-Projeto-Final-PS-2019.2解析
- 76云保姆:迅雷云点播免费自动升级体验
- Android SQLite数据库增删改查操作详解
- HTML/CSS/JS基础模板:经典篮球学习项目
- 粒子群算法优化GARVER-6直流配网规划
- Windows版jemalloc内存分配器发布
- 实用强大QQ机器人,你值得拥有
