无监督特征表示的实例相似性学习
PDF格式 | 1.23MB |
更新于2025-01-16
| 153 浏览量 | 举报
10336
无监督特征表示的实例相似性学习
王紫薇
1
,
2
,
3
,王云松
1
,吴子怡
1
,陆继文
1
,
2
,
3 *
,周杰
1
,
2
,
3
1
清华
大学自动化系
2智能技术与系统国家重点实验室
3
北京国家信息科学技术研究中心
{wang-zw18,wangys16} @ mails.tsinghua.edu.cn; dazitu616@gmail.com;
{lujiwen,jzhou}@ tsinghua.edu.cn
摘要
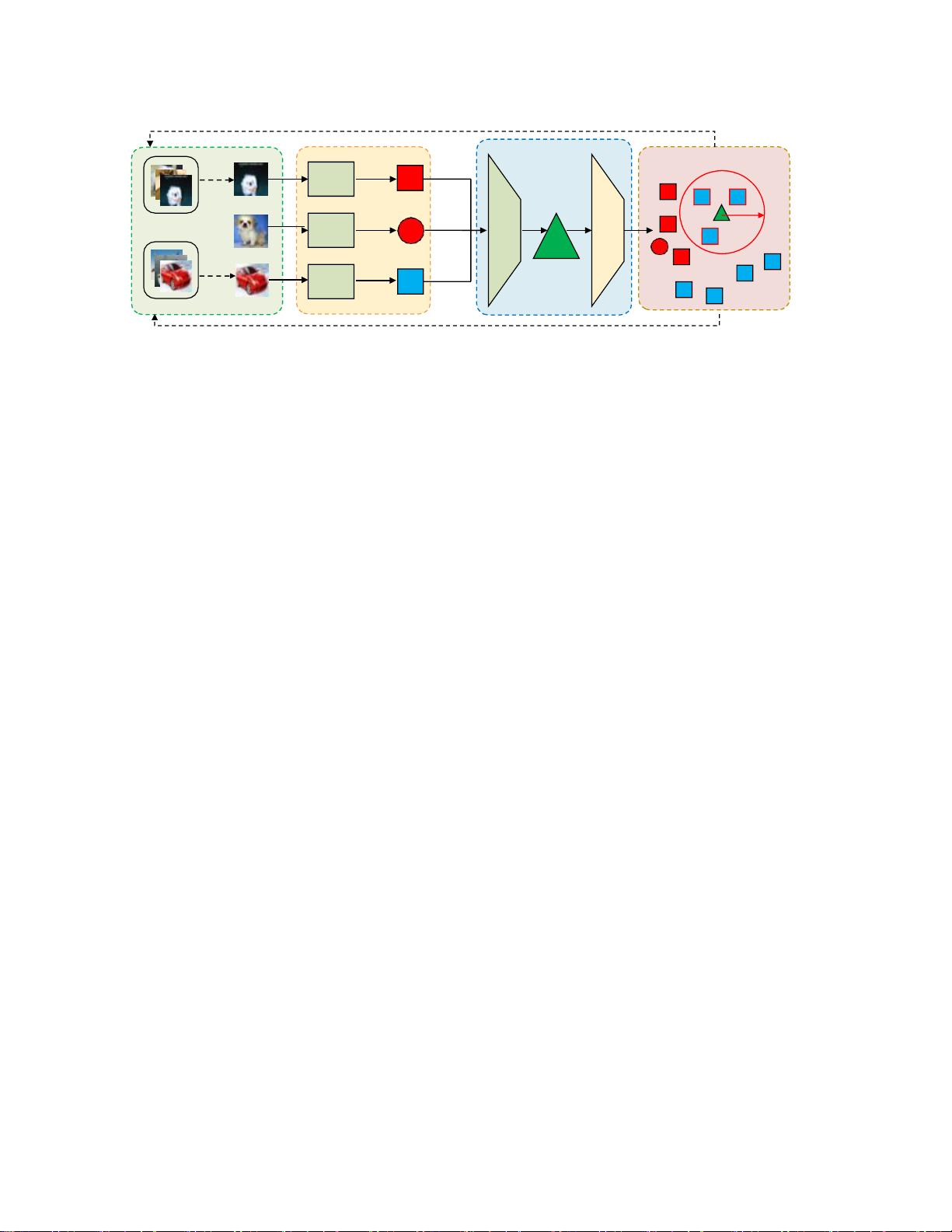
在本文中,我们提出了一个实例相似性学习(
ISL
)
的无监督特征表示方法。传统的方法在特征空间中分
配具有高相似性的紧密实例对,这通常导致对于大邻
域的错误的成对关系,这是由于欧氏距离不能描述特
征流形上的真实语义相似性。相反,我们的方法以无
监督的方式挖掘特征流形,通过学习实例之间的语义
相似性,以获得有区别的表示。
聚类
实例特异性
分析
邻域发现
ISL
句子具体而言,我们采用生成式对抗网络(
GAN
)挖
掘底层的特征流形,其中生成的特征被应用作为代
理,以逐步探索的特征流形,以便获得实例之间的语
义相似性作为可靠的伪监督。大量的图像分类实验表
明,我们的方法相比,国家的最先进的方法的优越
