SwapText: 图像场景文本转换的三阶段框架
128 浏览量
更新于2025-01-16
收藏 2.83MB PDF 举报
SwapText: 基于图像的场景文本传输是一种创新的解决方案,旨在解决在场景图像中实现文本交换的问题,同时保持原始字体、颜色、大小和背景纹理的一致性。该工作由阿里巴巴集团的研究者杨强鹏、黄军和林伟提出,他们构建了一个三阶段的框架,以克服文本交换中的核心挑战——生成视觉上真实且风格连贯的新文本。
首先,他们开发了一种新颖的文本交换网络,专注于在保持前景图像清晰的同时替换其中的文本。这种方法强调了局部操作,仅对需要改变的部分进行处理,减少了对整体图像质量的影响。这个网络设计可能是基于卷积神经网络(CNN)或者注意力机制,以便精确地定位和替换文本区域。
接着,为了恢复背景图像,研究团队引入了背景完成网络,这是一种学习型模型,它能根据替换后的前景图像重建出与原背景相匹配的细节。这种网络可能采用了条件生成模型,如条件GAN或条件VAE,它们能够根据特定的输入信息(如前景图像)生成相应的背景。
最后,将生成的前景图像与重构的背景结合, SwapText框架允许对输入图像中的文本进行无缝操控,即使存在严重的几何失真也能保持视觉一致性。这使得该技术在诸如文本检测、识别增强、海报制作和创意应用等领域具有潜力,特别是在数据增强和模型训练方面,尤其是针对那些依赖高质量标注图像的深度神经网络(DNN)模型。
对比传统的几何变换增强,如平移、旋转和翻转,以及基于图像合成的方法,SwapText通过更接近实际场景的图像转换,提高了模型的泛化能力和训练效率。例如,通过逼真的图像合成技术,如GAN,SwapText能够生成更贴近现实的文本图像,从而提升模型在面对实际应用场景时的表现。
该研究展示了在文本检测和识别任务中,基于图像的文本交换作为一种有效的数据增强手段,有助于打破训练数据不足的限制,并为未来在场景理解、图像编辑和智能交互等多个领域开辟了新的可能性。定量和定性的实验结果验证了SwapText在各种场景文本数据集上的有效性,包括规则和不规则文本,证明了其在实际应用中的价值。
14702
图
2.
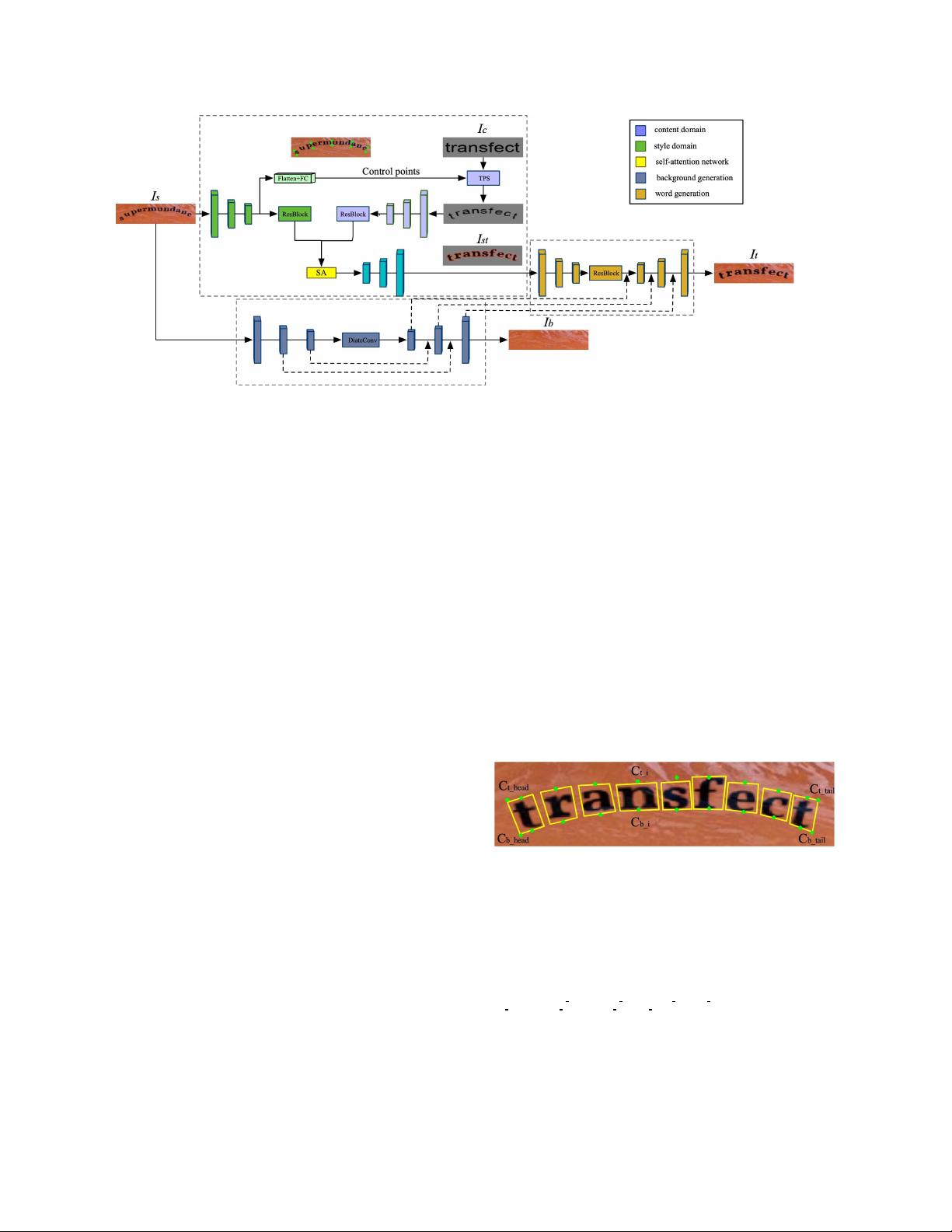
我们提出的方法的框架。它包含三个子网:文本交换网络、背景完成和融合网络。
最近,基于GAN的方法已经成为图像完成的一个有前
途的范例。Iizuka等人[9]建议使用全局和局部判别器
作为对抗性损失,其中全局和局部一致性都被强制执
行。Yu等人[38]使用上下文关注层来明确关注在遥远
空间位置处的相关特征Wang等人[33]采用多列网络并
行生成不同的图像分量,并采用隐式多样化MRF正则
化增强局部细节。
3.
方法
给定一个场景文本图像
Is
∈
RH×W×3
,我们的目标是在
保持原始风格的情况下,基于内容图像
Ic
∈
RH
×
W
×
3
如图
所示-
在图2中,我们的框架由文本交换网络、背景补全网络
和融合网络组成。文本交换网络首先从
Is
中提取风格
特征,从
Ic
中提取内容特征,然后通过自注意网络将这
