无监督人员身份再识别:Meta成对关系蒸馏新方法
PDF格式 | 948KB |
更新于2025-01-16
| 195 浏览量 | 举报
"本文主要介绍了无监督人员身份再识别中的Meta成对关系蒸馏方法,即MetaPairwise Relationship Distillation (MPRD)。该方法针对无监督人再识别的挑战,尤其是由于缺乏地面真实标签和聚类数量不准确导致的性能损失。MPRD通过结合卷积神经网络(CNN)和图卷积网络(GCN),利用样本对的伪标签估计,以改进特征学习。GCN基于CNN提取的特征来估计样本对的伪标签,而CNN则通过涉及GCN提供的正负样本对进行学习。此外,少量标记样本用于指导GCN的训练,提取元知识来判断正负样本对之间的邻域结构差异。实验结果表明,MPRD在Market-1501、DukeMTMC-reID和MSMT17数据集上优于现有的先进方法。文章指出,传统的无监督方法依赖于两两相似度估计伪标签,而MPRD则利用两两邻域结构,从而提高了伪标签的准确性。"
本文提出的MetaPairwise Relationship Distillation方法旨在解决无监督人员身份识别中的关键问题,即如何有效地估计和利用伪标签。传统的无监督方法可能因聚类数量不准确而导致性能下降,而MPRD则将问题转换为成对关系的估计,通过CNN和GCN的联合工作来改善这个过程。CNN负责提取图像特征,而GCN利用这些特征来估计样本对的伪标签,特别是正负样本对的区分。这种方法的优势在于,GCN能够捕获样本间的邻域结构,提供更精确的标签信息。
此外,引入少量标记样本作为指导,使得GCN能够学习到元知识,这对于区分正负样本对之间的关系至关重要。这种方法有助于减少噪声,提高无监督学习过程的稳健性。实验结果验证了MPRD的有效性,它在多个标准数据集上取得了显著的性能提升,表明这种方法对于应对无监督人员身份识别中的挑战具有潜力。
MPRD是一种创新的无监督学习策略,它通过改进伪标签的估计和利用,提升了无监督人员再识别系统的性能。这种方法不仅解决了聚类不确定性的问题,还通过图卷积网络的邻域结构分析增强了样本对的表示能力,为无监督学习在人再识别领域的应用提供了新的思路。
3663
| ·|
M F
M
⟨··⟩
|
| |
|
FM
·
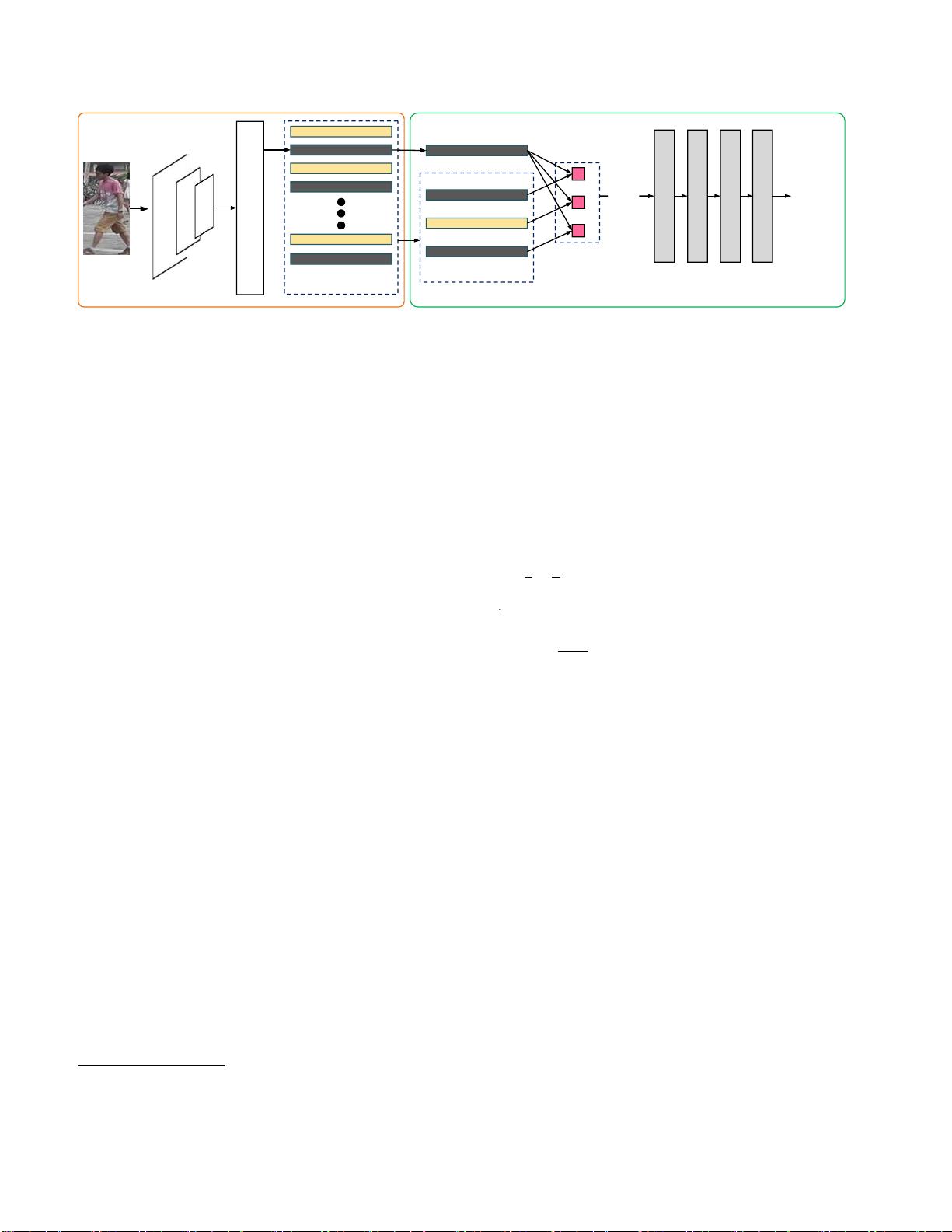
图2. MPRD概述。初始化的骨干网络提取训练图像的特征。然后,GCN推断特征与其邻居之间的成对关系,用于训练CNN模
型。
最相关的现有方法是MLCR [24],其将无监督人员
Re-ID任务重新表述为多标签分类问题。然而,我们认
为,我们的MPRD不同MLCR在两个方面。首先,我们
将该任务转化为一个成对关系估计问题;其次,我们设
计了一个有效的GCN模型,以提供高保真的伪标签。
第5.3节中的消融研究验证了MPRD
3.
