Mix/UnMix:一种新型数据增强技术提升半监督目标检测性能
PDF格式 | 16.41MB |
更新于2025-01-16
| 159 浏览量 | 举报
"MUM:混合图像块和非混合特征块用于半监督目标检测"
在半监督学习(SSL)领域,尤其是半监督目标检测(SSOD)中,数据增强策略是至关重要的,因为它能帮助在缺乏标签信息的情况下创建有效的训练样本。传统的强增强方法可能在目标检测任务中存在问题,因为它们可能导致边界框位置信息的损失。针对这一挑战,研究人员提出了Mix/UnMix (MUM) 方法,这是一种创新的数据增强技术,旨在解决SSOD中的这一难题。
MUM的核心在于引入混合图像块和非混合特征块的概念。混合图像块允许在特征空间中对输入图像进行混合,而非混合特征块则用于保持和重构原始图像的信息,特别是目标的位置信息。通过这种方式,MUM能够在不损害边界框定位的情况下,利用插值正则化效果,从非插值伪标签中生成有意义的弱强增强对。这种方法的一个关键优势是它可以轻松地与其他SSOD方法结合使用,提升了整体的性能。
实验结果表明,MUM在MS-COCO和PASCAL VOC数据集上进行了广泛的验证,无论是在哪种SSOD基准协议下,均能显著提高平均精度(mAP)指标。这一成果证明了MUM的有效性,并且其源代码已经公开,可供其他研究者在实际项目中使用和进一步开发。
1. SSL和SSOD的背景
深度学习在计算机视觉领域的成功很大程度上归功于大量的标注数据。然而,获取这些标注数据特别是对于目标检测任务而言,既耗时又昂贵。SSL和SSOD的目标是利用有限的标注数据和丰富的未标注数据来训练模型,以提高模型的泛化能力。
2. 师生框架
多数SSL研究采用师生框架,教师网络通过时间集成生成监督信号,指导学生网络的学习。这种框架在减少对大量标注数据依赖的同时,能够利用未标注数据的潜力。
3. MUM的工作原理
MUM通过在特征空间中混合和重构图像,实现了对输入图像的增强,同时保持目标的定位信息。这使得模型能够处理插值正则化,生成高质量的训练对,从而提高SSOD的性能。
4. 应用与评估
MUM不仅易于集成到现有的SSOD方法中,还在多个标准数据集上展现了优越的性能提升,表明了其广泛的应用前景和实用性。
MUM为半监督目标检测提供了一种新的、有效的数据增强策略,解决了传统方法在边界框定位上的问题,为SSL和SSOD领域的研究提供了新的思路。
14512
0
MUM:混合图像块和非混合特征块用于半监督目标
检测
0
JongMokKim1,2JooYoungJang1,2SeunghyeonSeo2JisooJeong2JongkeunNa1NojunKwak2
0
1SNUAILAB,韩国2首尔国立大学,韩国
0
{win98man,jyjang1090,zzzlssh,soo3553}@snu.ac.kr,jake.na@snuailab.ai,nojunk@snu.ac.kr
0
摘要
0
许多最近的半监督学习(SSL)研究构建了师生架构,并通
过来自教师的生成监督信号来训练学生网络。数据增强策略
在SSL框架中起着重要作用,因为很难在不丢失标签信息的
情况下创建弱强增强的输入对。特别是在将SSL扩展到半监
督目标检测(SSOD)时,与图像几何和插值正则化相关的
许多强增强方法很难利用,因为它们可能会损害目标检测任
务中边界框的位置信息。为了解决这个问题,我们引入了一
种简单而有效的数据增强方法,Mix/UnMix(MUM),它
为SSOD框架的混合图像块提供非混合特征块。我们提出的
方法在特征空间中对混合输入图像块进行重构。因此,MU
M可以从非插值伪标签中享受插值正则化效果,并成功生成
有意义的弱强对。此外,MUM可以轻松应用于各种SSOD
方法之上。在MS-COCO和PASCAL
