自我监督学习中的视频着色可改善视觉跟踪,通过颜色的时间相干性,模型能在没有地面真实标签的情况下训练,效果优于基于光流的方法
PDF格式 | 1.5MB |
更新于2025-01-16
| 181 浏览量 | 举报

通过对视频进行
Carl Vondrick,Abhinav Shrivastava,Alireza
Fathi,Sergio Guadarrama,Kevin Murphy
Google Research
抽象。 我们使用大量未标记的视频来学习视觉跟踪模型,
而
无需人工监督。 我们利用颜色的
自然时间相干性来创建一个
模型,该
模型通过从参考帧复制颜色来学习对灰度视频进行
着色。 定量
和定性实验表明,该任务导致模型
自动学习跟踪
视觉区域。 虽然模型是在
没有任何地面真实标签的情况下训
练的,但我们的方法学习跟踪得足够好,优于基于光流的最
新方法。此外,我们的研究结果表明,跟踪失败与
着色
失
败相关,这表明推进视频着色可以进一步改善自我监督的
视觉跟踪。
关键词:彩色化,自监督学习,跟踪,视频
1
介绍
视觉跟踪是跨识别、几何和交互的视频分析任务不可或缺的部分然
而,收集高性能所需的大规模跟踪数据集通常需要不切实际且昂贵的
大量工作。我们认为一种有前途的方法是在没有人类监督的情况下学
习跟踪,而是利用大量原始的、未标记的视频。
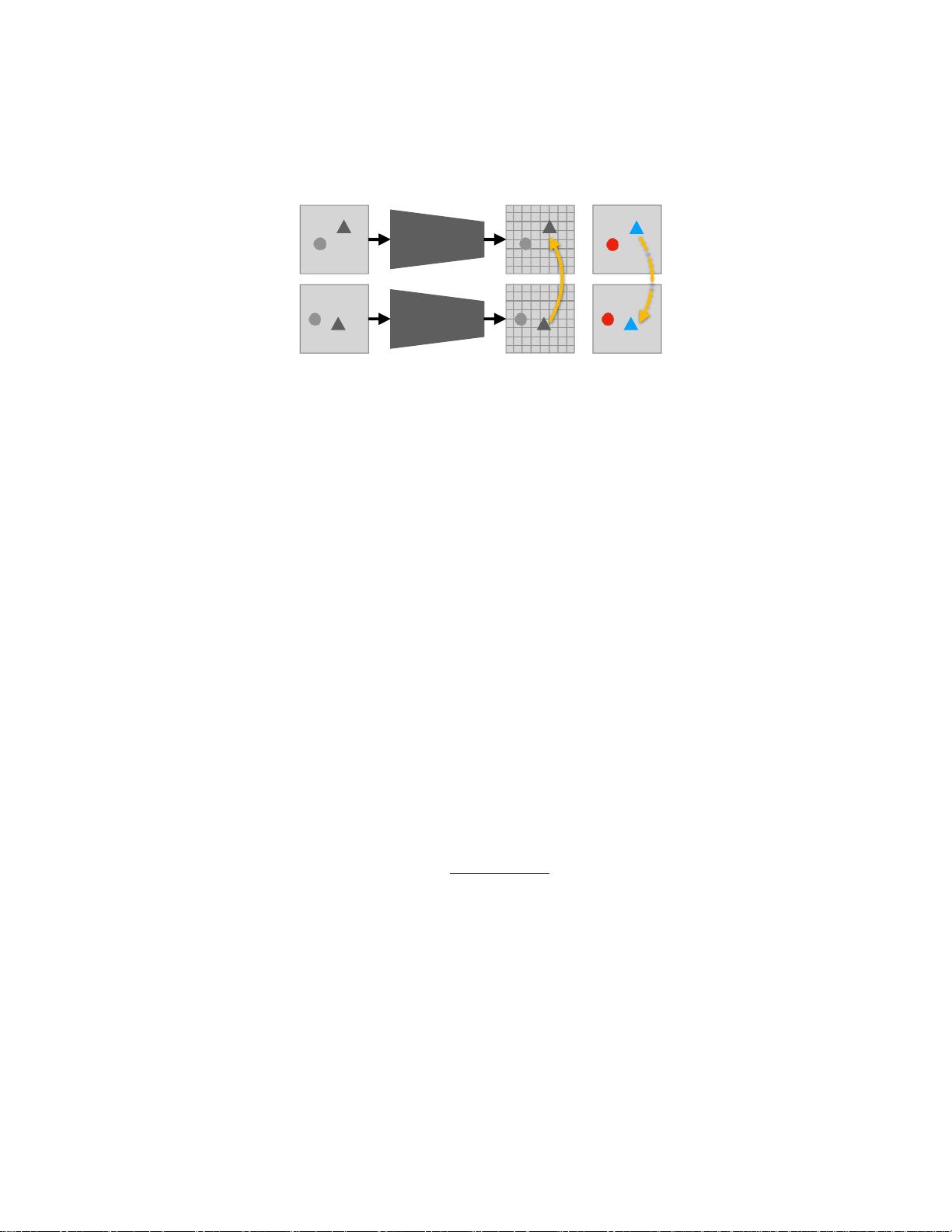
我们提出视频着色作为一个自我监督学习问题的视觉跟踪。然
而,我们不是试图直接从灰度帧预测颜色,而是通过学习从参考帧复
制颜色来约束着色模型来解决这个任务虽然这看起来可能是一种迂回
的方式来着色视频,但它需要模型学习内部指向正确的区域,以便复
制正确的颜色。一旦模型被训练,
学习的“预测”机制就被实现为一种
训练策略
。
图
1将使用
我们的问题设置。
实验和可视化表明,尽管网络是在没有真实标签的情况下训练
的,但自动跟踪的机制出现了。在对从网络上收集的未标记视频进行
训练后[1],该模型能够跟踪视频的第一帧中指定的任何分割区域
[2]。它还可以虽然仍然没有干净标记的监督数据的替代品,但我们的
彩色化模型能够很好地跟踪视频片段和人体姿势,从而优于基于光流
的最新方法按运动类型划分的分解性能


剩余17页未读,继续阅读
相关推荐




cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Openaea:Unity下开源fanmad-aea游戏开发
- Eclipse中实用的Maven3插件指南
- 批量查询软件发布:轻松掌握搜索引擎下拉关键词
- 《C#技术内幕》源代码解析与学习指南
- Carmon广义切比雪夫滤波器综合与耦合矩阵分析
- C++在MFC框架下实时采集Kinect深度及彩色图像
- 代码研究员的Markdown阅读笔记解析
- 基于TCP/UDP的数据采集与端口监听系统
- 探索CDirDialog:高效的文件路径选择对话框
- PIC24单片机开发全攻略:原理与编程指南
- 实现文字焦点切换特效与滤镜滚动效果的JavaScript代码
- Flask API入门教程:快速设置与运行
- Matlab实现的说话人识别和确认系统
- 全面操作OpenFlight格式的API安装指南
- 基于C++的书店管理系统课程设计与源码解析
- Apache Tomcat 7.0.42版本压缩包发布
