数据驱动的远景映射:东南丘吉尔省案例分析,稀土元素资源探测新方法
PDF格式 | 27.91MB |
更新于2025-01-16
| 61 浏览量 | 举报

–
0
走向完全数据驱动的远景映射方法:东南丘吉尔省魁北克和拉布拉多的案例研
究
0
张艺,朱莉∙布尔多,格伦∙恩瓦伊拉,大卫∙科里根
0
aSmartMin有限公司,南非1759年赫利孔公园基维特街39号b加拿大地质调查局,加拿大安大略渥太华布斯街601号c
南非约翰内斯堡金山大道1号,威特沃特斯兰德大学地球科学学院d加拿大魁北克加蒂诺林恩街79号
0
文章信息
0
关键词:机器学习,矿产远景映射,
主成分分析,地球化学异常,稀土元
素
0
摘要
0
矿产勘探活动在财务上存在风险。已经开发了几种最先进的方法来减轻风险,包括使用主成分分析(PCA)和地理信息系统(GIS)
进行矿产远景预测建模。PCA和GIS方法目前被认为是生成矿产勘探目标的可接受方法。然而,它的一些局限性包括依赖样本的化学
计量(例如,矿物的存在),处理组成数据时需要对数比转换,以及手动解释和使用主成分来增强潜在的地球化学异常以进行远景
映射。在本研究中,我们通过开发一种新的数据驱动方法使用机器学习来概括PCA和GIS方法的基本思想。我们展示了一种新的工作
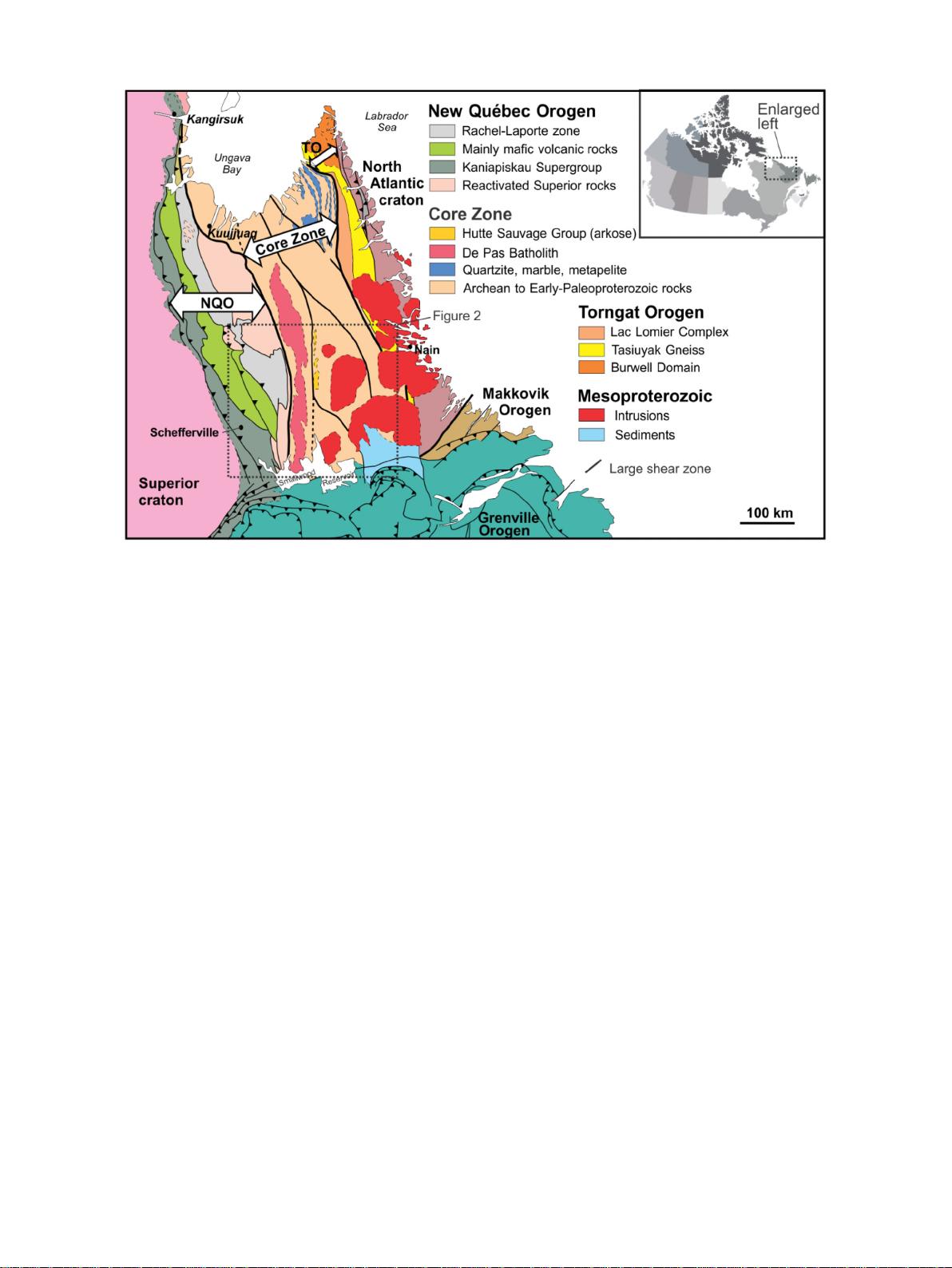
流程,能够使用加拿大东南部丘吉尔省(魁北克和拉布拉多)的多元素地球化学数据生成中间证据图层或最终的远景地图,该地区
以其稀土元素资源而闻名,并且收集了用于远景映射的数据。与已建立的基于多元数据和知识的混合方法相比,我们的新数据驱动
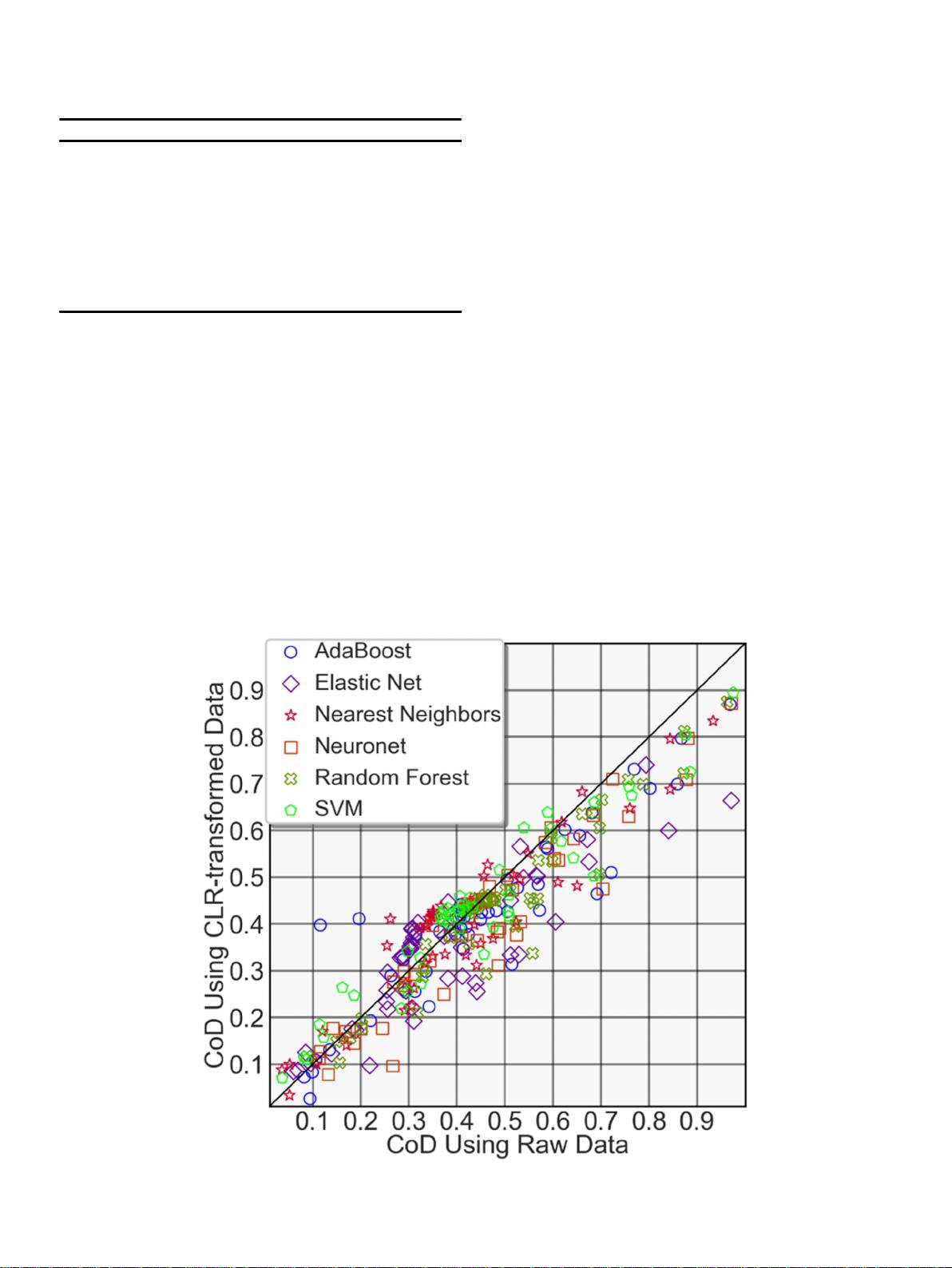
程序在大致相当的手动工作量基础上,能够更准确地识别单变量和多变量应用中的地球化学异常。我们的远景映射结果与研究区域
已知的地质异常相一致。这些发现对勘探目标生成可能具有更广泛的影响,其中必须使用稳健和有效的数据驱动方法来量化项目风
