时间注意对齐:推动视频域自适应新高度
135 浏览量
更新于2025-01-16
收藏 1.04MB PDF 举报
大规模视频域自适应:时间注意对齐
随着计算机视觉技术的发展,尤其是在图像领域,域自适应(Domain Adaptation, DA)已经成为一项关键的研究课题,旨在解决模型在跨域环境下迁移学习的问题。近年来,尽管有许多基于图像的DA方法取得了显著成果,但在处理大规模视频数据时,视频领域的域偏移问题却相对较少被关注。传统的研究往往集中在小型数据集上,无法全面评估在真实世界大规模数据集上的性能。
为了填补这一空白,研究者Min-Hung Chen、Zsolt Kira等人提出了两个具有较大域差异的大规模视频DA数据集:UCF-HMDB完整版和动力学游戏。这两个数据集为视频DA的研究提供了更广泛的挑战和基准,使得研究人员能够更深入地了解视频场景下的DA性能。
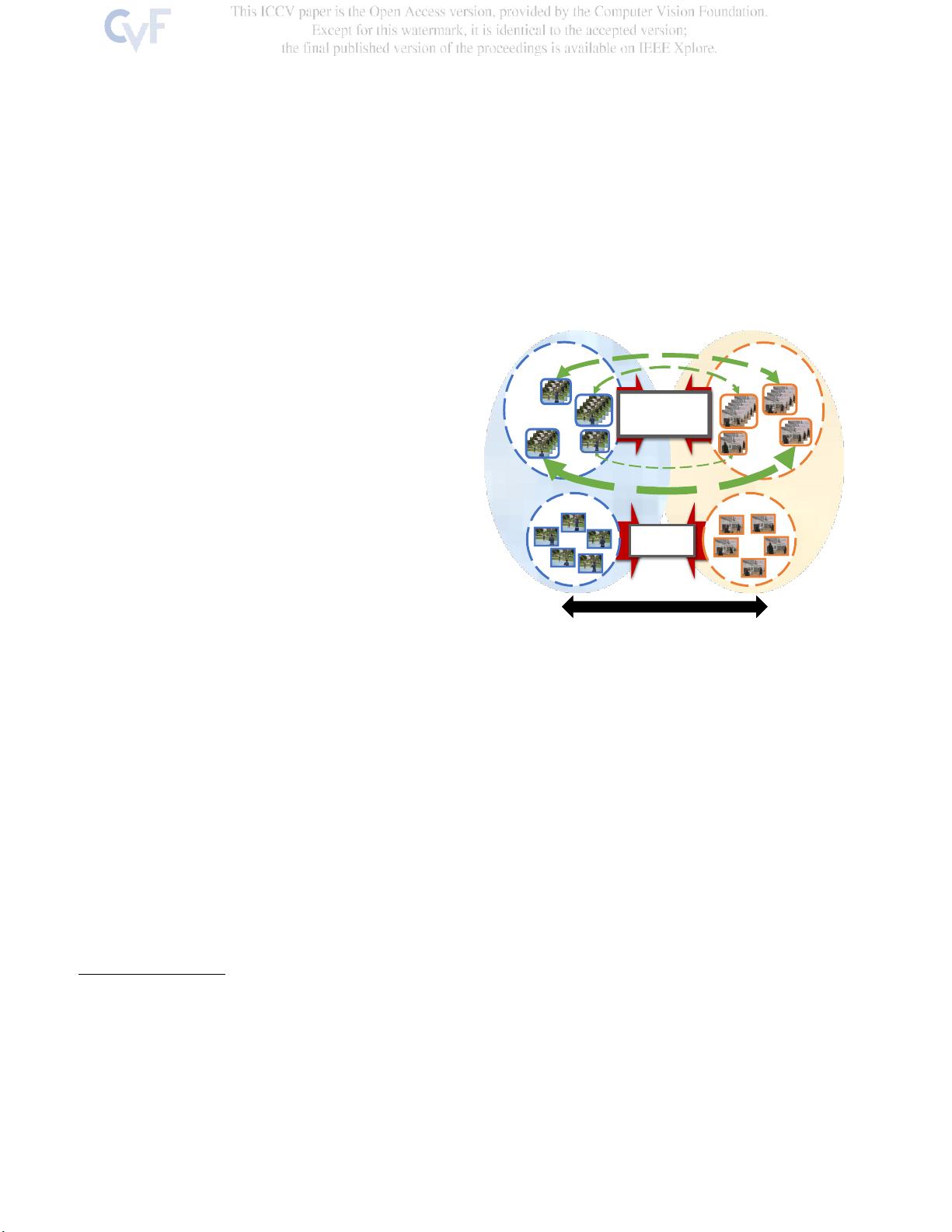
以往的视频DA方法通常依赖于单一的DA集成策略,而该研究强调了同时对齐和学习时间动态的重要性。研究发现,即使在没有复杂DA技术的情况下,对时间动态的有效处理也能显著提升视频数据的对齐效果。这种方法强调了时间维度在视频分析中的独特性,因为视频中的帧序列不仅存在空间差异,还包含着随着时间推移而变化的局部节奏动态,如图1所示。
针对这一问题,研究人员提出了时间注意对抗适应网络(Time-Aware Adversarial Adaptation Network, TA3N)。TA3N设计了一个明确关注域差异时间动态的机制,通过时间注意力机制,网络能够更有效地捕捉和利用这些动态变化,从而实现更精准的域对齐。在四大数据集的实验中,TA3N展现出了卓越的性能提升,例如在HMDB→UCF数据集上,无监督DA的精度从73.9%提升到了81.8%,在Ki-netics→Gameplay数据集上提升了10.3%。这表明TA3N对于视频DA任务具有显著的优势。
值得注意的是,这项研究的工作成果还包括了开源的代码和数据集,以便其他研究者能够在http://github.com/cmhungsteve/TA3N上获取并进一步发展视频DA的方法。大规模视频域自适应:时间注意对齐的研究为我们理解如何更有效地处理视频数据中的时空不一致性提供了一种新颖且实用的策略,为未来视频领域内的迁移学习开辟了新的方向。
6321
用于大规模视频域自适应的时间注意对齐
Min-Hung Chen
1 *
Zsolt Kira
1
Ghassan AlRegib
1
Jaekwon Yoo
2
Ruxin Chen
2
Jian Zheng
3 *
1
佐治亚理工学院
2
索尼互动娱乐有限责任公司
3
宾厄姆顿大学
摘要
虽然近年来已经提出了各种基于图像的域自适应
(
DA
)技术,但视频中的域偏移仍然没有得到很好的
探索。大多数以前的作品只评估小规模数据集的饱和
性能。因此,我们首先提出两个具有更大域差异的大
规模视频
DA
数据集:
UCF-HMDB
完整
和动力学游戏。
其次,我们研究了视频的不同
DA
集成方法,并表明即
使没有复杂的
DA
方法,同时对齐和学习时间动态也可
以实现有效的对齐。最后,我们提出了时间注意对抗
适应网络(
TA
3
N
),它明确地注意到使用域差异的
时间动态,以实现更有效的域对齐,在四个视频
DA
数
据集 上实 现了 最先 进的性 能( 例如 ,在
“HMDB →
UCF”
