隐式样本扩展:一种高效的无监督身份识别方法
PDF格式 | 893KB |
更新于2025-01-16
| 31 浏览量 | 举报
隐式样本扩展:一种无监督身份识别方法
在无监督身份识别中,隐式样本扩展(ISE)是一种有效的方法,它通过生成支持样本周围的集群边界来提高Re-ID性能。该方法可以减少“子和混合”聚类错误,从而提高Re-ID性能。
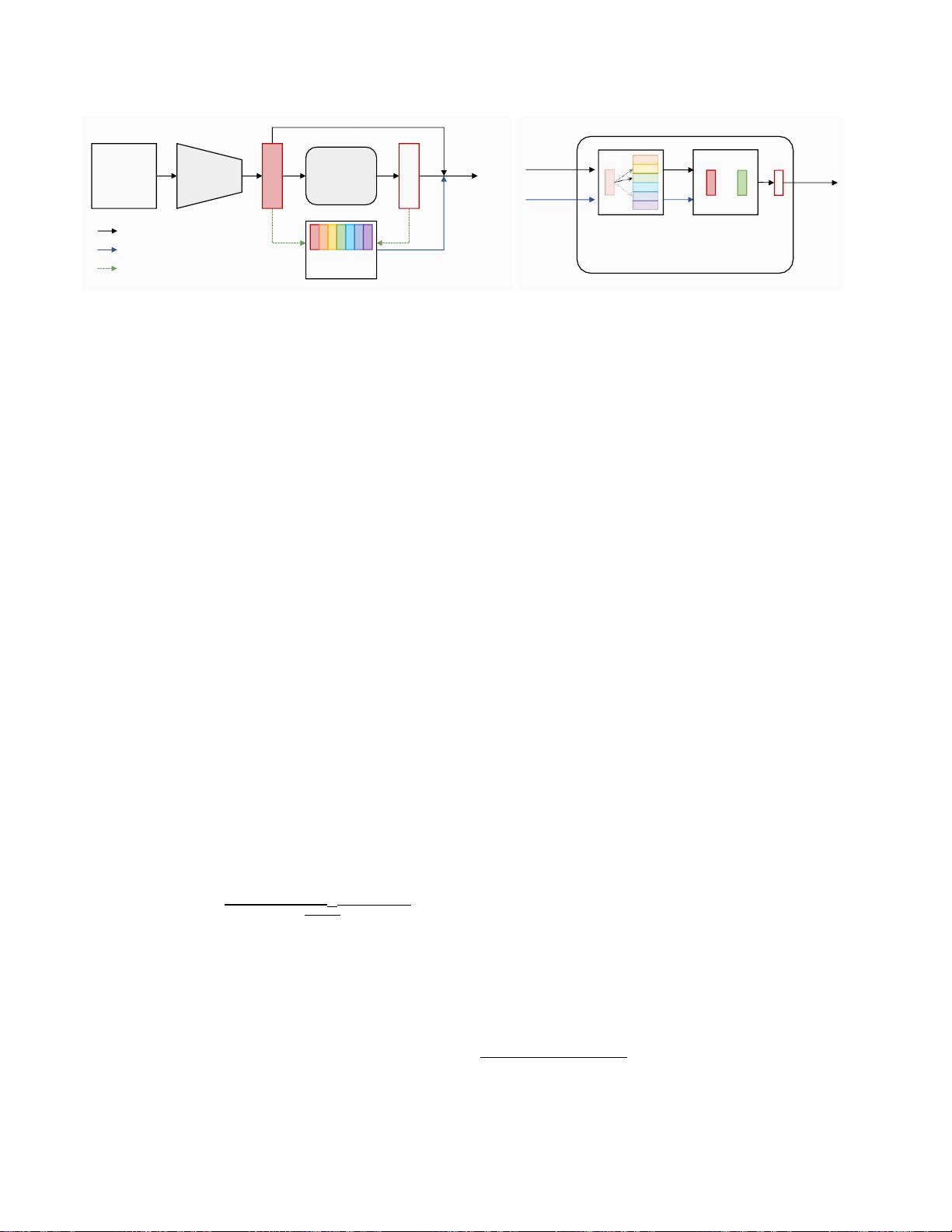
ISE方法的关键在于使用渐进线性插值(PLI)策略来生成支持样本。PLI策略控制着两个关键因素:1) 从实际样本朝向其K-最近聚类的方向,以及2)用于混合来自K-最近聚类的上下文信息的程度。同时,ISE进一步使用标签保持损失将支持样本拉向其对应的实际样本,以便压缩每个聚类。
无监督身份识别的挑战在于聚类算法可能将不同的真实身份混合在一起,或者将同一身份分裂成两个或多个子聚类。ISE方法可以解决这个问题,通过生成支持样本来揭示准确的聚类。
在Re-ID任务中,ISE方法可以与聚类算法结合使用,以生成高质量的伪标签。实验结果表明,ISE方法可以提高Re-ID性能,并达到了最先进的性能。
ISE方法的优点在于:
1. 减少“子和混合”聚类错误,从而提高Re-ID性能。
2. 可以与聚类算法结合使用,以生成高质量的伪标签。
3. 可以提高Re-ID性能,并达到了最先进的性能。
ISE方法的应用前景广泛,包括人脸识别、图像分类、自然语言处理等领域。ISE方法是一种有效的无监督身份识别方法,能够提高Re-ID性能,并具有广泛的应用前景。
知识点:
1. 隐式样本扩展(ISE):一种无监督身份识别方法,通过生成支持样本周围的集群边界来提高Re-ID性能。
2. 渐进线性插值(PLI)策略:一种用于生成支持样本的策略,控制着两个关键因素:1) 从实际样本朝向其K-最近聚类的方向,以及2)用于混合来自K-最近聚类的上下文信息的程度。
3. 无监督身份识别(Re-ID):旨在学习没有注释的人的外观特征,通过聚类算法生成高质量的伪标签。
