自正则化与多样性的全自动视频着色技术
PDF格式 | 2.12MB |
更新于2025-01-16
| 144 浏览量 | 举报
"该文提出了一种全新的全自动视频着色方法,强调了自正则化和多样性的关键特性。该模型由彩色化网络和时空颜色细化网络构成,能够在没有标注数据的情况下,通过双边损失和时间损失来保持颜色的一致性和时间上的连贯性。此外,感知损失的多样性用于处理多模态解决方案空间,以产生自然的彩色结果。文章还对比了该方法与现有图像着色技术的差异,并展示了在经典黑白电影着色上的优秀表现。"
在视频彩色化领域,由于其固有的多模态性质和对全局时空一致性的要求,一直以来都是一个极具挑战性的问题。传统的图像和视频彩色化方法大多依赖于用户引导或特定的颜色传播算法,但这些方法往往需要大量的人工干预,或者在结果中产生不自然的色彩分布。
近年来,深度学习技术的发展为自动化图像和视频着色提供了新的可能。然而,现有的深度学习模型在处理视频时,常常无法有效地保持时间一致性,导致色彩在不同帧之间跳跃不连续。此外,基于分类的损失函数可能导致色彩的离散化伪影,降低了图像的真实感。
针对这些问题,文中提出的全自动视频着色方法引入了自正则化机制,通过双边损失来强制像素间在双边空间内的颜色一致性,以增强空间色彩连贯性。同时,时间损失则确保了相邻帧中对应像素的颜色一致性,从而增强了时间连贯性。这种方法在无监督的环境下进行训练,无需额外的标注数据。
更重要的是,为了解决彩色化过程中的多模态问题,即同一物体可能存在多种合理颜色,作者采用了感知损失的多样性策略。这使得模型能够探索并生成多种可能的、看起来自然的彩色结果,而非仅仅局限于单一的“正确”颜色。这种多样性不仅增加了结果的自然感,还避免了基于离散颜色采样的方法可能导致的伪影问题。
在实际应用中,如视觉理解和对象跟踪,高质量的视频彩色化能够提供更为丰富的视觉信息,提高这些任务的性能。通过对比实验,该方法被证明在全自动视频彩色化方面超越了当前的先进技术,尤其是在经典黑白电影的彩色化上,显示出了显著的优势。
该文提出的全自动视频着色方法结合了自正则化、多样性和时间一致性,为视频彩色化提供了一种高效且自然的解决方案,为后续的相关研究和应用开发奠定了坚实的基础。
3755
经纱
(a1)帧
(
d1
)():
帧t的第
i
(
d3
)
(e1)置信度图
for()和
+1
(g)细化的输出
(e2)置信度图
for()和
+1
(a2)
帧
+1
(b)彩色化
网络f
(
d2
)
+
1
():
帧t+1的第
i
(f)细化
网络g
(c)多样化的彩色化
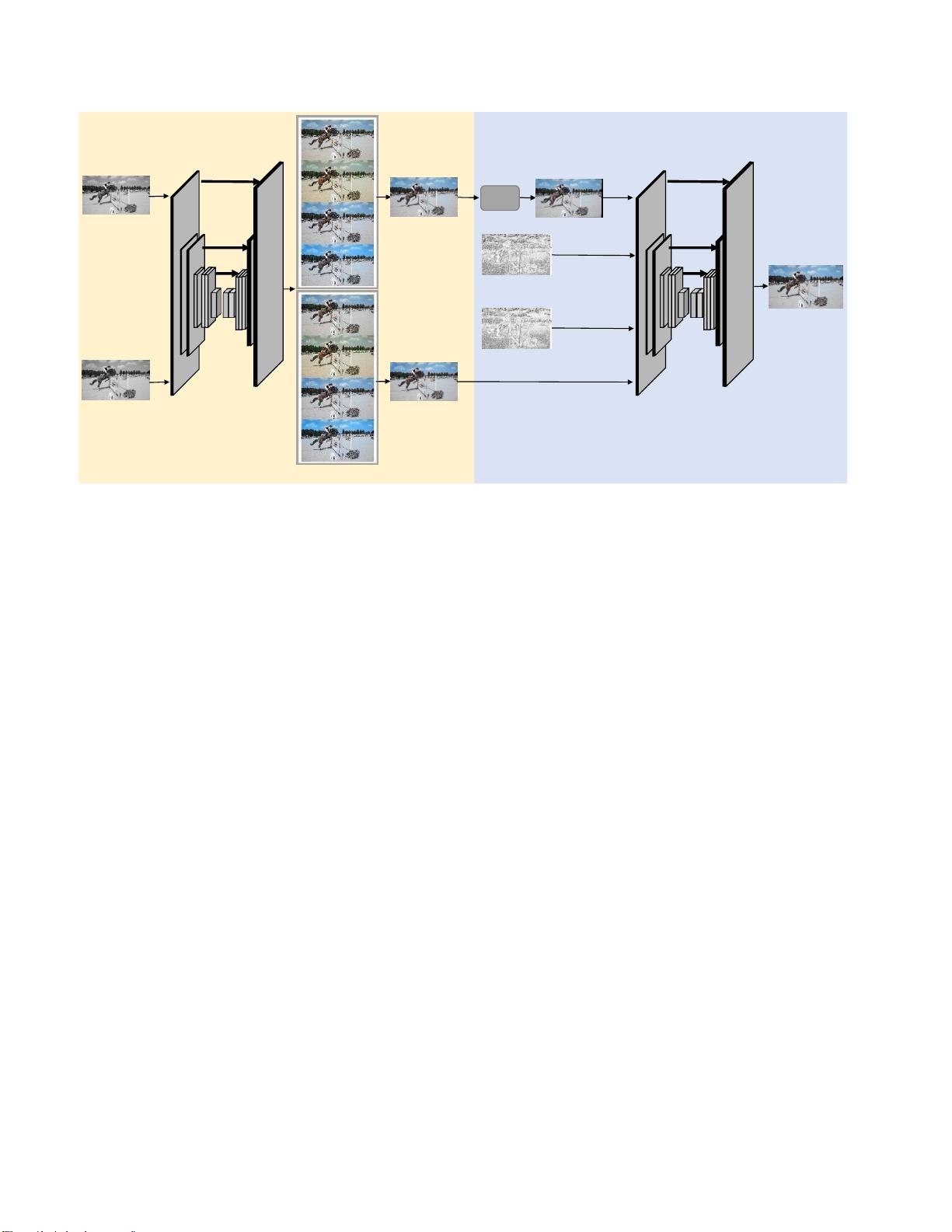
图2.我们模型的整体架构。着色网络f被设计为对每个灰度视频帧着色,并且产生多个着色候选图像。取来自帧t和帧t+ 1的第i
个着色候选图像以及两个置信图,细化网络
g
将输出帧
t
的细化视频帧。
He et al.的最新方法[11]结合了深度学习和图像着色中
的范例,并实现了最先进的性能。在这项工作中,我
们感兴趣的是全自动着色方法,既不需要用户输入,
也不需要参考图像。
自动图像着色。 全自动图像着色方面最突出的工作是
