NI-Louvain: 社交网络中的影响力驱动社区检测算法
PDF格式 | 1.14MB |
更新于2025-01-16
| 184 浏览量 | 举报
"NI-Louvain:基于影响分析的社区检测算法研究"是一篇发表在沙特国王大学学报的计算机科学研究论文,主要探讨了社区发现这一在社交媒体挖掘领域中至关重要的课题。传统算法往往忽视了网络中每个节点对社区结构的影响,而这对于准确识别社区特性至关重要。作者Dipika Singha和Rakhi Garg针对这一问题提出了一个新的算法——NI-Louvain。
NI-Louvain算法的核心在于它考虑了每个节点在群体中的影响力,不仅聚焦于社区划分,还试图确定每个社区内的主导节点。算法分为三个步骤:首先,通过降低图的密度来简化处理,通过集团划分来实现;接着,采用Louvain的多级算法对简化后的图进行社区检测,这种方法在模块化值上表现出色,超越了诸如边缘介数、标签传播、领先特征、Louvain、快速贪婪、walktrap和信息地图等现有算法。
在第三步,算法将处理后的结果社区映射回原始图的节点,这样可以更好地识别重叠社区、每个节点模糊的社区归属,以及每个社区内的最具影响力节点,甚至能检测到离群节点。这种对节点影响力的关注使得NI-Louvain在复杂社交网络中展现了更强的适应性和准确性。
文章的背景指出,随着互联网的普及和社交网络的盛行,社区检测技术的应用范围广泛,如推荐系统、用户行为分析等。然而,NI-Louvain的独特贡献在于其对节点影响力因素的整合,这无疑提升了社区检测的精确性和有效性。
该研究论文于2021年发布,并遵循了Creative Commons Attribution-NonCommercial-NoDerivatives (CC BY-NC-ND) 4.0许可协议,这意味着读者可以自由地访问和分享文章,但不允许商业使用或修改内容。整体而言,NI-Louvain算法是一项创新的工作,对理解社交网络中的社区结构和节点角色具有重要意义。"
D. Singh
和
R. Garg
沙特国王大学学报
7767
-
X
.
Q
.
Σ
¼
--——
;
; ;
.
Σ
学习方法(Wang等人,2018年)
。