Meta成对关系蒸馏
其中γ
(
t
)
表示迭代相关的更新速率。这种特征记忆机制
实际上实现了迭代过程中的平滑操作,潜在地减少了
特征中的剧烈振荡。
损失函数假设成对伪标签由GCN提供,我们引入二
项式偏差(BD)损失[30]函数
L
F
来训练CNN,其旨在
最小化正对中的距离并最大化负对中的距离。
n
给定未标记的数据集X={x
i
}
N
,其中x
i
de-
L
=
1
Σ
δ
Σ
ζ
(
α
(
λ
-
∠
F
~
(
x
)
,
M
~
[
j
]
∠
))
我
注意到
第
i输入图像,以及
i
=1
N表示
F
n
i
=1
| P
i
|
x
j
∈P
i
(
二
)
训练样本,MPRD估计成对伪
+
1
Σ
ζ
(
α
(
<
F
~
(
x
)
,
M
~
[
j
]
<
−
λ
))
,
标签用于特征学习。如图2所示,CNN学习由GCN生成
的成对伪标签监督的区分特征;而GCN是
|
N
∗
i
|
I
2
x
j
∈
N
*
i
基于CNN特征来估计成对伪标签。这种相互依赖性实
际上通过GCN和CNN的交替优化来解决。
3.1.
CNN
网络主干。CNN模块提取区分性特征,这允许在特
征空间中进行最近邻搜索为了简单起见,我们采用[8]
中的骨干网络作为我们的CNN选择
*
,它由一个特征提
取模块和一个特征存储模块组成在实践上许多
哪里
、
表示内积,因为
F
~
(
x
i
)
和
~
[j]是
12
归一化的单位向量,
~
(x
i
)
,
~
[j]表示
它们之间的余弦相似度,ζ(x)
=
log(1
+
ex
),n是批
量大小,表示基数(元素的数量),δ表示正对相对于
负对的重要性,λ
1
和λ
2
表示两个边缘参数,以及
α
是放大因子。此外,
Pi
和
Ni
分别
表示正对列表和负对
列表。作为实践中的
N
i
P
i
,我们进一步关注具有固
定大小
r
的硬否定
对列表
N
*
i
,如下所示。
特征提取模块
F
提取d维特征
F
~
(
x
,
i
)
,并且然后通过
F(x
i
)← F(x
i
)
/
F(x
i
)
2
,F(x
i
)
2
表示范数
N
*
i
=
{
x
j
|
x
j
∈
top(
﹥
F
~
(
x
i
)
,
M
~
[
j
]
﹥
,
r
)
,
x
j
∈N
i
}
,
(
3
)
特征存储器存储训练图像的所有特征。如下在第t
次
迭
代
M
(
t
)
[
i
]
←
γ
(
t
)
F
~
(
x
)
+
(1
-
γ
(
t
)
)
M
~
(
t
-
1
)
[
i
]
,
其中
top
(
,
r
)表示
r
个
最大样本。因此,
N
*
i
包含嵌
入特征空间中与查询x
i
最接近的
r
个样本。
在训练CNN之后,所有正对都集中
我
M
~
(
t
)
[
i
]
←
M
(
t
)
[
i
]
/
M
(
t
)
[
i
]
2
,
*
我们的方法与各种网络骨干兼容
(
一
)
在λ
1
的半径内;而所有负对位于else-
其中距离至少为λ
2
。然后,可以应用最近邻搜索算法
来解决人Re-ID问题。
Q
CNN
模型
Q
成对
邻域
结
构
I
1
我
2
我
G
qi
1
G
qi
2
G
qi
成对
关系
P
q
N×D
特性
NN
k
(
q
)
特征
图形卷积层
图形卷积层
聚集
多层感知
1
剩余11页未读,继续阅读
相关推荐



cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- DeepFreeze密码移除工具6.x版本使用教程
- MQ2烟雾传感器无线报警器项目解析
- Android实现消息推送技术:WebSocket的运用解析
- 利用jQuery插件自定义制作酷似Flash的广告横幅通栏
- 自定义滚动时间选择器,轻松转换为Jar包
- Python环境下pyuvs-rt模块的使用与应用
- DLL文件导出函数查看器 - 查看DLL函数名称
- Laravel框架深度解析:开发者的创造力与学习资源
- 实现滚动屏幕背景固定,提升网页高端视觉效果
- 遗传算法解决0-1背包问题
- 必备nagios插件压缩包:实现监控的关键
- Asp.Net2.0 Data Tutorial全集深度解析
- Flutter文本分割插件flutter_break_iterator入门与实践
- GD Spi Flash存储器的详细技术手册
- 深入解析MyBatis PageHelper分页插件的使用与原理
- DELPHI实现斗地主游戏设计及半成品源码分析
