NeurMiPs:高效的基于平面的神经混合模型用于视图合成
169 浏览量
更新于2025-01-16
收藏 2.4MB PDF 举报
"基于平面的神经混合模型用于高效视图合成"
在计算机图形学和虚拟现实领域,视图合成是一项关键技术,它允许从不同的视角重新渲染一个场景,提供沉浸式的体验。传统的视图合成方法通常依赖于显式几何表示,如多平面图像、点云或网格,以及基于图像的渲染技术。然而,这些方法往往存在内存消耗大和对几何结构要求较高的问题。
神经网络在近几年已经被广泛应用到视图合成中,尤其是神经辐射场(NeRF)的提出,它通过学习场景的连续密度场和颜色场来生成高保真图像。尽管NeRF表现出了出色的渲染效果,但其采样效率低和对硬件资源的需求较高,限制了其在实时应用中的潜力。
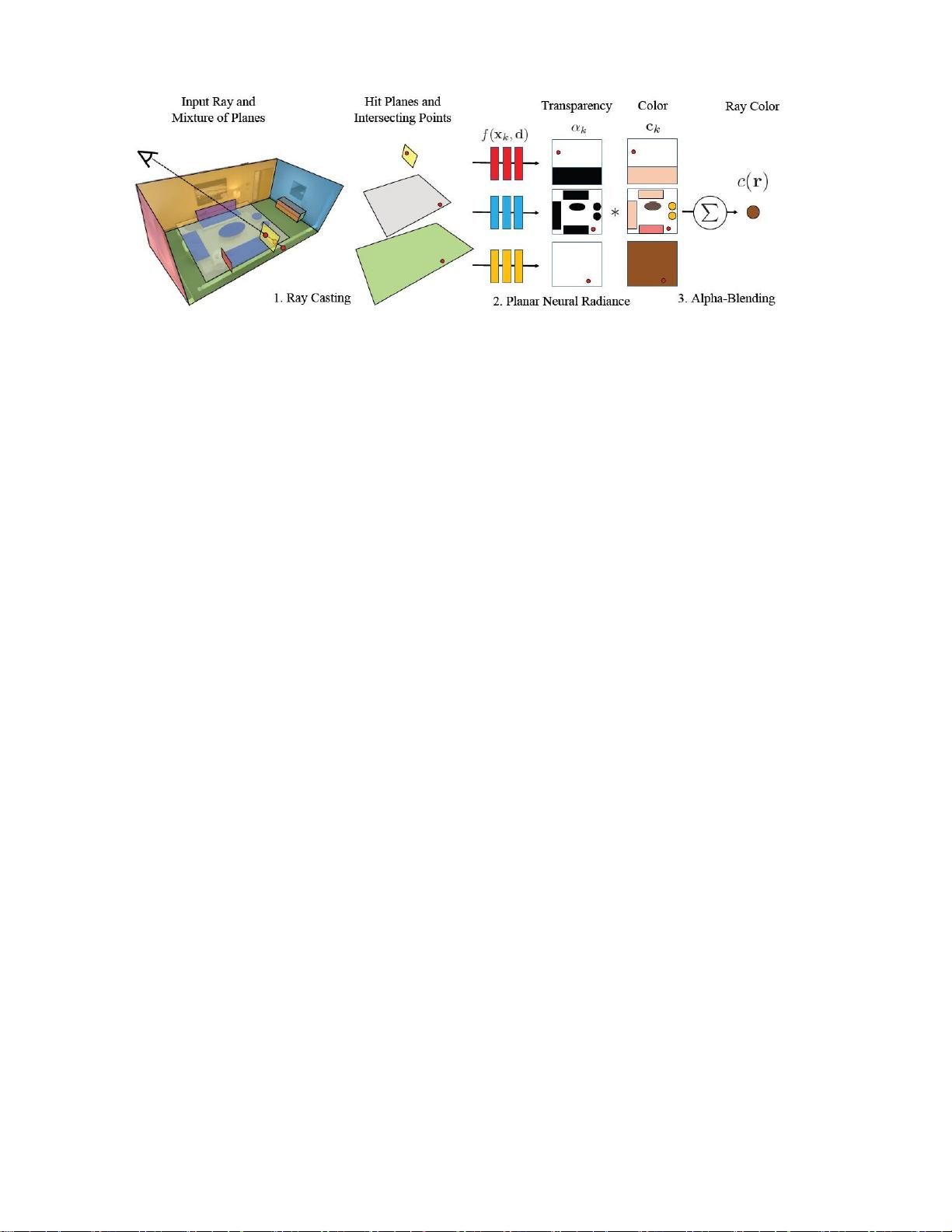
"平面专家神经混合模型(NeurMiPs)"是一种新的解决方案,旨在结合显式几何形状表示的效率与神经辐射场的灵活性。该模型的核心在于使用3D空间中的局部平面专家集合来表示场景。每个平面专家由一个表示几何形状的局部矩形参数和一个模拟颜色与不透明度的神经辐射场组成。这种方法能够有效地模拟复杂的表面几何和外观。
NeurMiPs通过计算光线与平面的交点并复合输出的颜色和密度,在图像的顶点进行渲染。这种渲染方式融合了显式网格渲染的效率和NeRF的灵活性,从而提高了新视图合成的速度和质量。在实际应用中,NeurMiPs能够在保持图像质量的同时,降低内存需求,这对于实现如Metaverse这样的实时、高质量、内存高效的虚拟环境至关重要。
实验结果表明,NeurMiPs在新视图合成任务上相比于其他3D表示方法,无论是性能还是速度,都有显著优势。这使得NeurMiPs成为解决实时视图合成挑战的一种有前途的技术。随着虚拟现实和增强现实技术的发展,这种高效、灵活的视图合成方法有望在未来得到更广泛的应用。
15704
图4.NeurMiPs的渲染管道我们首先投射光线并确定相交点和平面。然后可以通过每个平面的神经辐射场来评估颜色和不透明
度最后,进行阿尔法混合步骤以输出最终光线颜色。
最先进的重建质量和良好的视图合成结果。然而,渲
染隐式函数需要顺序的射线行进步骤,并且需要额外
的步骤来提取表面。
神经体绘制:体辐射场可以追溯到90年代后期[19]。最
近的作品,如NeRF [44]和Neural Neural Needle [37]开
始研究用于体绘制的深度学习。它充分利用了神经网
络的表达能力和体绘制的灵活性在过去的一年中,已
经提出了大量的新方法来扩展NeRF [4,17,25,36,
42,44,50,71,82,84]。代表性的作品可以处理稀
疏输入视图[69,79],无界场景[82],克服混叠效应[4]
并将未知/噪声姿态作为输入[33]。
开创性的NeRF [44]不会实时呈现有几篇文章试图使
用不同的策略来加速NeRF例如,像[17,49,50,78]
这样的方法选择将输入场景分解为更小的区域,并使
用更小的网络为每个区域建模3D几何其他方法通过早
期射线终止[47],空空间跳过[50,78],可学习
稀疏采样[2,45,64],或闭型无采样积分[34]。延迟
渲染或烘焙技术也被用来加速NeRF [17,25]。我们的