Hosseeini和Rezvanian提出了基于
标签传播和蚁群优化的AntLP算法(Hosseini和Rezvanian,2020)。
Feng提出了一种鲸鱼优化算法EP-WOCD。该算法基于增强的鲸鱼种群
行为,以克服数据大小对算法时间复杂度的影响(Feng 例如, 2020
年)。
3.
预赛
社区检测需要对图及其性质有基本的了解。本节描述了重要的术
语,这些术语对于理解我们的社区检测新方法至关重要,如图所示。1 .
一、
图G=(V,E)是顶点V={v
1
,v
2
................................................
v
n
}的集
合,
边
E= {
e1
,
e2
,
e
n
}
。每个边都包含一个有序的
con
对,
连接的顶点社交网络可以被视为现实世界中的图形,以人为节点,以他
们的互动为边(Akhtar和Ahamad,2021)。
一个社区可以简单地定义为图G的一个子图,它的簇内边比簇间边多
(Lancichinetti and Quinato,2009)。例如,在社会网络中,一个
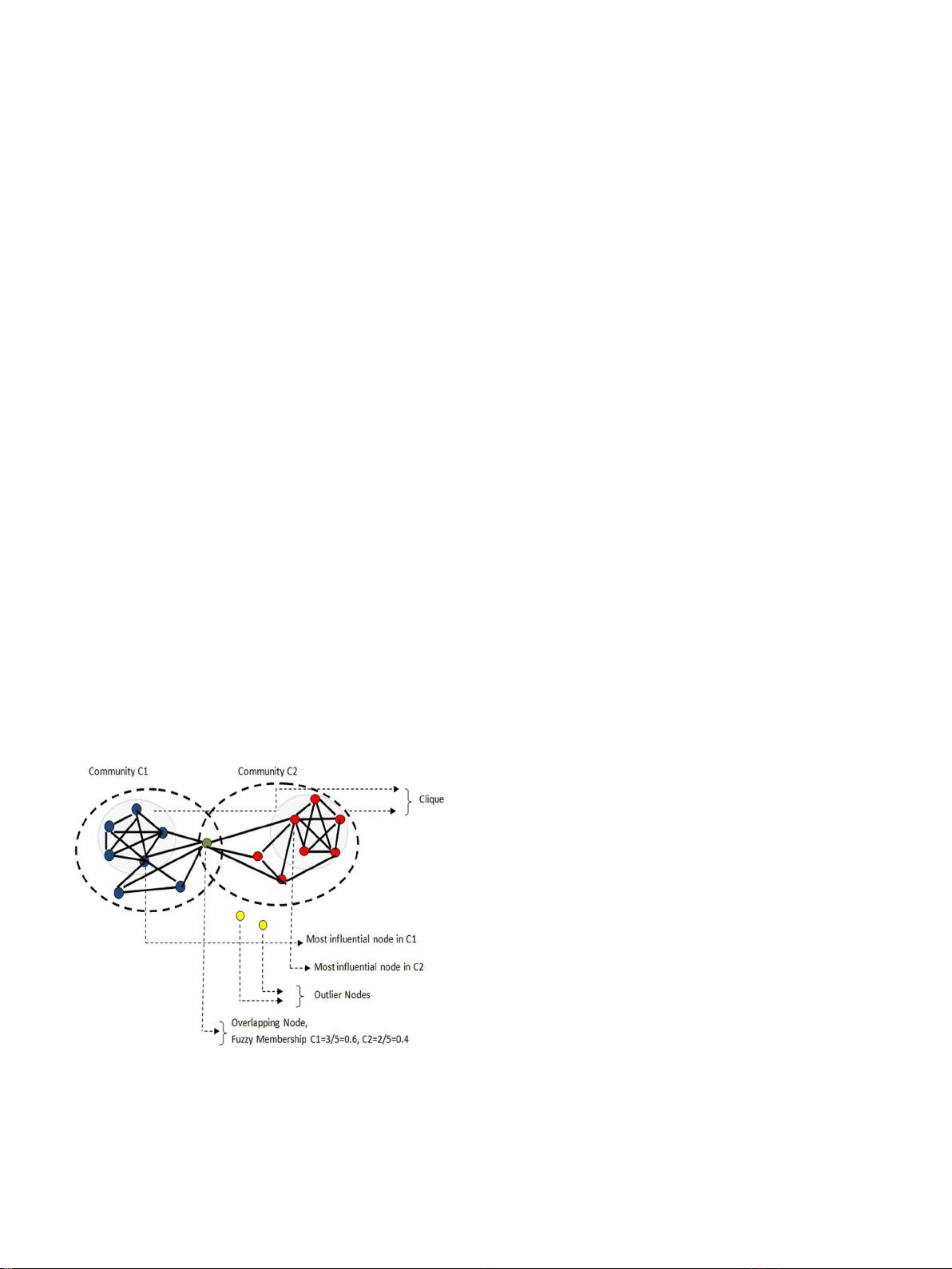
社区将由一群人组成,他们之间的互动比其他人更 多 ,如图 所示。1.
一、
模 块 化 是 计 算 网 络 划 分 为 模 块 的 强 度 的 最 流 行 的 度 量 之 一
(
Zhang
和
Chen
,
2018
)。模块化得分高表明社区内部的连接较密
集,社区外部的连接较稀疏模块范围从
1
到
1
。
它被计算为落在组内的边与随机分布中的预期边的差。模块化由
Newman引入(Newman,2006 a; Newman,2006 b)。其定义如等
式中所示。(一).
2
我
这里
e
ii
表示网络中连接簇
i
中顶点的边的分数,
ai
表示随机网络中
来自或去往组
i
的边。
通常预期值范围为
0.3
至
0.7
。模块度优化是各种通信检测算法的
基础
图密度可以被定义为图中的边的数量与具有相同数量的节点的完
整图中的边的数量的比率(
Danisch
等人,
2017
年)。一个图可以
是稠密的或稀疏的,这取决于它的边的数量。
Fig. 1.
