点云语义分割新方法:SemAffiNet与语义仿射变换
PDF格式 | 1.18MB |
更新于2025-01-16
| 114 浏览量 | 举报
"本文介绍了点云语义分割领域的一项新方法——SemAffiNet,该方法引入了语义仿射变换来提升点云特征的语义信息,以解决局部几何表示可能导致的不同类别混淆问题。SemAffiNet利用Transformer的注意力机制,结合类特定的仿射参数,增强中层点云特征,提高分割准确性。实验证明,该方法在ScanNetV2和NYUv2数据集上的表现优越,并具有良好的推广能力。代码已开源。"
在点云语义分割领域,传统的做法常常采用编码器-解码器架构,从中层特征中提取几何信息。然而,这种依赖于局部几何表示的方法可能无法有效地区分外观相似或空间相邻的不同类别的点。为解决这一问题,SemAffiNet提出了语义仿射变换,这是一种针对中层特征的处理方式,通过类特定的仿射参数来增强语义信息。这样,即使在局部特征纠缠的情况下,也能更好地分辨不同类别的点。
具体来说,SemAffiNet首先从输入点云中选取局部区域(如图1所示的红色圆圈),提取中层特征。由于不同类别的点在特征空间中可能存在交错,这可能导致分割错误。为了解决这个问题,SemAffiNet预测每个类别的仿射参数,然后运用这些参数对中层特征进行变换,使得同一类别的点靠拢,不同类别的点分离。这种变换利用了Transformer的注意力机制,可以隐式和显式地捕捉局部区域的全局结构。
实验部分,SemAffiNet在ScanNetV2和NYUv2这两个广泛使用的3D点云数据集上进行了评估。这些实验证据表明,无论是在定性还是定量的分析中,SemAffiNet都表现出优于现有方法的性能,并且具有良好的泛化能力。这意味着该模型不仅在训练数据集上表现优秀,还能有效地应用于新的、未见过的数据。
此外,值得注意的是,SemAffiNet的代码已经公开,这为研究者和开发者提供了实践和改进这一方法的机会。通过开源代码,社区可以进一步探索语义仿射变换在点云分割和其他相关任务中的潜力,推动点云处理技术的发展。
SemAffiNet通过创新的语义仿射变换,提高了点云语义分割的准确性和鲁棒性,为点云处理领域带来了一种新的、有前景的技术。这一成果对于自动驾驶、机器人操作以及虚拟现实等依赖于精确3D环境理解的应用有着重要的意义。
11821
X
X
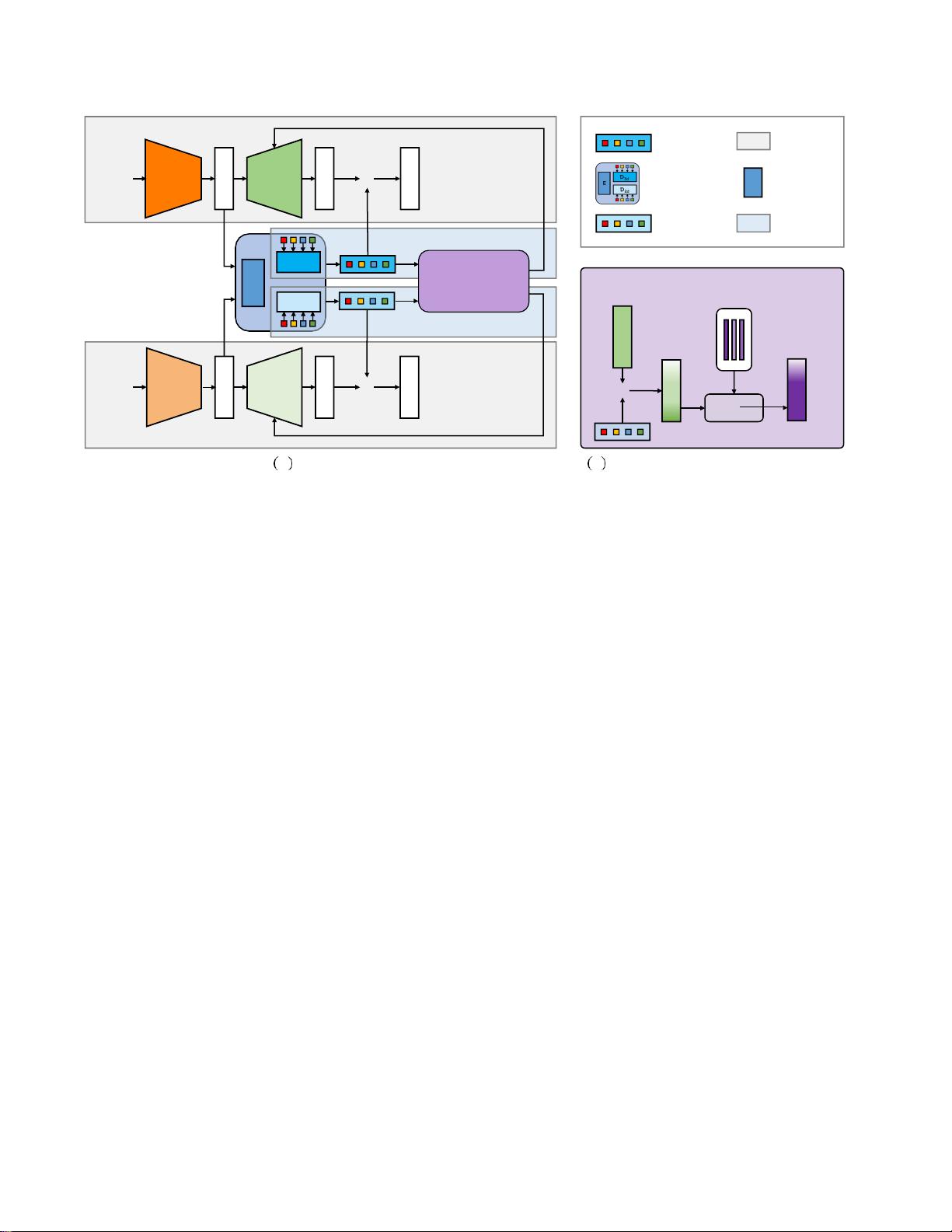
SemAffiNet语义仿射变换模块
图
2.
