基于多种原始扫描数据的三维人脸建模
193 浏览量
更新于2025-01-16
收藏 1.94MB PDF 举报
9408
基于多种原始扫描数据的三维人脸建模
密歇根州立大学计算机科学与工程系,
密歇根州东兰辛,邮编48824
{
liufeng6
,
tranluan
,
liuxm
}
@ msu.edu
摘要
传统
的
三维人脸模型使用线性子空间从单个数据库
的有限扫描中学习人脸的潜在从不同的
3D
数据库中构
建大规模人脸模型的主要障碍为了解决这些问题,本
文提出了一个创新的框架,共同学习一个非线性的人
脸模型,从一组不同的原始
三维
扫描数据库,并建立
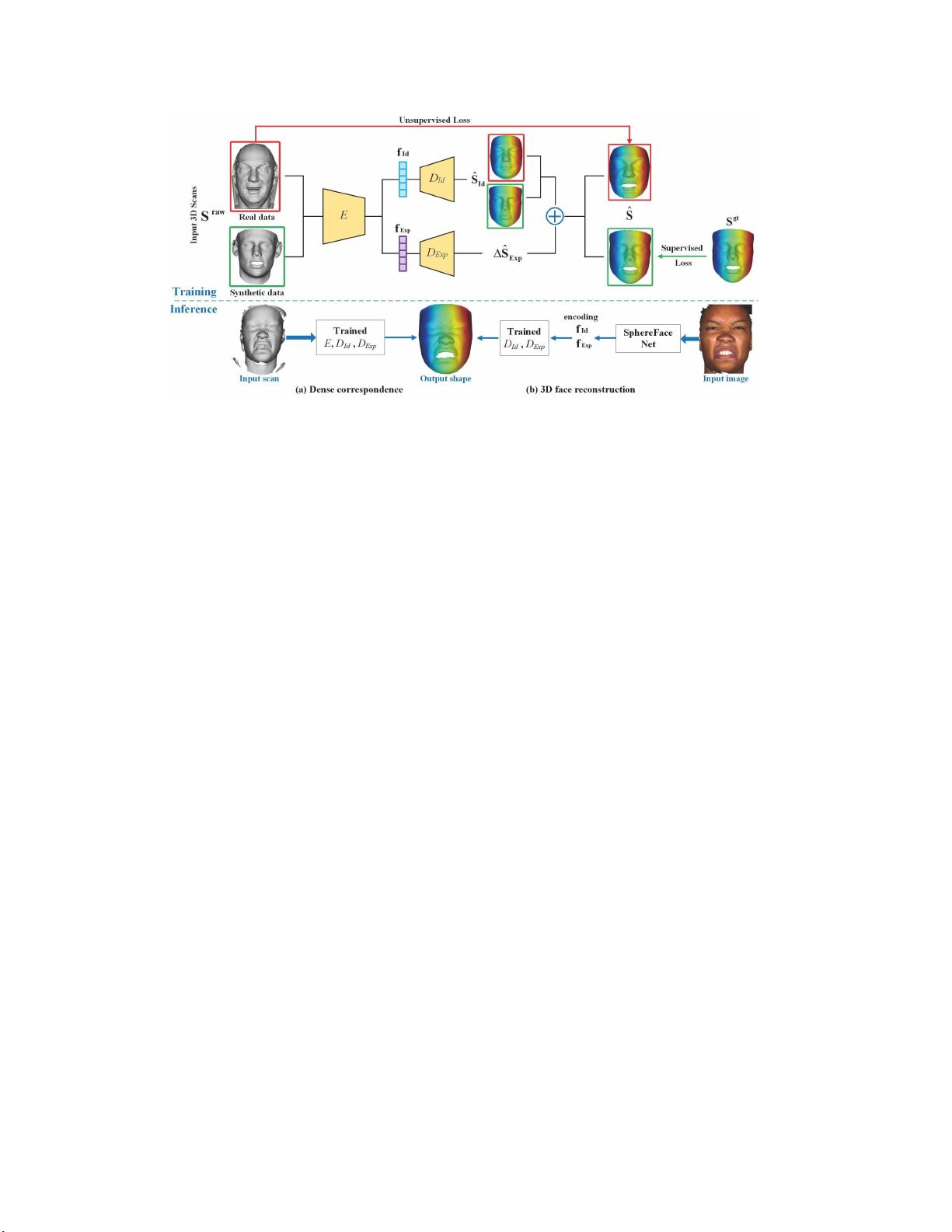
密集的点到点之间的对应关系扫描。具体来说,通过
将输入扫描视为无组织的点云,我们探索使用
PointNet
架构将点云转换为身份和表情特征表示,解码器网络
从中恢复其
3D
人脸形状。此外,我们提出了一种弱监
督学习方法,不需要对应标签的扫描。我们证明了我
们提出的方法优越的密集对应和表示能力,其贡献的
单图像
三维
人脸重建。
1.