社区在一个图。
由图形成的社区可以称为不相交或重叠。一个不相交的社区是一
个其中每个节点只属于一个社区 另一方面,在重叠社区中,节点可
以同时属于多个社区(
Xie
等人,
2013
年)。 在现实世界中,大多
数社区是重叠的,因为一个人可以同时是许多社区的成员,如图所
示。
1 .
一、
节点的成员资格表示其对特定社区的归属性成员资格可以是清晰
的或模糊的。一个清晰的成员只能有两个值,
0
和
1.
这意味着节点可
以属于社区或不属于社区,分别用
1
和
0
表示。另一方面,模糊隶属
度考虑了特定社区中重叠节点的相似性强度(
Mahajan
和
Gupta
,
2021
)。根据节点对特定社区的参与程度,模糊优先级的值范围从
0
到
1
,如图
1
所示。在图
1
中,蓝色节点只属于社区
C1
,因此它们的成
员资格为
C1 = 1
和
C2 = 0
。同样,红色节点只属于社区
C2
,因此它
们的成员资格对于
C2 = 1
,对于
C1 = 0
。另一方面,绿色节点是重叠
节点,属于
C1
和
C2
。在社区
C1
中,它是三个
3
集团的成员,在社区
C2
中,它是两个
3
集团的成员因此,模糊隶属度可以计算为
C1 = 3/5
= 0.6
和
C2 = 2/5 = 0.4
。
一个社区由几个节点组成。每个节点在社区中的参与程度不同,这
被称为影响力。最有影响力的节点是连接到组中大多数其他节点的节
点,如图1所示。另一方面,影响力较小的节点将具有较少的连接节点
(Peng等人,2018年)。影响分析对于获得更合理的社区检测结果至
关重要。
图的离群节点是那些不属于 任何社区(Domingues等人,2018
年)。这是因为他们较少参与社区的互动,这使他们处于社区之外,如
图1所示。在图1中,黄色节点是离群节点。离群值检测有助于检测社区
中的异常情况。
团是图的完全子图(Luo,2018)。例如,5clique表示其中5个节点
彼此连接的子图,如图2所示。1.一、
4.
该方法
在这一节中,我们将讨论我们提出的算法的问题陈述和详细描
述。
4.1.
问题陈述
对
任意图
G=
(
V
,
E
)
,
其中V
v
1
v
2
v
3
;
v
n
是
顶
点的集合,
并且
E1/4
e1
;
e2
;
e3
;
-;
ej
是边的集合,所考虑的现有
社区检测
算法形成社区
,使得如果
Ci
和
Cj
是所形成的任何两个社区
,
则对于所
有
i-j
, 这表明两个社区
不共享任何顶点,即只检测不相交的社区
此
外,离群节点,节点的模糊隶属度,节点的影响力也没有得到。
4.2.
该算法
在这一节中,我们提出了一种新的算法,该算法可以检测出具有
模糊成员关系的重叠社区,离群节点和社区中最有影响力的节点。此
外,该算法形成的社区
剩余11页未读,继续阅读
相关推荐





cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 网页自动刷新工具 v1.1 - 自定义时间间隔与关机
- pt-1.4协程源码深度解析
- EP4CE6E22C8芯片三相正弦波发生器设计与实现
- 高效处理超大XML文件的查看工具介绍
- 64K极限挑战:国际程序设计大赛优秀3D作品展
- ENVI软件全面应用教程指南
- 学生档案管理系统设计与开发
- 网络伪书:社区驱动的在线音乐制图平台
- Lettuce 5.0.3中文API文档完整包下载指南
- 雅虎通Yahoo! Messenger v0.8.115即时聊天功能详解
- 将Android手机转变为IP监控摄像机
- PLSQL入门教程:变量声明与程序交互
- 掌握.NET三层架构:实例学习与源码解析
- WPF中Devexpress GridControl分组功能实例分析
- H3Viewer: VS2010专用高效帮助文档查看工具
- STM32CubeMX LED与按键初始化及外部中断处理教程