性 。 该 代 码 可 在
https://github.com/ZiweiWangTHU/ISL.git
上获得。
1.
介绍
深度神经网络已经在各种视觉应用中实现了最先进
的性能,例如人脸识别[7,45,34],对象检测[41,
33,30],图像检索[14,42,32]等。然而,大多数成
功的深度神经网络都是用强监督来训练的,这需要大
量标注数据,标注成本昂贵,并严格限制了深度模型
的部署。因此,期望仅用未标记的数据来训练深度神
经网络,同时实现与监督学习可比较的性能。
为了使深度神经网络能够从未标记的数据中学习,
无监督学习方法已经广泛应用。
*
通讯作者
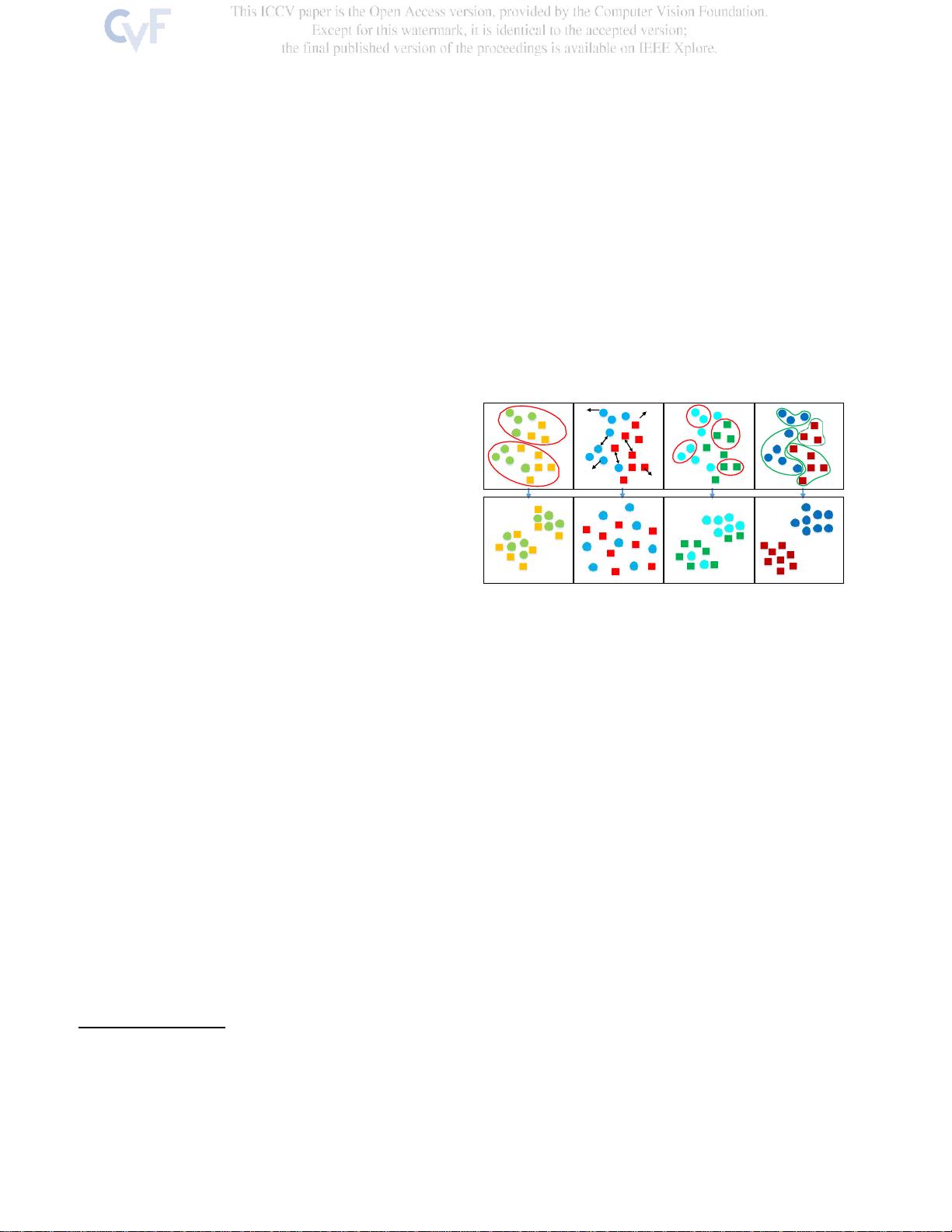
图1.比较了聚类方法、实例特异性分析方法、邻域发现方法
和本文方法的不同之处。聚类方法由于复杂的类间边界而容
易出错,并且实例特异性分析方法由于将每个样本视为独立
类的模糊监督而具有弱区分性。同时,邻域发现方法将靠近
锚点的实例视为相似样本,无法在特征流形上描述大邻域中
的真实语义相似性。相反,我们挖掘的特征流形和学习的实
例到实例的关系,具有可靠的语义相似性,因此,信息的功
能,可以获得。
最近研究的。图1的第一列中所示的聚类方法 [24,
47,3]提供了伪标签来根据聚类索引训练网络,由于
复杂的类间边界,聚类索引容易出错。图1的第二列中
描绘的实例特异性分析方法[46,2,38 , 16,21然