基于深度学习的方法,不需要任何用户指导[6,12,
32,16,9]。Cheng等人[6]提出了第一个用于全自动图
像着色的深度神经网络模型。一些深度学习方法使用
分类网络,将每个像素分类为数百个集合 在LAB或
HSV颜色空间中的色度样本,以解决彩色化问题的多
模态性质[32,16]。然而,在具有数百个点的二维色
度中,很难进行密集采样。因此,我们建议使用具有
多样性的感知损失[19]来避免离散化问题。
视频着色。大多数关于视频彩色化的同时期工作旨在
将颜色信息从颜色参考帧或稀疏用户涂鸦传播到整个
视频[31,29,23,20,14]。另一方面,Lai et al.[15]
提出了一种通过诸如彩色化的图像处理算法来逐帧地
增强所生成的视频的更强的时间一致性的方法。据我
们所知,目前还没有专门用于全自动视频着色的深度
学习模型。我们可以确定-
通常情况下,图像彩色化方法可以对视频中的每一帧
进行彩色化,但是得到的视频通常是时间上不相干
的。在本文中,我们提出了一种用于自动视频着色的
专用深度学习模型,该模型鼓励时空上下文传播,并
能够生成一组不同的彩色视频。
3.
概述
.
考虑灰度视频帧的连续序列X
=
X
1
,
. . .
,
X
n
.我们的目标是训练一个模型,自动-
对X进行彩色化,使得彩色化的视频是真实的。在我
们的框架中,既不需要用户指导,也不需要颜色参考
框架。在描述我们的方法之前,我们描述了我们的全
自动视频彩色化方法的两个理想特性
•
时空色彩一致性。在视频帧内,多个像素可以共
享相似的颜色。例如,墙上的所有像素都应该具
有
同样的颜色,所有的草都应该是绿色的。建立非
局部像素邻居(即,同一墙壁上的两个像素)的
颜色一致性可以提高彩色化视频的全局颜色一致
性。注意,独立地对视频帧进行着色可能导致时
间上不一致的视频,因此我们可以在两个帧之间
建立时间邻居以加强时间相干性。
剩余10页未读,继续阅读
相关推荐




cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- DeepFreeze密码移除工具6.x版本使用教程
- MQ2烟雾传感器无线报警器项目解析
- Android实现消息推送技术:WebSocket的运用解析
- 利用jQuery插件自定义制作酷似Flash的广告横幅通栏
- 自定义滚动时间选择器,轻松转换为Jar包
- Python环境下pyuvs-rt模块的使用与应用
- DLL文件导出函数查看器 - 查看DLL函数名称
- Laravel框架深度解析:开发者的创造力与学习资源
- 实现滚动屏幕背景固定,提升网页高端视觉效果
- 遗传算法解决0-1背包问题
- 必备nagios插件压缩包:实现监控的关键
- Asp.Net2.0 Data Tutorial全集深度解析
- Flutter文本分割插件flutter_break_iterator入门与实践
- GD Spi Flash存储器的详细技术手册
- 深入解析MyBatis PageHelper分页插件的使用与原理
- DELPHI实现斗地主游戏设计及半成品源码分析
