时空滤波自适应网络STFAN:视频去模糊新方法
125 浏览量
更新于2025-01-16
收藏 3.91MB PDF 举报
"本文主要介绍了视频去模糊领域中的一种新方法——时空滤波自适应网络(STFAN),该方法旨在解决由摄像机抖动、物体运动和深度变化引起的空间变化模糊问题。STFAN结合了前一帧的恢复信息与当前帧的模糊图像,通过滤波器自适应卷积(FAC)层实现帧间特征对齐和模糊去除,最后通过重构网络融合特征以恢复清晰视频帧。实验表明,STFAN在准确性、速度和模型大小等方面优于现有方法。"
正文:
在视频处理领域,视频去模糊是一个极具挑战性的任务,尤其在手持设备和无人机拍摄的动态场景中,由于设备抖动和快速运动,往往会导致视频出现不期望的模糊。这种低质量的视频不仅影响视觉体验,还会妨碍诸如目标跟踪、视频稳定和SLAM等高级视觉任务的性能。因此,开发高效视频去模糊算法显得至关重要。
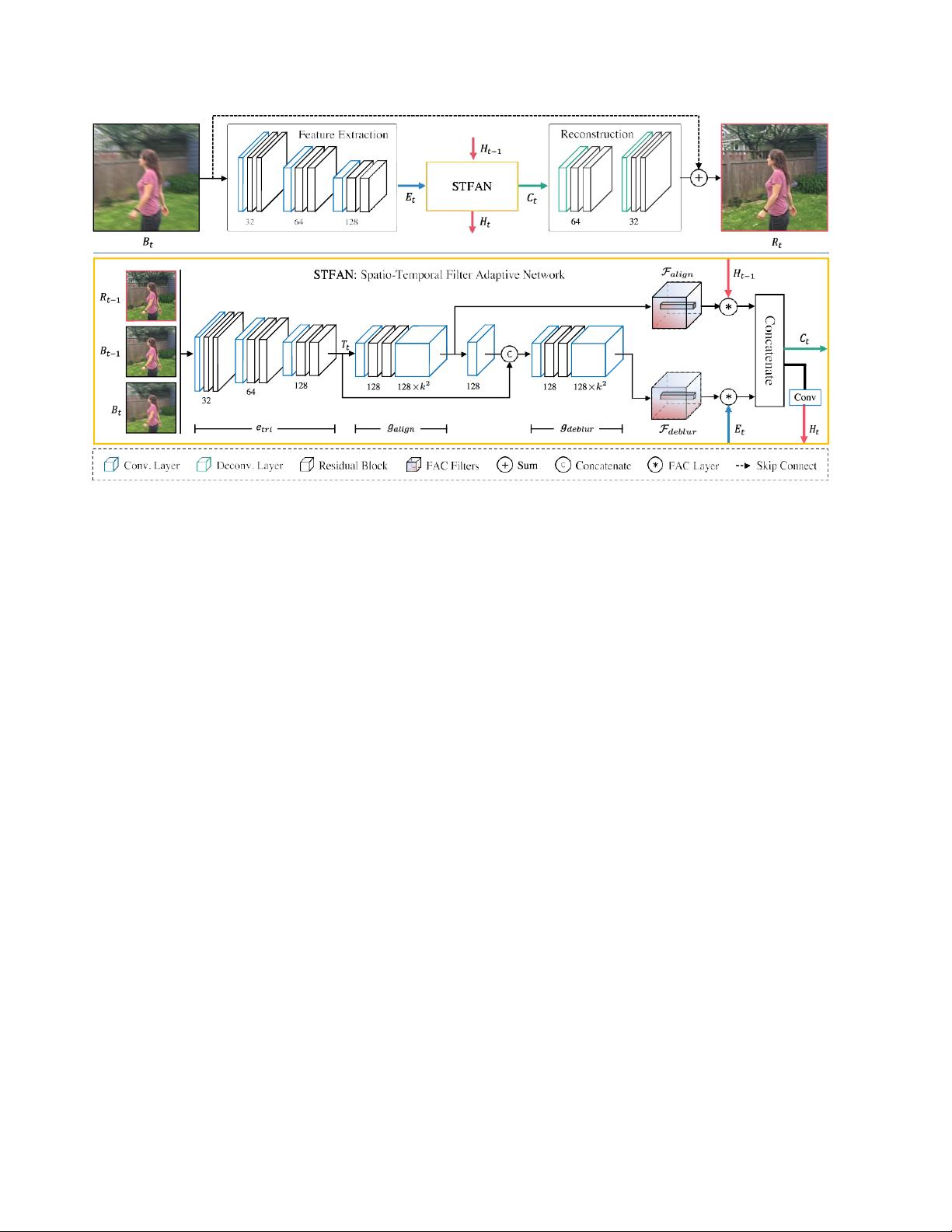
传统的视频去模糊方法通常依赖于光流估计来对齐连续帧或近似模糊核。然而,光流估计的不准确可能导致去模糊过程中产生伪影,或者无法有效去除模糊。针对这一问题,作者提出了时空滤波自适应网络(STFAN)。STFAN创新地将对齐和去模糊过程整合在一个统一的神经网络框架中,利用前一帧的去模糊图像和当前帧的模糊图像作为输入。通过引入滤波器自适应卷积(FAC)层,STFAN能够对齐前一帧的去模糊特征,并从当前帧的特征中消除空间变化的模糊影响。
FAC层是STFAN的核心组件,它允许网络根据当前帧的特性动态调整滤波器,从而增强特征对齐和模糊去除的效果。通过这种方式,STFAN能更好地处理由于大运动和空间变化导致的模糊问题。实验结果表明,与其他如SRN[38]、GVD[9]、OVD[10]和DVD[36]等视频去模糊方法相比,STFAN在恢复清晰度、运算速度和模型复杂度上都表现出优势。
为了进一步验证STFAN的有效性,作者在基准数据集和真实视频上进行了定量和定性评估。实验结果显示,即使在具有大运动和空间变化模糊的困难场景中,STFAN也能生成更清晰的视频帧。当移除FAC层时,去模糊性能显著下降,这证明了FAC层在帧对齐和去模糊过程中的关键作用。
时空滤波自适应网络(STFAN)为视频去模糊提供了一种新的解决方案,它通过利用帧间信息和自适应滤波器进行特征融合,有效提升了去模糊效果,对于提高视频质量和推动相关视觉任务的发展具有重要意义。
2484
图2:拟议的网络结构。它包含三个子网:时空滤波自适应网络(STFAN)、特征提取网络和重建网络。给定三
重图像(模糊的B
t-1
和恢复的R
t-1
图像
和当前输入图像
B
t
),子网络
STFAN
按顺序生成对准滤波器
F
align
和去模糊滤波器
F
deblur
然后,使用所提出的
FAC
层,
STFAN
将前一时间步的去模糊特征
H
t
-
1
与当前时间步对齐,并从从当前模糊图像提取的特征
E
t
中去
除模糊
通过特征提取网络。最后,利用重构网络从融合后的特征
Ct
中恢复清晰图像。
k
表示FAC层的滤波器大小。
多图像去模糊。许多方法利用多幅图像来解决来自视
频、突发或立体图像的动态场景去模糊[41]和[32]的算
法使用预测的光流来分割具有不同模糊的层并逐层估
计模糊。此外,Kim
等人
[9]将光流视为模糊核的线形