介绍
鲁棒性和表现力的
3D
人脸建模对于计算机视觉问题
是有价值的,
例如
. 三维重建[7,24,41,54]和人脸
识 别 [42 , 43 , 58] , 以 及 计 算 机 图 形 学 问 题 ,
例
如,
,角色动画[15,31]。最先进的3D人脸表示大多
采用线性变换[39,59,60],
例如
,三维可变形模型
(3 DMM)或高阶张量推广[1,13,14,67],
例如
混
合变形模型。然而,这些线性模型无法捕捉非线性变
形,如高频细节和极端的表达。最近,随着深度学习
的出现,已经有几次尝试使用深度神经网络进行非线
性数据驱动的面部建模[4,32,51,65]。
为了对3D脸部形状进行建模,需要大量的高质量
3D
广泛使用的基于
3
DMM的BFM
2009
[48]是从仅
200
个
中性表情的受试者缺乏表达可能是一种...
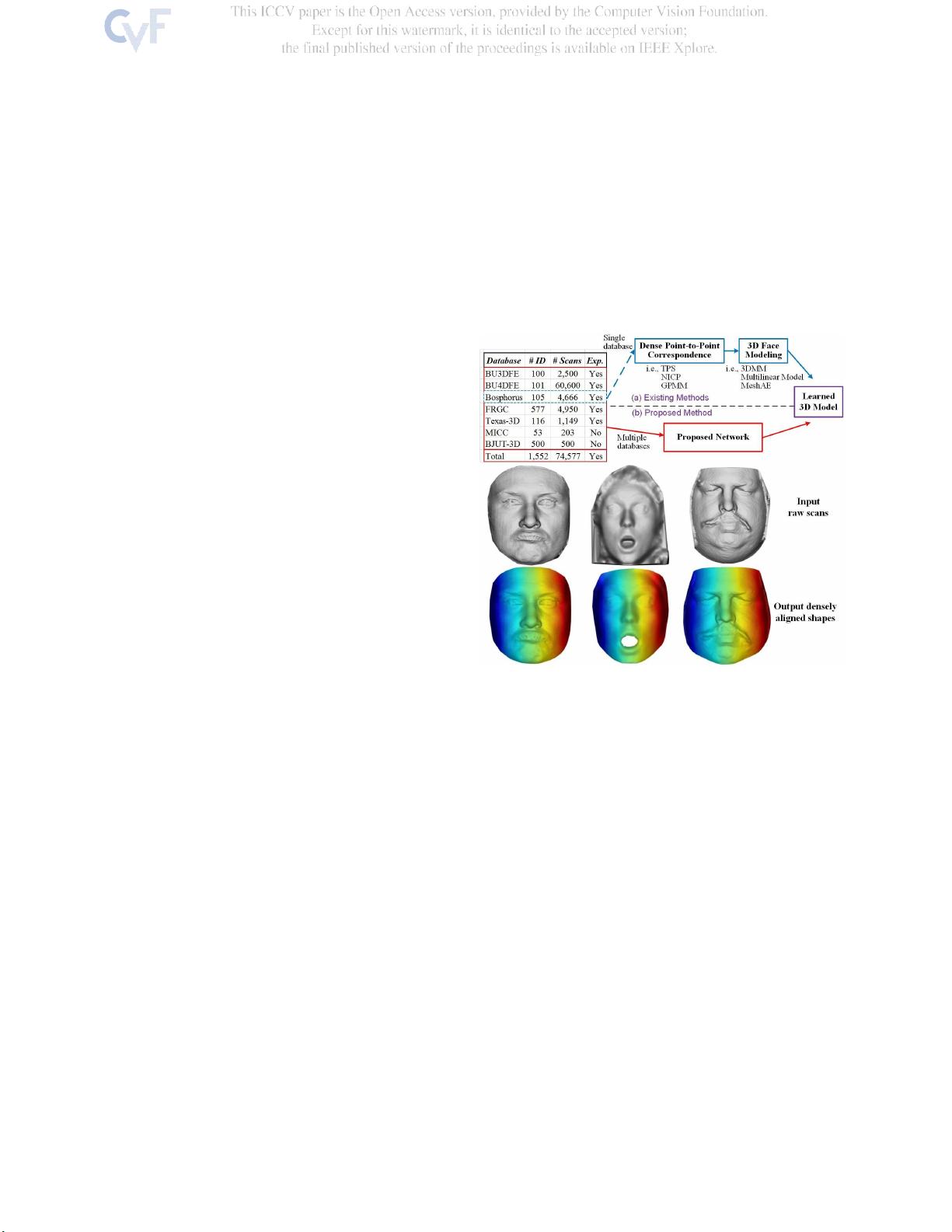
图1:(a)现有方法和(b)我们提出的方法的3D人脸建模
之间的比较。稠密的点到点对应关系是现有三维人脸建模方
法的先决条件。我们提出的基于CNN的方法
直接
从
多个
3D
人脸数据库的原始扫描中学习人脸模型,并在所有扫描之间
建立密集的点对点对应关系尽管扫描的分辨率和表达的多样
性,我们的模型可以表达细节的精细程度
用来自FaceWarehouse [14]或BD-3FE [70]的表达基进行
补偿。经过十多年的发展,几乎所有现有的模型使用
的训练对象都不到300个。如此小的训练集远远不足以
描述人脸的全部变化。直到最近,Booth
等人。
[11,
12]通过对9,663名受试者的中性扫描建立了第一个大
