DCVNet:实时光流估计的新方法
PDF格式 | 1.83MB |
更新于2025-01-16
| 187 浏览量 | 举报
"DCVNet:扩张成本体积网络是一种新的快速光流估计模型,旨在解决光流估计中的计算效率问题。该模型由东北大学和马萨诸塞大学的研究者提出,通过构建不同膨胀因子的成本卷来同时处理小位移和大位移,从而减少了计算负担。与传统的粗到细或递归处理方式不同,DCVNet采用一次性前馈处理,不需要顺序处理策略,能够在中端1080ti GPU上实现30fps的实时推理速度,同时保持与现有方法相当的精度。"
光流估计是计算机视觉领域的一个基础任务,旨在找出连续视频帧间像素的运动轨迹。自20世纪80年代以来,光流估计已经历了多种方法的发展,从早期的物理模型到现在的深度学习技术。深度神经网络的引入显著提升了光流估计的性能,但同时也带来了计算复杂度的增加,导致推理速度变慢。
为了解决这一问题,研究者们开始将传统的优化方法与深度学习结合。成本体积是其中一种关键的表示方法,它能有效地编码像素间的相似性,用于寻找最佳对应。然而,处理大位移时,需要较大的邻域半径,这会增加计算成本。DCVNet的创新之处在于它构建了不同膨胀因子的成本体积,通过这种方式,模型能够同时考虑短距离和长距离的像素运动,而无需进行多次的精细处理。
在DCVNet中,膨胀的成本体积通过关联转换成所有可能位移的插值权重,进而得到光流估计。模型结构基于U-Net,通过膨胀操作(dilation)来扩大感受野,而不需要增加网络深度或宽度,从而减少了计算资源的消耗。此外,通过一次性前馈处理,DCVNet避免了递归或序列处理的需要,提高了运行效率。
与PWC-Net和RAFT等代表性方法对比,DCVNet在保持相似精度的同时,实现了更快的推理速度。这使得DCVNet在实时应用如场景流估计、动作识别和视频编辑等领域具有潜力。尽管深度学习方法在光流估计上的表现不断改善,但如何在保证精度的同时优化计算效率仍然是一个重要的研究方向。DCVNet的提出为这一挑战提供了一个有效的解决方案。
5150
DCVNet:用于快速光流的扩张成本体积网络
东北大学
Boston
,
MA
02115
电子邮箱:
h.jiang@
northeastern.edu
Erik Learned-Miller
马萨诸塞大学阿默
斯特分校
Amherst
,
MA
01003
elm@cs.umass.edu
摘要
捕获跨两个输入图像的可能对应的相似性的成本当
对对应进行采样以构建成本体积时,需要大的邻域半
径来处理大的位移,从而引入显著的计算负担。为了
解决这个问题,通常采用成本体积的粗到细或递归处
理,其中具有小半径的局部邻域中的对应采样就足够
了。在本文中,我们提出了一种替代方案,通过构建
不同的膨胀因子的成本卷,以同时捕获小位移和大位
移。一个有
sikp con
的
U
网
PWC-Net
筏
DCVNet
(Ours)
dilution:D
成本量
⋯
GRU
光流
光流
光流
采用关联将膨胀的成本体积转换为所有可能的捕获位
移之间的插值权重,以获得光流。我们提出的模型
DCVNet