VOC数据集上进行的大量实验证明了MUM在所有测试的SS
OD基准协议中始终提高了mAP性能。代码发布在https://gi
thub.com/JongMokKim/mix-unmix。
0
1.引言
0
由于大规模数据集的可用性,深度神经网络在各种计算机视觉任务上取得了很大的进展。为了实现更好和更
具普遍性的性能,大量标记数据是不可或缺的,然而这需要大量的人力和时间进行注释[3,12,
31]。与图像分类不同,目标检测需要每个图像的类别标签和位置信息的配对,而不仅仅是图像的类别标签,
因此在目标检测中获取足够数量的标记数据更具挑战性。为了解决上述问题,许多最近的研究都致力于在使
用少量标记数据训练网络时利用丰富的未标记数据,称为半监督学习(SSL)和半监督目标检测(SSOD)。
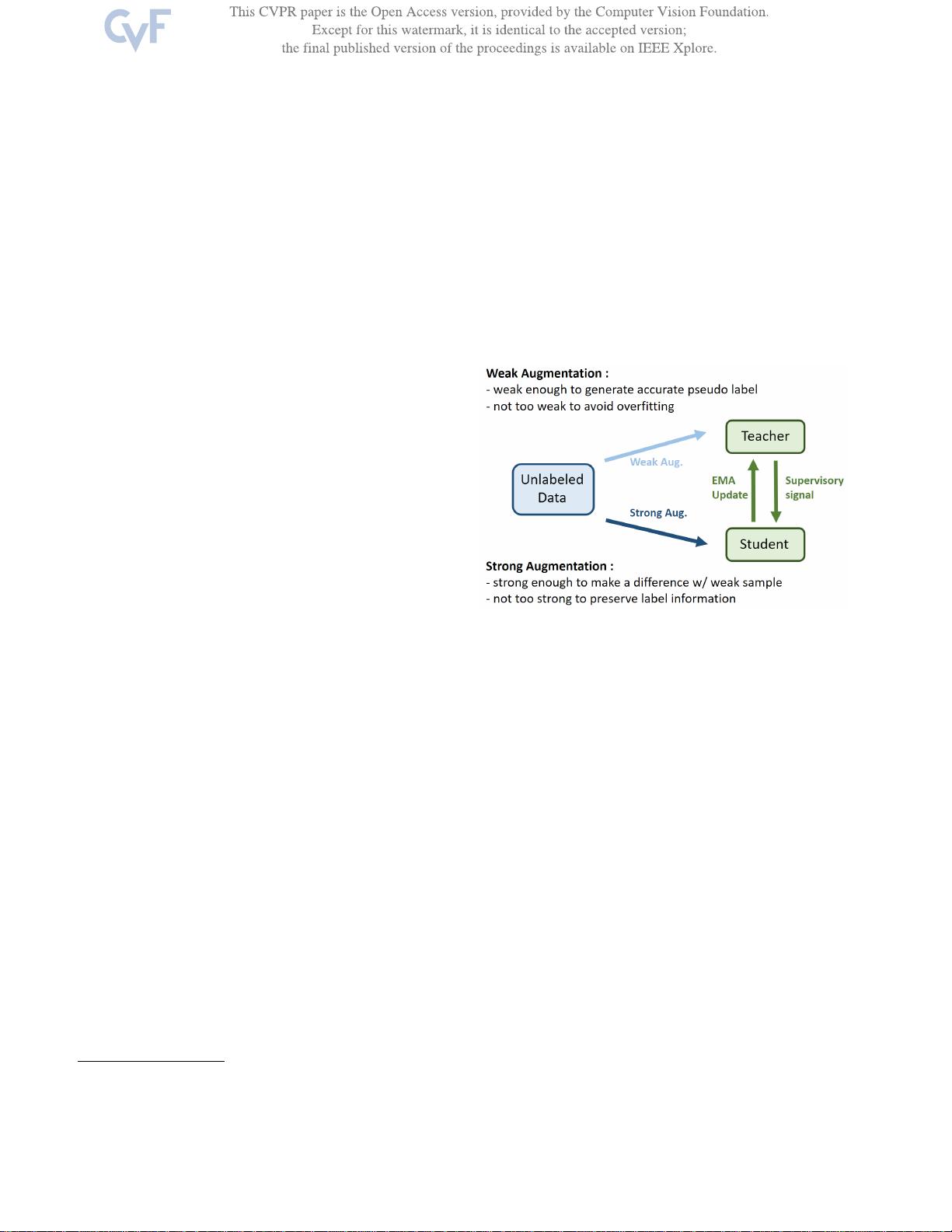
最近的许多SSL研究都依赖于师生框架,其中教师网络通常是学生的时间集成模型,生成监督信号并用这些
信号训练学生网络,如图1所示[23,
35]。数据增强在这个框架中起着重要作用,最近的大部分工作都将强增强输入应用于学生模型,而将弱增强
应用于教师[33,
38]。插值正则化(IR)是一种核心思想是插值输入的输出应该与原始输入的插值输出相似的数据增强技术,
最初是为监督学习开发的[46],并成功应用于教师-
0
本工作得到了韩国政府(MSIT)资助的NRF(2021R1A2C3006659)和IITP
(NO.2021-0-01343,人工智能研究生院项目)资助。
0
图1.
SSL的典型师生(伪标签)框架。在充分利用未标记数据时,构建
智能的教师和采用适当的数据增强策略以获得弱强对非常重要。
0
目标检测需要每个图像的类别标签和位置信息的配对,而不
仅仅是图像的类别标签,因此在目标检测中获取足够数量的
标记数据更具挑战性。为了解决上述问题,许多最近的研究
都致力于在使用少量标记数据训练网络时利用丰富的未标记
数据,称为半监督学习(SSL)和半监督目标检测(SSOD
)。最近的许多SSL研究都依赖于师生框架,其中教师网络
通常是学生的时间集成模型,生成监督信号并用这些信号训
练学生网络,如图1所示[23,
35]。数据增强在这个框架中起着重要作用,最近的大部分
工作都将强增强输入应用于学生模型,而将弱增强应用于教
师[33,
38]。插值正则化(IR)是一种核心思想是插值输入的输出
应该与原始输入的插值输出相似的数据增强技术,最初是为
监督学习开发的[46],并成功应用于教师-
下载后可阅读完整内容,剩余9页未读,立即下载
相关推荐






8 浏览量
7 浏览量

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- A7Demo.appstudio:探索JavaScript应用开发
- 百度地图范围内的标注点技术实现
- Foobar2000绿色汉化版:全面提升音频播放体验
- Rhythm Core .NET库:字符串与集合扩展方法详解
- 深入了解Tomcat源码及其依赖包结构
- 物流节约里程法的文档整理与实践分享
- NUnit3.vsix:快速安装NUnit三件套到VS2017及以上版本
- JQuery核心函数使用速查手册详解
- 多种风格的Select下拉框美化插件及其js代码下载
- Mac用户必备:SmartSVN版本控制工具介绍
- ELTE IK Web编程与Web开发课程内容详解
- QuartusII环境下的Verilog锁相环实现
- 横版过关游戏完整VC源码及资源包
- MVC后台管理框架2021版:源码与代码生成器详解
- 宗成庆主讲的自然语言理解课程PPT解析
- Memcached与Tomcat会话共享与Kryo序列化配置指南
