学习阈值的通用领域自适应:OVANet方法
PDF格式 | 1.52MB |
更新于2025-01-16
| 164 浏览量 | 举报
通用域自适应(UNDA)是一种研究领域的关键课题,它旨在解决两个数据集之间的领域转移和类别转移问题。在传统无监督域适应(UDA)的基础上,UNDA扩展了适应性范围,考虑了更广泛的情景,如开放集DA(ODA)和部分DA(PDA),其中目标域可能包含源域中未知的类别,或者源域包含目标域中未知的类别。这些情况导致了传统方法的局限性,因为它们依赖于预定义的阈值来区分已知和未知样本,这可能导致误判。
在本研究中,作者提出了OVANet(Open-Variate Auto-encoder Network),一个针对通用域自适应的方法。OVANet的核心创新在于它能够学习和自适应地调整阈值,而不是依赖于人工设定。这个框架的基石是利用源数据中的类间和类内距离信息。具体来说,通过为每个类别训练一个专用的分类器,OVANet能够捕捉不同类别间的区分度。接着,通过最小化类熵,使得这些分类器能够在目标域中进行适应,从而形成一个对超参数不敏感且性能强大的解决方案。
OVANet的独特之处在于其简单易用性,即使在没有关于目标域的先验知识时也能有效地工作。在实际应用中,获取大量标记数据的成本很高,因此,UNDA的设置对于减少标注需求具有显著的价值。然而,实现真正意义上的通用性并不容易,因为它需要处理类别转移的不确定性。作者强调,他们的方法在GitHub上的开源实现可以方便其他研究人员和实践者进一步探索和改进这一领域。
总结来说,OVANet为通用域自适应提供了一个新颖的、自动阈值调整的框架,通过学习源数据的特性来适应目标域,避免了手动阈值设置带来的潜在问题。这对于解决跨领域视觉识别任务中的未知样本处理具有重要的理论和实际意义。
9002
D ∪ DD
| | −
∈
{
|
|}
|
|
我
i
=1
我
i
=1
D
{}
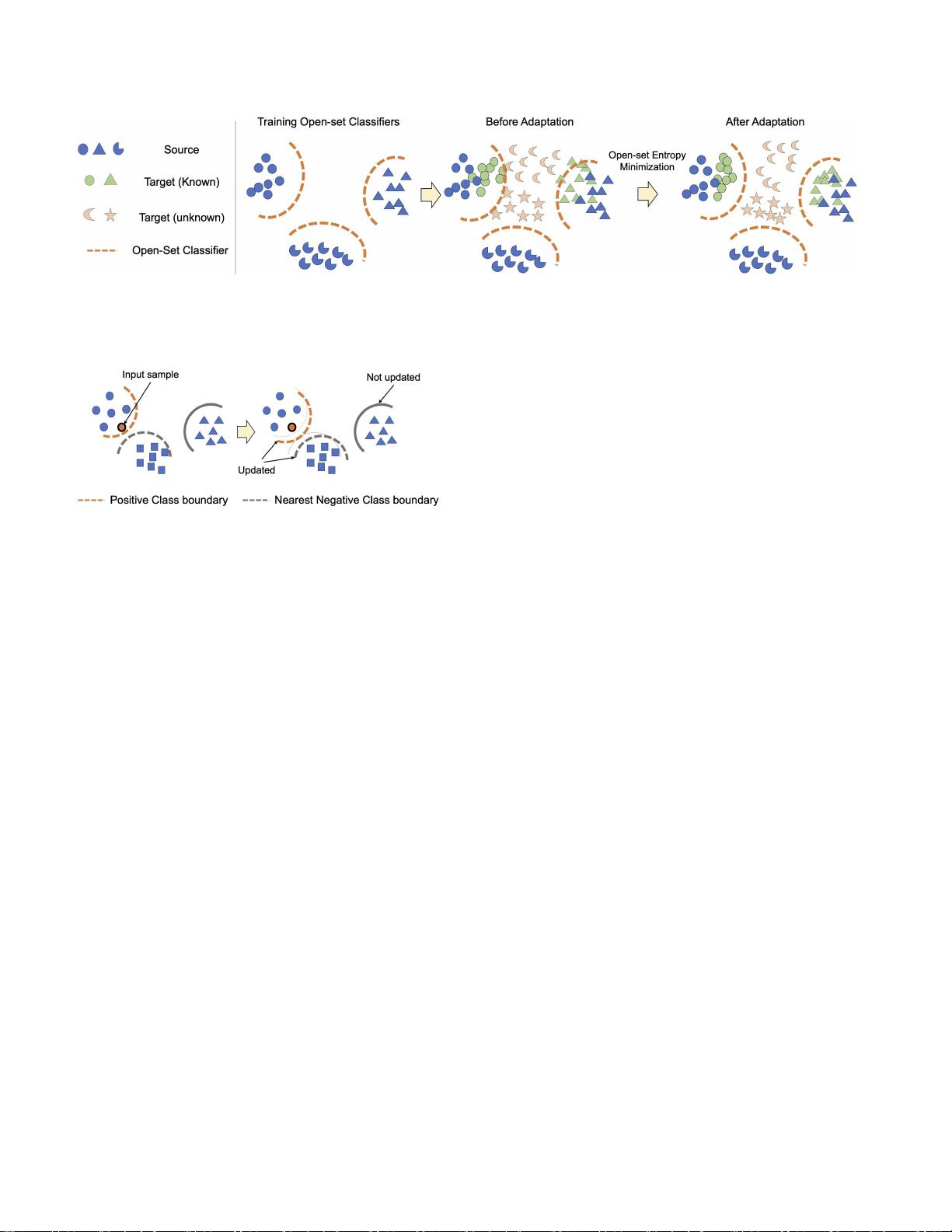
图2:
OVANet
的概念概述。开集分类器是在标记的源样本(最左边)上训练的,我们试图通过对未标记的目标样本(中间和
最右边)进行开集熵最小化来增加预测的置信度我们以一步一步的方式展示培训过程,以便更好地理解,但在实践中采用端到
端的培训。
3.