建议的网络体系结构的图示。(a)显示了
SemAffiNet
的管道,它由两个主干分支(灰色),一个隐式语义感知模块
(
ISAM
,深蓝色)和两个显式语义感知模块(
ESAM
,浅蓝色虚线)组成。此外,
ESAM
由
Transformer
解码器和语义仿射变
换模块组成,这在(b)中进一步示出。我们计算类特定的仿射参数的加权和,以获得中级点的语义仿射参数,中级分类置信
度作为线性组合权重。
转换为中级功能。因此,我们不需要增加模型规模的
不同聚合模块。此外,我们对中间层的语义指导比仅
仅多级监督更强。
用于分割的Transformer。Transformer [55]在许多计算
机视觉任务中取得了巨大成功,例如分类[17,36],
检测[5]和重建[64]。最近的研究采用了Transformer中
的注意力机制,以利用长程相关性进行更深层次的上
下文理解和更好的分割结果[21,68,70]。Maskformer
[9]提出了一种掩码分类模型,该模型利用Transformer
来预测二进制掩码,并统一了语义级和实例级分段。
SOTR [22]提出基于Transformer atten- tion模块动态生
成实例分割掩码。
虽然我们在SemAffiNet中使用了与Maskformer类似
的掩模分类结构,但我们将此想法从2D图像处理迁移
到3D点云理解,这并不简单。此外,我们提出了语义
仿射变换,以进一步加强掩模分类管道,这带来了更
多的进展,掩模分类根据我们的消融研究。
3.
方法
在接下来的部分中,我们将首先概述3.1节中提出的
SemAffiNet。那么我们将
详细介绍了该架构,在3.2节中介绍了所提出的语义仿
射变换,在3.3节中揭示了我们如何将其包装成即插即
用的显式语义感知模块,并在3.4节中介绍了辅助隐式
语义感知模块。最后,我们将在3.5节中介绍损失函数
设计。
3.1.
概述
我们精心设计了SemAffiNet来对传统编码器-解码器
模型的中级特征进行语义仿射变换。图2示出了总体架
构,其可以分为以下三个部分:(1)骨干,(2)显
式语义感知模块(ESAM),(3)隐式语义感知模块
(ISAM)。
首先,SemAffiNet的主干选择是灵活的,我们提出
的模块可以很容易地添加到任何编码器-解码器分割架
构。我们选择由2D和3D模态的两个编码器-解码器分
支组成的BP-Net [26详情请参阅BPNet文件或我们的补
充材料。
最重要的是,ESAM将我们提出的语义仿射转换包
装 成 一 个 即 插 即 用 模块 , 该模 块 使用 专 门 设 计 的
Transformer 解码器显式 地利用中级 特征中 的语 义信
息。如图2所示,我们采用两个ESAM模块,
中级
特征
类别特异
仿射参数
中级
类别预测
语义仿射
参数
⊗
加权
总和
点水平
类别掩膜
骨干
Transformer
ISAM
像素级
类别掩膜
Esam
E
点
云
编码器
解码器
⊗
逐点
分割
三维
E
语义仿射
变换模块
图像编码器
解码器
⊗
每像素
分割
D
2d
剩余10页未读,继续阅读
相关推荐






cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- DeepFreeze密码移除工具6.x版本使用教程
- MQ2烟雾传感器无线报警器项目解析
- Android实现消息推送技术:WebSocket的运用解析
- 利用jQuery插件自定义制作酷似Flash的广告横幅通栏
- 自定义滚动时间选择器,轻松转换为Jar包
- Python环境下pyuvs-rt模块的使用与应用
- DLL文件导出函数查看器 - 查看DLL函数名称
- Laravel框架深度解析:开发者的创造力与学习资源
- 实现滚动屏幕背景固定,提升网页高端视觉效果
- 遗传算法解决0-1背包问题
- 必备nagios插件压缩包:实现监控的关键
- Asp.Net2.0 Data Tutorial全集深度解析
- Flutter文本分割插件flutter_break_iterator入门与实践
- GD Spi Flash存储器的详细技术手册
- 深入解析MyBatis PageHelper分页插件的使用与原理
- DELPHI实现斗地主游戏设计及半成品源码分析