4. 聚类算法:一种用于生成伪标签的算法,可能将不同的真实身份混合在一起,或者将同一身份分裂成两个或多个子聚类。
5. 支持样本:通过ISE方法生成的样本,周围的集群边界,用于提高Re-ID性能。
6. 标签保持损失:一种用于将支持样本拉向其对应的实际样本的损失函数,以便压缩每个聚类。
7. 子和混合聚类错误:一种聚类算法可能出现的错误,ISE方法可以减少这种错误。
ISE方法是一种有效的无监督身份识别方法,能够提高Re-ID性能,并具有广泛的应用前景。
7371
˜
·
-
-
联系 我们
∈
Σ
∈
|| || || ||
CNN
PLI
(
)
*
(
向前和向后仅向前
仅用于更新
{c
c
}
C
&
c%
0
3
0
图像
0
0
0
3
1
∗
{1
c
}
C
c%&
方向:学位:
/-最近的渐进邻居聚类更新λ
+ λ
(a)
整体隐式样本扩展流水线(ISE)(b)渐进线性插值(PLI)
图
2.
概述(
a
)整体隐式样本扩展流水线(
ISE
)和(
b
)渐进线性插值(
PLI
)策略的细节。 对于一个特定的样本特征f,我们
应用PLI生成支持样本f,用于优化模型
的样本扩展损失
L
SE
和标签保持损失
L
LP
。在生成过程中,
PLI
寻找
K-
最近聚类中心
c
λ
作为生成
方向
,并采用渐进更新的λ来控制生成
度
。更多细节见算法1。
保持方案(LP)。
3.1.
初步
设
X=
x1
,
x2
,
...
,
x
N
表示未标记的
Re-ID
数据集,
其中
x
i
是第
i
个图像,
N
是总图像数。在
USL Re-ID
任务中,我们的目标是训练一个深度神经网络
f
θ
(),将图像从数据点空间
X
投影到嵌入空间
F
中。
给定一个特定的样本
x
,
f
θ
(
x
)是从模型中提取的
特征这里 我们省略了模型参数
θ
,并使用
f=
f
(
x
)
作为特征嵌入。
f
∈
Rd
是
d
维向量
.