上,
“
仅源
”
的准确度从
73.9%
提高
到81.8%,在
“Ki- netics → Gameplay”上提高了10.3%)
。代码和
数据在
http://github.com/cmhungsteve/TA3N
上发布。
1. 介绍
近年来[4]广泛研究了
域自适应(
DA
)
[29]以解决
域
转移
问题[32,30],这意味着在源标记数据集上训练
的模型不能很好地推广到目标数据集和任务。DA根据
目标域中注释的可用性进行分类在本文中,我们专注
于更难的无监督DA问题,这需要训练模型,可以推广
到目标样本,而无需访问任何目标标签。虽然许多无
监督DA方法能够在学习区分性深度特征的同时减少源
域和目标域之间的分布 间隙[22,24,9,10,21,
20,34],但大多数方法仅针对图像而非视频开发。
此外,与基于图像的DA工作不同,不存在组织良好
的数据集来评估和基准测试视频DA算法的性能。最常
见的数据集是UCF-Olympic和UCF-HMDB
small
[39,
*
作为SIE实习生完成部分
源 靶
时间
时间
空间
空间
域移位
空间
对准
时间对准
图1:视频DA的建议TA
3
N概述.除了帧图像之间的空
间差异之外,视频还遭受时间排序帧集合之间的时间
差异,所述时间排序帧集合包含对整体区域偏移具有
不同贡献的多个局部节奏动态,如绿色虚线箭头的粗
细所指示的。因此,我们建议专注于对齐具有较高域
差异的时间动态,使用学习的注意力机制来有效地对
齐视频的时间嵌入特征空间。在这里,我们用
篮球
作
为例子。
46,15],只有少数重叠的类别之间的源和目标域。这
引入了有限的域差异,使得即使没有任何DA方法,深
度CNN架构也可以实现近乎完美的性能(详见第5.2节
和表2)。因此,我们提出了两个更大规模的数据集来
研究 视频 DA :1 )UCF-HMDB
完 整
:我 们收 集了UCF
101 [38]和HMDB 51 [18]之间的12个重叠类别,约为
UCF-Olympic和UCF-HMDB
small
的三倍,并且包含更
大的域差异(详见第5.2节以及表3和表4)。
2)
动力学游戏
:我们收集从几个目前
下载后可阅读完整内容,剩余9页未读,立即下载
2021-05-18 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
272 浏览量
点击了解资源详情
4485 浏览量

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 久度免费文件代存系统 v1.0:全技术领域源码分享
- 深入解析caseyjpaul.github.io的HTML结构
- HTML5视频播放器的实现与应用
- SSD7练习9完整答案解析
- 迅捷PDF完美转PPT技术:深度识别PDF内容
- 批量截取子网页工具:Python源码分享与使用指南
- Kotlin4You: 探索设计模式与架构概念
- 古典风格茶园茶叶酿制企业网站模板
- 多功能轻量级jquery tab选项卡插件使用教程
- 实现快速增量更新的jar包解决方案
- RabbitMQ消息队列安装及应用实战教程
- 简化操作:一键脚本调用截图工具使用指南
- XSJ流量积算仪控制与数显功能介绍
- Android平台下的AES加密与解密技术应用研究
- Место-响应式单页网站的项目实践
- Android完整聊天客户端演示与实践