方法是一个新的实例上述加速技术通过平面表示。也
许最接近我们的工作是MVP [38],他们也利用了几何
图元。然而,存在一些关键的差异。首先,MVP利用
密集的体素网格
来捕捉复杂的人体头部纹理,我们用
平面来建模场景结构。其次,MVP显式地为每个体素
生成RGBα,这是消耗内存的,而NeurMiPs使用神经网
络对纹理进行建模。
2.2.
平面场景表示
我们并不是第一个意识到多个倾斜平面用于表示场
景几何体的潜力的人。计算机视觉和图形社区有着悠
久的历史,
利用平面表面进行建模和渲染。各种形式的平面场景
表示 已被 研究[3,14,21, 23 , 27,28,32,55,
63]。代表作品
包括多边形网格[5,20]、Marr草图[40]、曼哈顿世界
[15,26]、二进制空间划分树[8]、3D盒布局[22,23]、
折纸理论[28]、倾斜平面[3,6,63]
等
。一个密切相关
的研究路线被称为分层精灵[63],它与我们的几何表示
相似关键的区别在于外观表示和渲染:分层的sprites为
每个平面使用图像纹理,渲染是通过单应性扭曲完成
的,而我们的NeurMiPs利用表达神经辐射场,渲染是
通过光线投射完成的,它可以捕获更好的视图相关效
果,并在复杂场景中运行
已经开发了许多方法来从图像中推理平面结构。例
如,可以从图像[35,80]中检测平面,恢复网格[18],
从立体重建倾斜的平面表面[6,16],利用平面结构进
行SLAM [54],基于局部平面假设估计表面法线和边界
[14],并最终从多个图像重建平面精神[27,55]。建议
的NeurMiPs可以被视为一个多视图的倾斜平面重建方
法,通过最大限度地减少光度量渲染损失。
3.
方法
在这项工作中,我们解决的问 题,小说的看法合
成。我们的目标是尽可能地提高渲染效率,同时提高
极端新颖视图的渲染质量。为了实现这一目标,我们
提出了一种新的神经表示称为平面专家的混合物,并
设计了一个神经渲染方法使用NeurMiPs。
具体来说,我们首先表示的场景作为一个混合的局
部平面表面。每个局部表面是一个有向的二维矩形在
三维。然后,我们为每个平面使用神经辐射场函数来
编码其依赖于视图的外观和透明度。几何形状和辐射
场都是从输入图像端到端学习的。期间
剩余12页未读,继续阅读

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 武汉大学数字图像处理课程课件精要
- 搭建个性化知识付费平台——Laravel开发MeEdu教程
- SSD7练习7完整解答指南
- Android中文API合集第三版:开发者必备指南
- Python测试自动化实践:深入理解更多测试案例
- 中国风室内装饰网站模板设计发布
- Android情景模式中音量定时控制与铃声设置技巧
- 温度城市的TypeScript实践应用
- 新版高通QPST刷机工具下载支持高通CPU
- C++实现24点问题求解的源代码
- 核电厂水处理系统的自动化控制解决方案
- 自定义进度条组件AMProgressView用于统计与下载进度展示
- 中国古典红木家具网页模板免费下载
- CSS定位技术之Position-master解析
- 复选框状态持久化及其日期同步技术
- Winform版HTML编辑器:强大功能与广泛适用性
