参数化俯视模型解析复杂道路布局:深度学习驱动的场景理解
176 浏览量
更新于2025-01-16
收藏 1.55MB PDF 举报
本文主要探讨了复杂道路场景的参数化俯视表示在自动驾驶和机器人导航等领域的应用。作者提出了一种创新的模型,旨在从单个摄像头的输入中推断出道路布局,这种表示不仅直观易懂,还提供了一种可解释的高层次决策框架。该模型强调了参数化的道路布局表示,通过定义车道数量、宽度、不同类型的交叉口、人行横道和人行道等关键特征,使模型更具可解释性和对下游应用的友好性。
在模型设计方面,作者采用了监督域自适应技术,结合模拟数据和人工标注的数据,以训练深度神经网络进行场景模型的推断。这种方法旨在提高模型的泛化能力,使其能在实际复杂场景中表现出色。此外,他们引入了条件随机场(CRF)来增强预测的连贯性和时间平滑性,确保视频帧之间的逻辑一致性,生成语义清晰的结果。
实验结果表明,该参数化俯视图模型在两个公开数据集上展现了良好的性能:
1. 能够有效地描述复杂道路场景的细节和结构;
2. 比单纯依赖手动标注或模拟数据训练的基线方法表现更优,实现了精度和效率的双重提升;
3. CRF的运用显著提升了视频序列的连续性和理解力,为实时的自动驾驶决策提供了有力支持。
这项工作通过参数化俯视表示和结合多种训练策略,推进了对复杂道路场景的理解和建模,对于提升基于深度学习的自动驾驶系统的性能具有重要意义。同时,该研究也展示了将非参数化场景表示转换为参数化形式在高级决策和解释性方面的潜力。
10327
i
=1
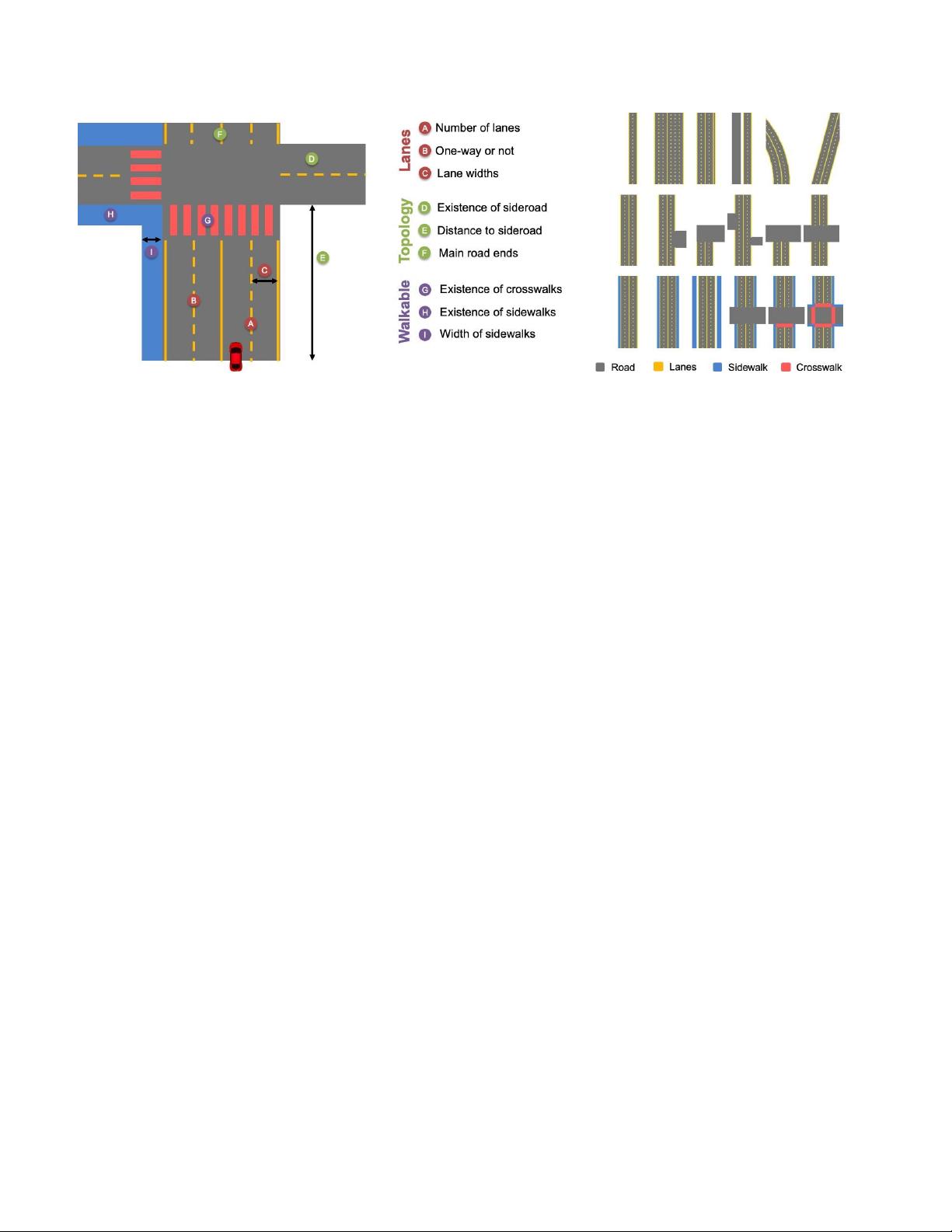
图2:我们的场景模型由几个参数组成,可以捕捉各种复杂的驾驶场景。(左)我们展示了模型并突出显示了重要
参数(A-I),这些参数分为三类(中):
车道
,用于描述单个道路的布局;
拓扑
,用于对各种道路拓扑进行建模;
步行
,用于描述行人的场景元素我们的模型被定义为一个有向的非循环图,使有效的采样,并表示在顶视图,使
渲染容易。这些属性使我们的模型成为语义顶视图的模拟器(右)我们展示了上述各组的渲染示例补充资料中给
出了场景参数和相应图形模型的完整列表
我们的工作的贡献,在第二节中描述。3.3是一个深度
学习框架,它利用来自真实和模拟两个领域的训练数
据来推断我们提出的场景模型的参数。最后,我们的
第三个贡献是一个条件随机场(CRF),它加强了我
们的场景模型的相关参数之间的一致性,并鼓励视频
输入的时间平滑性,见第二节。三点四分。
3.1.