OVANet
图2介绍了OVANet的概念概述。我们的开集分类器
采用学习到的类别之间的距离来识别未知样本(Sec.
第3.1节)。学习的分类器通过开集熵最小化(Sec.
3.2)。
记法。
我们给出标记的源域
D
s
=
{(
x
s
,
y
i
s
)}
N
s
,具有
“
已知
”
类别
L s
和一个
非
样本中,更新正类边界和最近的负类边界。这是为了让分类
器学习正类和最近的负类之间的距离。我们假设,距离应该
是一个很好的阈值拒绝
cus如何建立更好的异常测量[2]或让模型学习有效区分
已知或未知样本的特征[36,25,20]。最近的工作表
明,对比学习对于学习适合于检测分布样本的表示是
有效的[31,35]。这些方法与现有的联合国裁军事务
厅和官方发展援助方法有一个共同的问题。确定未知
的阈值是经过验证的或预先确定的[10]。这些方法提
供了一种有效校准不确定性分数的度量或训练方法,
但仍然需要通过验证来确定相比之下,我们介绍了一
种技术,学习阈值使用标记的样本,而不需要验证。
采用One-vs-All(OVA)分类器将二元分类器应用
于多类分类[8],聚合二元分类器的输出。Padhy等人
[21]提出通过训练神经OVA分类器来处理分布外检测
与这项工作的一个关键区别是,我们通过让它们专注
于硬阴性样本来训练开集分类器。开集分类器需要区
分正样本和最近的负样本,以有效地识别未知样本。
我们提出的硬负采样在构建阈值方面是有效的,如第2
节所示。3.1和表4。
标记的目标域
t
=
(x
t
)
Nt
,
其包含我们的目标是用L
s
标
签或“未知”标签之一来标记目标样本我们训练模型
S
测试
和评估
t
.为了处理开集分类,我们引入两个分类
器:(1)开集分类器O,用于检测未知样本,以及
(2)闭集分类器C,用于将样本分类到L
个
标签中。C
被训练为利用标准分类损失对源样本进行分类,而O
被训练为利用下面解释的
硬负分类器采样
。在测试阶
段,C用于识别最近的已知类,而O用于确定样本是已
知还是未知。
3.1.
硬负分类器采样(HNCS)
我们的想法是训练一个分类器来学习每个类的内点
和离群点之间的边界。然后,我们为每个类训练线性
分类器。对于每个分类器,类被训练为正,而其他类
为负。关键是如何挑选阴性样本,即我们建议挑选与
该类别不同但与其相似的样本(硬负类别)。概述如
图所示。3 .第三章。
我们的开集分类器由L
s
个子分类器组成,即,O
j
,
j
1
,
…L
s
.每个分类器被训练以区分样本是否是对应类
的内点。子分类器输出2维向量,其中每个维度分别示
出样本是内点和离群点的概率。
Padhy等人[21]建议培训所有(
L
1
)nega- 的分类
器给出了训练样本,但我们观察到
图3:开集分类器训练概述。 为每个
剩余11页未读,继续阅读
相关推荐





cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Verilog实现的Xilinx序列检测器设计教程
- 九度智能SEO优化软件新版发布,提升搜索引擎排名
- EssentialPIM Pro v11.0 便携修改版:全面个人信息管理与同步
- C#源代码的恶作剧外表答题器程序教程
- Weblogic集群配置与优化及常见问题解决方案
- Harvard Dataverse数据的Python Flask API教程
- DNS域名批量解析工具v1.31:功能提升与日志更新
- JavaScript前台表单验证技巧与实例解析
- FLAC二次开发实用论文资料汇总
- JavaScript项目开发实践:Front-Projeto-Final-PS-2019.2解析
- 76云保姆:迅雷云点播免费自动升级体验
- Android SQLite数据库增删改查操作详解
- HTML/CSS/JS基础模板:经典篮球学习项目
- 粒子群算法优化GARVER-6直流配网规划
- Windows版jemalloc内存分配器发布
- 实用强大QQ机器人,你值得拥有