险(财务、环境、政治等)和地球化学异常。此外,我们的方法更具可复制性和客观性,因为在检测地球化学异常时不需要手动地
球科学解释。
0
1.介绍
0
远景映射将地球科学数据转化为地图,描绘出矿床或其代理物(例如指示元素)的
区域潜力或有利性,使用一些知识驱动和数据驱动方法的组合(例如,Chung和A
gterberg,1980年;Bonham-Carter,1994年;Harris和Pan,1999年;Wrig
ht和Bonham-Carter,1996年;Brown等,2000年;Carranza等,2008年;Ha
rris等,2015年;Grunsky和de
Caritat,2019年)。一个关键结果是勾画出有趣的区域(例如异常),可以优先
用于进一步的调查和解释。知识驱动的方法使用学科特定知识的启发式模型,例如
矿床特征
0
旨在指导数据的使用(例如地球化学和地球物理图)。数据驱动方法通常利用现有
的地面真相来训练勘探模型(Bonham-Carter,1994年;Wright和Bonham-Car
ter,1996年;Carranza,2008年,2009a,b),这使得这些方法更适用于棕地
而不是绿地勘探。然而,发现空间一致的地球化学异常是一种异常检测任务,可以
在变量和空间空间的某种组合中使用无监督的机器学习来进行,这不需要地面真相
。存在一种基于多元统计方法的数据驱动技术来发现异常过程(例如Carranza,2
008年;Grunsky和de
Caritat,2019年)。然而,它需要手动解释,因此依赖于某些学科知识。这
0
缩写词:ML,机器学习;REEs,稀土元素。*通讯作者。电子邮件地址:glen.
nwaila@wits.ac.za(G.T.Nwaila)。
0
ScienceDirect提供内容列表
0
地球科学中的人工智能
0
期刊主页:www.keaipublishing.com/en/journals/articial-intelligence-in-geosciences