只需要处理一次成本量在一个简单的前馈方
式,而不依赖于顺序处理策略。
DCVNet
获得了与现有
方法相当的精度,并实现了实时推理(在中端
1080ti
GPU
上为
30 fps
)。
1.
介绍
光流场作为一个密集匹配问题,是关于估计两个连
续视频帧之间每个像素这是计算机视觉中一个经典且
长期研究的问题,可以追溯到20世纪80年代初[8]。光
流 在 广 泛 的 其 他 问 题 中 有 应 用 , 例 如 场 景 流 估 计
[23],动作识别[25]以及视频编辑和合成[3]。
与许多其他计算机视觉问题一样,光流估计的最新
方法都基于深度神经网络。然而,在开始时,光流的
深度为了缩小性能差距,一种方法是堆叠多个网络以
增加容量,
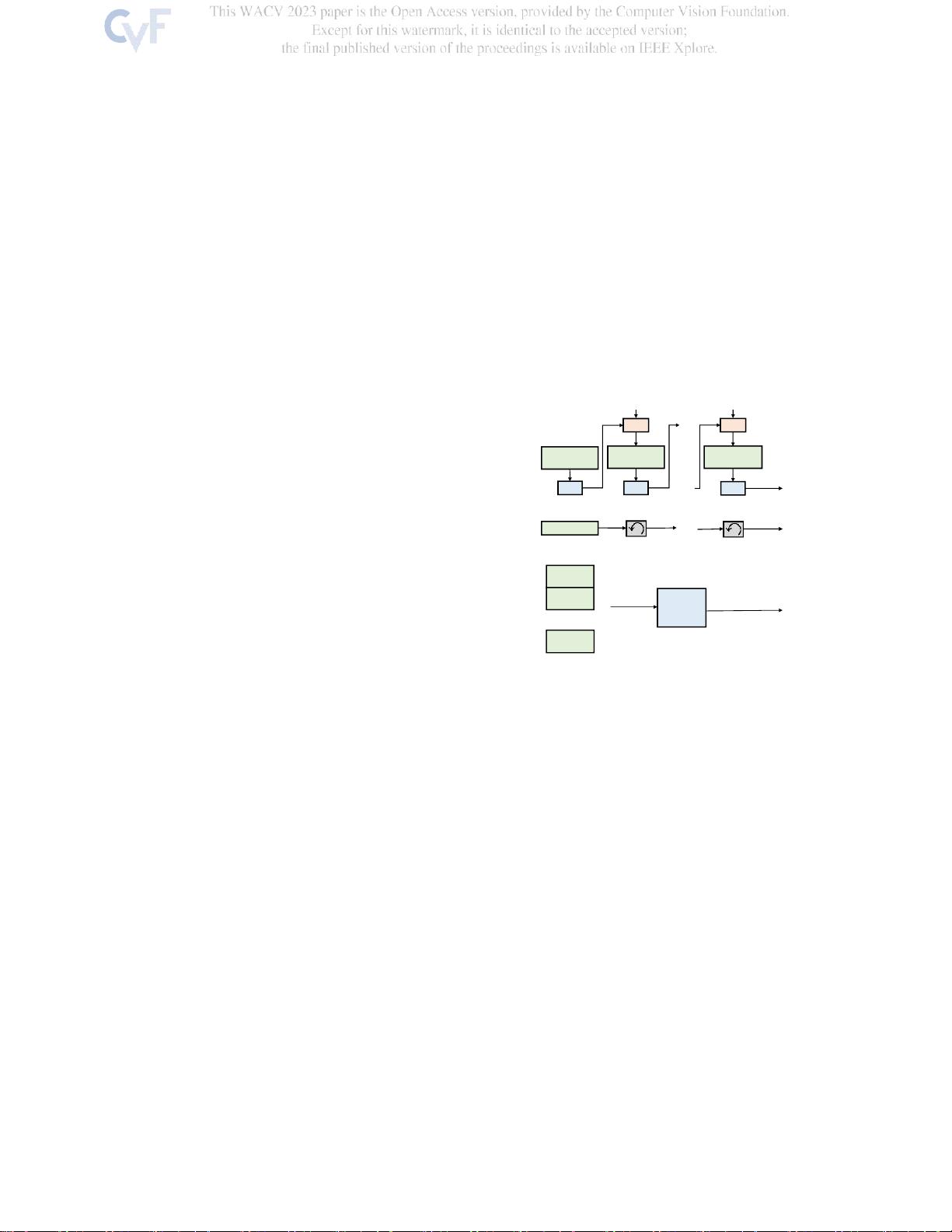
图1. 我们所提出的模型,DCVNet,COM-与现有的两个代
表性的方法的说明。 DCVNet是现有方法的替代方案,它不
需要对成本量进行顺序处理。其核心思想是构造具有不同膨
胀率的成本体积,以同时捕 获小位移和 大位移它在中端
1080ti GPU(30 fps)上实现了实时推理,并具有与现有方
法相当的精度
[12]这是一个很大的进步。然而,网络容量的增加导
致了巨大的网络和较慢的推理。从[24]开始,越来越
多来自传统最优流量估计方法的经典原理被纳入神经
网络设计中特别是,成本体积,这是一个更有区别性
的表示光流相比,级联的特征表示的两个图像,现在
是一个重要组成部分的国家的最先进的方法。
为了构建成本量,我们需要沿着水平和垂直方向对
邻域中两个输入图像之间的位置对进行采样,以计算
它们的相似度(或成本)。需要大的邻域来捕获大的
位移,但是这导致非常大的成本体积和显著的计算负
担。结论
成本量
成本数量金字
塔第一
⋯
conv
conv
conv
成本数量金字
塔N
成本数量金字
塔第0
经纱
经纱
成本量
扩张:1
成本量
扩张:2
conv
下载后可阅读完整内容,剩余8页未读,立即下载
相关推荐




cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 普天身份证阅读器新版二次开发包发布
- C# 实现文件的数据库保存与导出操作
- CkEditor增强功能:轻松实现图片上传
- 掌握DLL注入技术:测试工具使用与探索
- 实现带节假日农历功能的jQuery日历选择器
- Spring循环依赖示例:深入理解与Git代码仓库实践
- ABB PLC液压阀门控制程序开发指南
- 揭秘4核旋风密版626象棋引擎的超牛实力
- HTML5实现的经典游戏:小霸王坦克大战源码分享
- 让Visual Studio兼容APM硬件信息的方法
- Kotlin入门:创建我的第一个应用
- Android语音识别技术研究报告与应用分析
- 掌握JavaScript基础:第8版教程源代码解析
- jQuery制作动态侧面浮动图片广告特效教程
- Android PinView仿支付宝密码输入框源码分析
- HTML5 Canvas制作的围住神经猫游戏源码分享