最近基于聚类的USL Re-ID方法[4,8,
9
,
13
,
14
,
30
,
31
,
43
,
50]
利用
K-means [22]
或
DB-SCAN [12]
为未标记的样本分配伪标签
。 然
后,我们得到一个
“标记”数据集X
′
=
(x
1
,
y
1
)
,
(x
2
,
y
2
)
,
.
,
(x
N
′
,
y
N
′
)
,其中
y
是
1
、
.
-
是的
-
是的得双曲
余切值
.
是第i个选定图像的伪标签,C是第i个选定图像的伪标
签。
总群集数。 这里有N
’
个
图像具有有效的伪
标签,而其
他图像被忽略。利用
X
′
,我们可以
在监督学习的形式
下对模型进行优化。同一类中的项目被认为是同一个
人,作为阳性样本。其他在不同的集群是消极的。基
于此,现有方法[9,14,31,50]采用InfoNCE损失函
数[23]进行模型训练。尽管在不同的方法中有不同的
变体,我们将损失函数总结为一般公式:
L
=
−
log
exp
(
sim
(
f
·
m
+
)
/τ
)
,
(
1
)
形成具有簇心的存储体M
R
d×C
。这里M等于簇号C。
同时,这些方法还设计了各种通常,它们采用动量
更新策略,其公式如下:
m<
$µ
·
m
+
(
1−
µ)
·
f
,
(2)
其中f是与存储器条目m具有相同身份的编码特征。具
体地,
f
在[14,50]中用于更新其自己的实例条目,而
在[9,31]中用于更新其 自 己的集群条 目 。Chronter-
Contrast [9]进一步使用批量最难样本进行内存更新
1
。
在本文中,我们遵循Cluster-Contrast [9]来建立我们
的基线
,其中内存库由集群质心构建,并且一个小批
次中的最难/每个样本用于内存更新。详细的训练设置
和与聚类对比度的差异在第节中描述。四点二。
3.2.
渐进线性插值
然而,上述基于聚类的USL人员Re-ID方法仍然遭受
子聚类和混合聚类。我们假设嵌入空间中潜在的缺失
信息导致不准确的聚类。我们的假设在于,聚类质量
可以在下一步中通过涉及更丰富的信息来提高,如第2
节所述。1.一、基于这种动机,我们提出了一种
渐进
线性插值
(PLI)方法如下。
给定一个样本特征f,我们生成其对应的
信息
M
m=1
exp
(
sim
(f
·
m
m
)
/τ)
F
通过线性内插操作
来
支持样本
f
其中m
m
是存储体M的第m个条目,并且
f
=
f
+
λ
f
,
(
3
)
m
+
与
f
共享
相同
的伪标号。
sim
(
u
,
v
)
=
u
T
v
/
u
v
表示两个
向量
u
和
v
之间的余弦相似性
。 一些方法
[14
,
50]
用实例(
aka.
样品)特征。 这样,
M
可以
是整个样本数
N
或小批量B。其他方法[9,31]交替
其中
λf
控制
方向
,
λ
控制
度
,这是样本扩展过程中的
两个重要因素
。从有问题的集群的角度来看,
1
[9]更改为在更新版本中使用minibatch中的每个样本进行动量更
新。
剩余10页未读,继续阅读
相关推荐




cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 网狐工具:核心DLL和程序文件解析
- PortfolioCVphp - 展示JavaScript技能的个人作品集
- 手机归属地查询网站完整项目:HTML+PHP源码及数据集
- 昆仑通态MCGS通用版S7400父设备驱动包下载
- 手机QQ登录工具的压缩包内容解析
- Git基础学习仓库:掌握版本控制要点
- 3322动态域名更新器使用教程与下载
- iOS源码开发:温度转换应用简易教程
- 定制化用户登录页面模板设计指南
- SMAC电机在包装生产线应用的技术案例分析
- Silverlight 5实现COM组件调用无需OOB技术
- C#实现多功能画图板:画直线、矩形、圆等
- 深入探讨C#语言在WPF项目开发中的应用
- 新版2012109通用权限系统源码发布:多角色用户支持
- 计算机科学与工程系网站开发技术源码合集
- Java实现简易导出Excel工具的开发教程