0
https://doi.org/10.1016/j.aiig.2022.02.0022021年12月8日收到;2022年2月16日修订稿收到;2022年2月17日接受在2022年3月1日在线提供2666-5441/©2022年作者。由Elsevier
B.V.代表KeAiCommunicationsCo.Ltd.提供出版服务。本文是根据CCBY-NC-ND许可的开放获取文章(http://creativecommons.org/licenses/by-nc-nd/4.0/)。
0
地球科学中的人工智能2(2021)128-147

剩余19页未读,继续阅读
相关推荐






cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- SmartGit最新版本18.1.1,Git可视化操作更简单
- 探索环境公平:团队项目与可视化研究
- Deno分支的grammy_i18n:本地化支持与TypeScript集成
- EditPlus文本编辑器:Windows平台的好替代
- Code Compare:VS代码比较工具的官方免费安装版
- 全屏秒表倒计时工具:美观易用的计时软件
- 实现教育系统批处理与UI交互的EDUC-PEN-REG-BATCH-API
- IntelliJ Protobuf插件:高效支持Protobuf语言的开发工具
- 海康DS-8632N-E8固件20171211升级指南
- 手机联系人数据通过Service加载至缓存技术解析
- 像素小秘书V1.03绿色免费版:RPG游戏辅助工具
- 创新设计:防折书弹性书夹的原理与应用
- 代码构建的浪漫表白网页 - 学习新技术的项目展示
- 贝基·班伯里·摩根分析全球森林生产力趋势
- CyJsonView v2.3.1: 强大JSON处理与格式化工具
- Java基础入门到进阶全面提升指南