两个特征结合起来。为了学习更好的内容表示,我们
使用内容形状变换网络(CSTO)根据样式图像
Is
的几
何属性来变换内容
图像
Ic
。背景补全网络用于重建样式
图像Is的原始背景图像Ib。最后,将文本交换网络和
背景补全网络的输出通过融合网络进行融合,生成最
终的文本图像。
3.1.
文本交换网络
真实场景中的文本实例具有不同的形状,例如呈水
平、定向或弯曲形式。文本交换网络的主要目的是替
换样式
图像
的内容,同时保持原始
样式,尤其是文本形状。为了提高不规则文本图像生
成 的 性 能 , 我 们 提 出 了 一 个 内 容 形 状 转 换 网 络
(CXN),以映射到相同的几何形状的样式图像的内
容图像。然后通过3个下采样卷积层和几个残差块对风
格图像和变换后的内容图像进行编码为了将风格和内
容特征充分结合起来,我们将它们输入一个自我注意
力网络。对于解码,使用3个上采样去卷积层来生成前
景图像
I
f
。
3.1.1
内容形状转换网络
文本形状的定义是内容形状转换的关键。受文本检测
[20]和文本识别[35]领域中文本形状定义的启发,文本
的几何属性可以用
2K
个
基准点
P
=
{
p
1
,
p
2
,
...
,
p
2
K
}
,如图
3
所示。
图3.文本形状定义的插图。
一个文本实例可以看作是一个有序的字符序列
T
=
{
C1
,
.
,
C
i
,
. C
n
},其中
n
是字符数。每个字符
C
i
都
有一个边界框
B
i
,该边界框
B i
用自由形式的四
边形进行注释。首先,我们构造两个中心点列表
C
top
=
{
CT
头
,
CT
1
,
.
,
C
t n
,
C
t tail
}和
C
bottom
=
{
Cb
头
,
Cb1
,
.
,
C
bn
,
C
btail
},其中包含顶部
每个
Bi
的
中心和底部中心。 然后我们平均
在
C
顶部
和
C
底部
中间隔采样
K
个基准点。为
剩余10页未读,继续阅读
点击了解资源详情
2015-06-07 上传
2025-03-06 上传
2025-03-06 上传
2025-03-06 上传
2025-03-06 上传

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全面详实的大学生电工实习报告汇总
- 利用极光推送实现App间的消息传递
- 基于JavaScript的节点天气网站开发教程
- 三星贴片机1+1SMT制程方案详细介绍
- PCA与SVM结合的机器学习分类方法
- 钱能版C++课后习题完整答案解析
- 拼音检索ListView:实现快速拼音排序功能
- 手机mp3音量提升神器:mp3Trim使用指南
- 《自动控制原理第二版》习题答案解析
- 广西移动数据库脚本文件详解
- 谭浩强C语言与C++教材PDF版下载
- 汽车电器及电子技术实验操作手册下载
- 2008通信定额概预算教程:快速入门指南
- 流行的表情打分评论特效:实现QQ风格互动
- 使用Winform实现GDI+图像处理与鼠标交互
- Python环境配置教程:安装Tkinter和TTk
