TF-Blender:强化视频对象检测的时间关系与特征融合
6 浏览量
更新于2025-01-16
收藏 2.06MB PDF 举报
TF-Blender是一种创新的视频对象检测方法,专为解决视频帧间特征退化问题而设计。传统的视频检测技术往往依赖于相邻帧间的特征聚合来提高检测性能,但这些方法通常聚焦于高级别特征的融合,而忽略了低级别的时间关系模型。TF-Blender旨在弥补这一不足。
该方法由三个关键模块组成:
1. 时间关系建模模块:这个模块负责捕捉当前帧与相邻帧之间的时空关系,通过保留空间信息,帮助检测算法更好地理解动态场景中的物体。它通过分析帧与帧之间的局部时空变化,增强了对视频流连续性的理解。
2. 特征聚合过程:不同于传统方法简单地平均或加权融合相邻帧的特征,TF-Blender采用一种更细致的方式,对每一对相邻帧进行处理,生成更为丰富的特征表示。这种策略能够捕获更精确的时空特征关联,提高了特征的有效性。
3. 特征混合器:作为整个流程的整合部分,特征混合器将前两个模块的输出进行集成,生成最终的特征表示,这些特征不仅包含当前帧的信息,还融入了周围帧的时空上下文。这样,混合后的特征能够提供更强的表示能力,有助于提高视频对象检测的准确性。
TF-Blender的优势在于其灵活性,可以轻松地嵌入到现有的检测网络中,无需大幅度修改架构,就能显著提升检测性能。在ImageNetVID和YouTube-VIS等基准测试中,TF-Blender展现出明显的性能提升,证明了其在复杂场景中的优越性。该研究的代码可在GitHub上获取,以便其他研究人员和开发者进一步探索和应用。
TF-Blender通过对时间关系的深入建模和特征的精细化聚合,有效应对了视频对象检测中的挑战,展示了在解决视频帧外观变化和特征退化方面的重要突破。其简单易用的特性使其成为未来视频处理领域的一个有力工具。
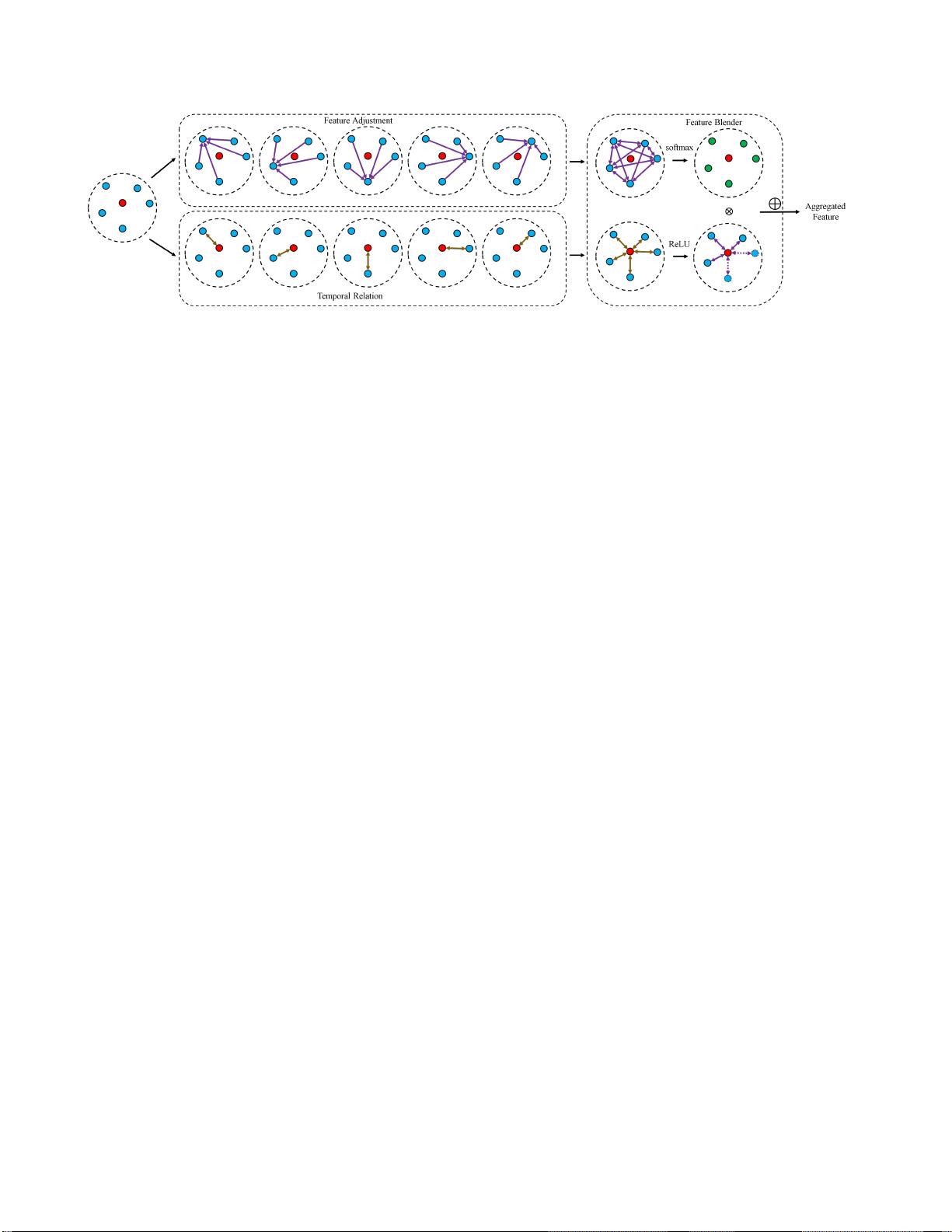
8140
W
F
F
W
∈ N
Σ
图2. 我们的TF-Blender框架包括三个关键模块:a)时间关系模块:特征关系函数g(
fi
,
fi
)用作输入以学习用于特征混合器的
自适应权重(
fi
,
fi
)。2)特征调整模块:每个相邻帧特征
fj
与其他相邻特征聚合以生成特征表示(
fi
,
fj
)。3)功能搅拌机模
块:(
fi
,
fj
)和 (
fi
,
fi
,
j
)被组合以将当前帧的特征与相邻帧的动态数量的特征进行聚合。
跳转
这需要跨帧分割和跟踪实例。然而,当前的大多数方
法,如MaskProp [2]、EnsembleVIS [30],关注于如何
跨帧跟踪实例,而不是如何生成用于检测、分割和跟
踪的高质量特征。因此,在这项工作中,我们提出了
一个更有原则的解决方案,有效地转换和利用视频对
象检测任务的宝贵的时间特征。
2.2.
关系学习
关系学习被广泛用于不同的任务(即,点云分析
[29,9]和图像理解[28,39])来描述当前特征及其相
邻 特 征 之 间 的 关 系 RS-CNN [29] 扩 展 了 规 则 网 格
CNN,以使用点之间的几何拓扑约束来捕获局部点云