规模人脸模型(LSFM)不幸的是,只有得到的线性
3DMM基地被释放,而不是原来的扫描,我们不能充
分利用这个大数据库,探索不同的三维建模技术。
事实上,有许多公开可用的
3D
人脸数据库,如图所
示1.一、然而,这些数据库通常是
单独
使用的,而不
是联合使用
来创建大规模的人脸模型。主要障碍在于
挑战


剩余15页未读,继续阅读
105 浏览量
2021-09-25 上传
125 浏览量
2023-01-30 上传
2021-09-19 上传
331 浏览量
点击了解资源详情

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- WebDrive v16.00.4368: 简易易用的Windows风格FTP工具
- FirexKit:Python的FireX库组件
- Labview登录界面设计与主界面跳转实现指南
- ASP.NET JS引用管理器:解决重复问题
- HTML5 canvas绘图技术源代码下载
- 昆仑通态嵌入版ASD操舵仪软件应用解析
- JavaScript实现最小公倍数和最大公约数算法
- C++中实现XML操作类的方法与应用
- 设计编程工具集:材料重量快速计算指南
- Fancybox:Jquery图片轮播幻灯弹窗插件推荐
- Splunk Fitbit:全方位分析您的活动与睡眠数据
- Emoji表情编码资源及数据库查询实现
- JavaScript实现图片编辑:截取、旋转、缩放功能详解
- QNMS系统架构与应用实践
- 微软高薪面试题解析:通向世界500强的挑战
- 绿色全屏大气园林设计企业整站源码与多技术项目资源