而,提供的监督是模糊的,导致弱的阶级歧视。同
时,由于辅助监督和目标任务之间的差异,使用自监
督学习设计文本前任务[8,51,44]具有与实例特异性
分析方法相同的局限性为了减轻聚类和实例特异性分
析的缺点,邻居-

剩余12页未读,继续阅读
相关推荐

57 浏览量




cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- DeepFreeze密码移除工具6.x版本使用教程
- MQ2烟雾传感器无线报警器项目解析
- Android实现消息推送技术:WebSocket的运用解析
- 利用jQuery插件自定义制作酷似Flash的广告横幅通栏
- 自定义滚动时间选择器,轻松转换为Jar包
- Python环境下pyuvs-rt模块的使用与应用
- DLL文件导出函数查看器 - 查看DLL函数名称
- Laravel框架深度解析:开发者的创造力与学习资源
- 实现滚动屏幕背景固定,提升网页高端视觉效果
- 遗传算法解决0-1背包问题
- 必备nagios插件压缩包:实现监控的关键
- Asp.Net2.0 Data Tutorial全集深度解析
- Flutter文本分割插件flutter_break_iterator入门与实践
- GD Spi Flash存储器的详细技术手册
- 深入解析MyBatis PageHelper分页插件的使用与原理
- DELPHI实现斗地主游戏设计及半成品源码分析
