动态多视图网络MVTN:提升3D形状识别性能
PDF格式 | 13.86MB |
更新于2025-01-16
| 7 浏览量 | 举报
多视图转换网络(MVTN)是一种创新的深度学习架构,专为3D形状识别设计,旨在解决传统多视图方法存在的固定视角问题。多视图投影在3D形状识别领域表现出色,因为它们能够模仿人类观察物体的方式,通过多个视角融合信息。然而,现有的方法通常依赖于预设的、非学习化的相机视角,这限制了其在实际场景中的适应性和鲁棒性。
MVTN的核心贡献是引入了一种可微分的网络模块,它能够根据特定任务自适应地学习并预测最佳的多视图投影角度。这一模块与传统的3D形状分类网络无缝集成,允许两者在端到端的训练过程中协同工作,无需额外的监督信号。这种方法的优势在于,相比于固定视角,动态视角选择可以更好地捕捉3D对象的复杂结构和特征,从而提高3D形状分类和检索任务的性能。
在实验部分,MVTN在ModelNet40、ShapeNet Core55和ScanObjectNN等常用数据集上展现了显著的性能提升,特别是在ScanObjectNN的逼真场景中,MVTN实现了6%的精度提升,证明了其在实际场景中的鲁棒性和泛化能力。此外,MVTN展示了一定的网络鲁棒性,对于旋转和遮挡的处理能力增强,使得模型在面对不同光照、姿态变化时仍能保持高准确率。
总结来说,MVTN是3D形状识别领域的一个重大突破,它通过引入自适应多视图转换机制,提升了模型的灵活性和性能,为未来的3D视觉研究开辟了新的可能性。研究人员可以在其开源代码https://github.com/ajhamdi/MVTN的基础上进一步探索和优化多视图方法在其他3D应用场景中的应用。
arg min
θ
C
= arg min
θ
C
(1)
3.2. Multi-View Transformation Network (MVTN)
Previous multi-view methods take the multi-view image
X
as the only representation for the 3D shape, where
X
is
rendered using fixed scene parameters
u
0
. In contrast, we
consider a more general case, where
u
is variable yet within
bounds
±u
bound
. Here,
u
bound
is positive and it defines the
permissible range for the scene parameters. We set
u
bound
to
180
◦
and 90
◦
for each azimuth and elevation angle.
Differentiable Renderer.
A renderer
R
takes a 3D shape
S
(mesh or point cloud) and scene parameters
u
as inputs,
and outputs the corresponding
M
rendered images
x
i
M
.
3
0
图2.
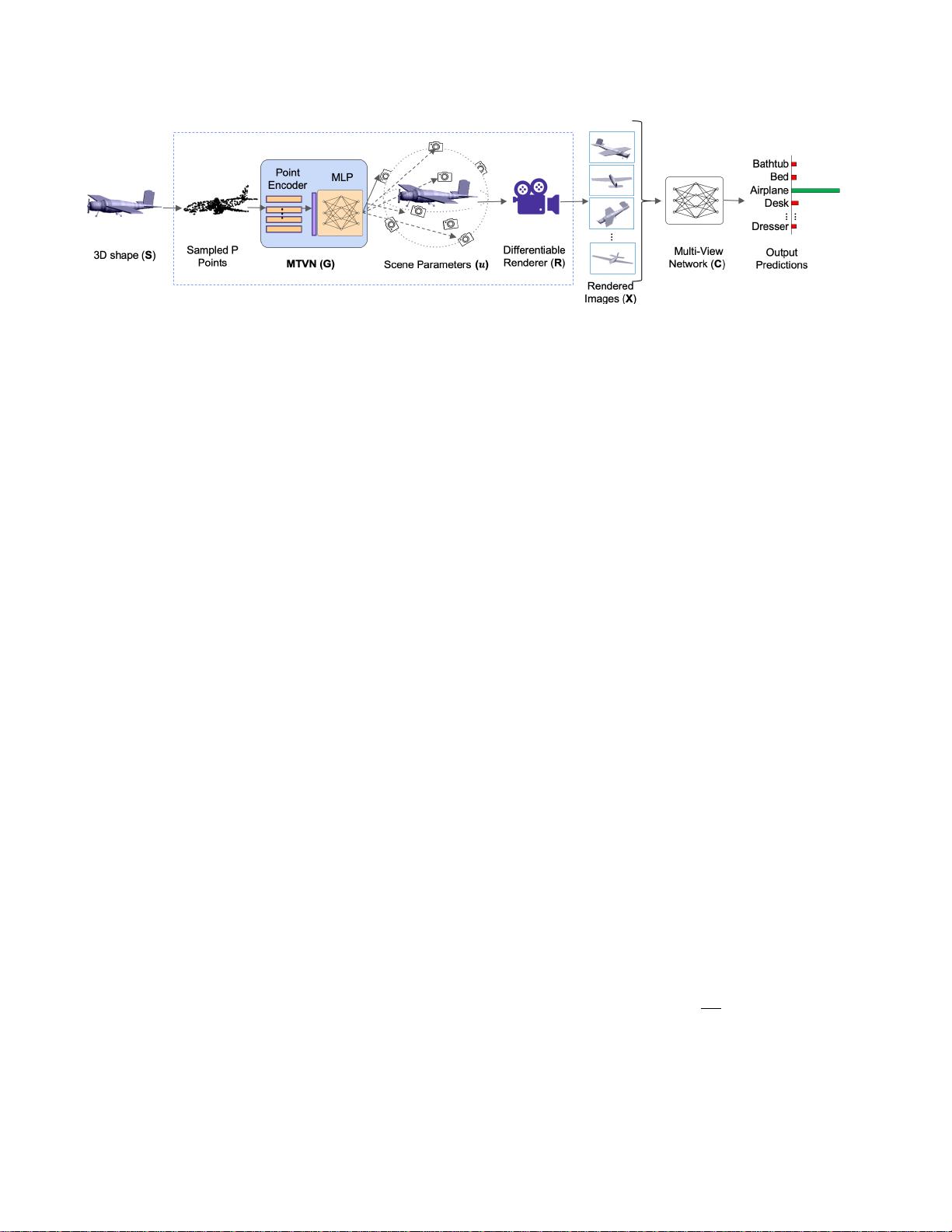
多视角识别的端到端学习流程。为了学习使多视角网络C在每个3D对象形状S上的性能最大化的自适应场景参数u,我们使用可微渲染器R。M
VTN通过点编码器从S中提取粗略特征,并回归该对象的自适应场景参数。在这个例子中,参数u是指向对象中心的相机的方位角和仰角。MV
TN流程通过任务损失进行端到端优化。
0
3.方法论
0
我们使用MVTN在图2中展示了我们提出的多视角流程。MV
TN是一个通用模块,用于学习特定的3D多视角任务的相机
视角转换,例如3D形状分类。在本节中,我们回顾了常见多