场景模型
我们的模型描述了道路场景的语义顶视图表示,我
们假设相机是在底部中心的每一帧。这允许我们相对
于相机定位所有在更高的层次上,我们区分了所有道
路至少由一条车道组成,交叉口由多条道路组成图2给
出了我们提出的模型的概述。
定义两条辅路(一条在主路的左侧,一条在主路的
右侧)以及到每条辅路的距离,使我们能够灵活地建
模3路和4路交叉口。另一个属性确定主要道路是否在
交叉点后结束,这将产生T形交叉点。
将一组参数θ分成不同的类型,计
Mb
=
14个二元变量
Θ
b
,
Mm
=
2个多类变量Θ
m
和
Mc
=
22个连续变量Θ
c
。补
充材料包含我们的模型参数的完整列表请注意,使用
简单模拟器的能力意味着我们可以轻松地使用更多参
数和关系扩展场景模型
3.2.
根据真实和模拟数据进行监控
从 RGB 图 像 推 断 模 型 Seff 和 Xiao [24] 利 用
OpenStreetMaps [19]收集RGB 图像的地面实况。虽然
这可以在给定GPS坐标的情况下自动完成,但可检索
的属性集是有限的,并且可能有噪声。相反,我们利
用手动注释和模拟的组合进行训练。
真实数据:只有在使用合适的工具时,才能有效地使
用与我们定义的参数相对应的属性来注释真实图像。
对于顺序数据尤其如此,因为许多属性在很长一段时
间内保持不变。补充材料包含有关我们的注释工具和
过程的详细信息我们有
主干道由一组车道组成,一条或两条-
收集数据集
D
r
=
{x
r
,
Θ
r
}
N
r
的
N
r
个样本,
道路交通、分隔符和人行道。我们还在相机的左侧和
右侧定义了多达六个通道,这些通道占据了自我通
道。我们允许不同的车道宽度来模拟特殊车道,如转
弯车道或自行车道。在最外面的车道旁边,一定宽度
的可选分隔符将道路与可选人行道分开。在交叉口,
我们还模拟了所有四个潜在侧的人行横道的存在。对
于辅路,我们仅对其宽度建模。我方最后
语 义 顶 视 图
Xr
和 对 应 的 场 景 属 性
Θ
r
。 语 义 俯 视 图
xr
∈
RH
×
W
×
C
,
空 间 维 度
为
H×W ,包 含 C 个 语义 范 畴
(“道路”、“人行道”、“车道边界”和“人行横道”),
应用[23]的框架计算然而,真实数据会出现一些问题首
先,对于每个RGB图像,要求地面实况深度处于合理
的密度,以要求人类可靠地估计到场景元素的距离,
如
剩余11页未读,继续阅读
624 浏览量
119 浏览量
157 浏览量
174 浏览量
点击了解资源详情
点击了解资源详情
884 浏览量
517 浏览量

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机组成原理期末试题及答案(2011参考)
- 均值漂移算法深入解析及实践应用
- 掌握npm与yarn在React和pg库中的使用
- C++开发学生信息管理系统实现多功能查询
- 深入解析SIMATIC NET OPC服务器与PLC的S7连接技术
- 离心式水泵原理与Matlab仿真教程
- 实现JS星级评论打分与滑动提示效果
- VB.NET图书馆管理系统源码及程序发布
- C#实现程序A监控与自动启动机制
- 构建简易Android拨号功能的应用开发教程
- HTML技术在在线杂志中的应用
- 网页开发中的实用树形菜单插件应用
- 高压水清洗技术在储罐维修中的关键应用
- 流量计校正方法及操作指南
- WinCE系统下SD卡磁盘性能测试工具及代码解析
- ASP.NET学生管理系统的源码与数据库教程