近似,其迭代地优化光流和模糊核。基于立体的方法
[42,34,29]从立体图像估计深度,其用于预测逐像
素模糊核。Zhou
等人。
[45]提出了一种具有深度感知
和视图聚合的立体去模糊网络。为了提高泛化能力,
Chen
等人
[2]提出了一种基于光流的重新模糊步骤来重
建模糊输入,该步骤用于通过自监督学习来微调去模
糊最近,已经提出了几种端到端CNN方法[36,10,15]
用于视频去模糊。在使用光流进行图像对准
[36]和[15]聚合相邻帧的信息以恢复清晰图像。Kim
等
人。
[10]应用时间递归网络将前一个时间步的特征传
播到当前时间步的特征中 尽管运动可以是模糊估计的
有用指导,但Aittala et al. [1]提出了一种通过在突发图
像的特征之间重复交换信息的顺序无关方式的突发去
模糊网络。
核预测网络核(滤波)预测网络(KPN)近年来在低
层次视觉任务中取得了迅速的进展. Jia
等人
[11]首先提
出了动态滤波器网络,它由一个滤波器预测网络和一
个动态滤波层组成,前者预测以输入图像为条件的内
核,后者将生成的内核应用于另一个输入。 他们的方
法显示了视频和立体声预测任务的有效性。Niklaus
等
人
[24]将内核预测网络应用于视频帧内插,将光流估
计和帧合成合并到一个统一的框架中。为了减轻对存
储器的需求,他们随后提出了可分离卷积[25],该卷
积估计两个可分离的1D内核 to approximate近似2D
kernels内核.在[22]中,他们利用KPN进行突发帧对齐
和去噪,使用相同的预测内核。[13]使用生成的动态
上采样滤波器从低分辨率输入然而,所有上述方法都
直接在图像域中应用预测的内核(滤波器)。此外,
Wang
等人。
[39]提出了用于图像超分辨率的空间特征
变换(SFT)层。它为像素特征模生成变换参数
的特征,它可以被认为是在特征域的核大小为1×1的
KPN
剩余10页未读,继续阅读
182 浏览量
720 浏览量
107 浏览量
2021-09-29 上传
200 浏览量
2023-02-23 上传
2021-03-12 上传
2023-02-23 上传
点击了解资源详情

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- VB通过Modbus协议控制三菱PLC通讯实操指南
- simfinapi:R语言中简化SimFin数据获取与分析的包
- LabVIEW温度控制上位机程序开发指南
- 西门子工业网络通信实例解析与CP243-1应用
- 清华紫光全能王V9.1软件深度体验与功能解析
- VB实现Access数据库数据同步操作指南
- VB实现MSChart绘制实时监控曲线
- VC6.0通过实例深入访问Excel文件技巧
- 自动机可视化工具:编程语言与正则表达式的图形化解释
- 赛义德·莫比尼:揭秘其开创性技术成果
- 微信小程序开发教程:如何实现模仿ofo共享单车应用
- TrueTable在Windows10 64位及CAD2007中的完美适配
- 图解Win7搭建IIS7+PHP+MySQL+phpMyAdmin教程
- C#与LabVIEW联合采集NI设备的电压电流信号并创建Excel文件
- LP1800-3最小系统官方资料压缩包
- Linksys WUSB54GG无线网卡驱动程序下载指南