视角流程的通用框架,介绍了MVTN的细节,并展示了将M
VTN集成到3D形状分类和检索中的方法。
0
3.1.多视角三维识别概述
三维多视角识别定义了从同一形状S的多个视角渲染的M个不同图像{xi}Mi=1。这些视角被
输入到相同的骨干网络f中,该网络提取每个视角的判别特征。然后在视角之间聚合这些特
征来描述整个形状,并用于分类或检索等下游任务。具体来说,具有参数θC的多视角网络
C在输入图像集X∈RM×h×w×c上操作
0
以获得形状S的softmax概率向量。训练多视角网络。文献中
最简单的深度多视角分类器是MVCNN,其中C=
MLP(maxi
f(xi)),其中f:Rh×w×c→Rd是分别应用于每个渲染图像的
2D
CNN骨干(例如ResNet[30])。像ViewGCN这样的较新方
法将被描述为C=MLP(catGCN(f(xi))),其中cat
GCN是从图卷积网络中学习的视图特征的聚合。通常,学习
标记的3D数据集上的任务特定多视角网络的形式化表示为:
00
nL=C(Xn),yn,
00
nL=C(Sn,u0),yn,
0
其中L是在数据集中的N个3D形状上定义的任务特定损失,yn是第n个3D形状Sn的标签,u0∈Rτ
是整个数据集的一组固定场景参数,其中τ是2M。规范视图。以前的多视图方法依赖于为整个3D
数据集预定义的场景参数u0。特别地,固定的相机视角通常基于数据集中3D模型的对齐选择。
最常见的视图配置是围绕对象的圆形视角[61,76]和围绕对象的球形视角[67,
38]。为所有3D对象固定这些规范视图可能对某些类别产生误导。例如,从底部看床可能会混淆3
D分类器。相反,MVTN学习回归每个形状的视角,如图3所示。
0
数据集。这些参数表示影响渲染图像的属性,包括相机视角
、光照、对象颜色和背景。R是渲染器,它以形状Sn和参数u
0作为输入,为每个形状产生M个多视图图像Xn。在我们的
实验中,我们选择将场景参数u设置为指向对象中心的相机
视角的方位角和仰角,从而设置τ=2M。规范视图。以前的
多视图方法依赖于为整个3D数据集预定义的场景参数u0。
特别地,固定的相机视角通常基于数据集中3D模型的对齐选
择。最常见的视图配置是围绕对象的圆形视角[61,
76]和围绕对象的球形视角[67,
38]。为所有3D对象固定这些规范视图可能对某些类别产生
误导。例如,从底部看床可能会混淆3D分类器。相反,MV
TN学习回归每个形状的视角,如图3所示。
0
∂u可以从每个渲染图像向后传播到场景参数,从而建立适合
端到端深度学习流程的框架。当S表示为3D网格时,R有两个
组件:光栅化器和着色器。首先,光栅化器根据世界坐标将
网格转换为视图坐标,给出
剩余10页未读,继续阅读
相关推荐


4 浏览量

4 浏览量
3 浏览量

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Openaea:Unity下开源fanmad-aea游戏开发
- Eclipse中实用的Maven3插件指南
- 批量查询软件发布:轻松掌握搜索引擎下拉关键词
- 《C#技术内幕》源代码解析与学习指南
- Carmon广义切比雪夫滤波器综合与耦合矩阵分析
- C++在MFC框架下实时采集Kinect深度及彩色图像
- 代码研究员的Markdown阅读笔记解析
- 基于TCP/UDP的数据采集与端口监听系统
- 探索CDirDialog:高效的文件路径选择对话框
- PIC24单片机开发全攻略:原理与编程指南
- 实现文字焦点切换特效与滤镜滚动效果的JavaScript代码
- Flask API入门教程:快速设置与运行
- Matlab实现的说话人识别和确认系统
- 全面操作OpenFlight格式的API安装指南
- 基于C++的书店管理系统课程设计与源码解析
- Apache Tomcat 7.0.42版本压缩包发布