特征。类似地,PointConv [37]通过计算局部协方差和
局部方差来对特征关系进行建模。
不同于这些方法,我们提出了一个更一般的方法,
关系学习的特征聚合。我们的TF-Blender可以鲁棒地
描绘当前帧和邻近帧的特征之间的显著对应关系,并
且仅利用有价值的特征进行更强的检测。
3.
TF-Blender
3.1.
初步和总体管线
传统的特征聚合方法
[42
,
36
,
25
,
34]
通常以受
约束的方式工作。给定当前帧的一组相邻帧
Fj
F
i
,
F
j
(
F
i
),它们的对应特征
f
j
基于与
F i
的特征相似性被相等地加权,以便聚合时间特征
Δ
f
i
:
坐标和点云密度。这两种方法都在几何空间中捕获 相
反,DGCNN
[35]定义了捕捉局部点关系
∆
f
i
=
F
j
∈N
(
F
i
)
(
wij
×
fj
)
。
(
一)
并在每一层动态地更新核的邻域。
类似地,一些最近的工作尝试利用关系学习用于对
象检测。受[17]提出的用于静止图像对象检测的对象
关系模块的启发,RDN [12]引入了关系蒸馏网络来基
于对象关系聚合特征,以改善视频对象检测的特征。
MEGA [7]扩展了RDN的关系学习,并提出了一种内存
增强的全局-局部聚合网络,该网络有组织地管理用于
聚合的远程(全局)特征和短程(局部)特征,以增
加当前时间的特征表示用于检测。然而,上述方法
[17,12,7]的焦点是选择用于聚合的较高级视频帧,
而不是对较低级时间关系进行建模以增加特征表示。
因此,特征聚合的主要问题是
计算权重
w
ij
并选择表示
特征
f
j
。
不同于上述简单的范例,我们从一个一般的
角度来开发的时间特征。为了实现这一目标,我们的
TF-Blender工艺品上的三个新的架构模块,时间关系
模块,特征调整模块,和特征混合器模块,以启动检
测性能(见图2)。
3.2.
时间关系
我们的时间关系模型之间的关键帧和它的邻居的
对应关系为了实现该目标,
现有方法使用
W
(
fi
,
fi
)
来计算
特征图中的每个像素上 这种方法在聚合过
程中忽略了特征图的局部空间信息
,这导致了特征图
中严重的离群点问题。如图
3
(
a
)所示,两个相邻
的
-
剩余11页未读,继续阅读
150 浏览量
236 浏览量
点击了解资源详情
204 浏览量
2021-04-11 上传
150 浏览量
171 浏览量
282 浏览量
1457 浏览量

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Openaea:Unity下开源fanmad-aea游戏开发
- Eclipse中实用的Maven3插件指南
- 批量查询软件发布:轻松掌握搜索引擎下拉关键词
- 《C#技术内幕》源代码解析与学习指南
- Carmon广义切比雪夫滤波器综合与耦合矩阵分析
- C++在MFC框架下实时采集Kinect深度及彩色图像
- 代码研究员的Markdown阅读笔记解析
- 基于TCP/UDP的数据采集与端口监听系统
- 探索CDirDialog:高效的文件路径选择对话框
- PIC24单片机开发全攻略:原理与编程指南
- 实现文字焦点切换特效与滤镜滚动效果的JavaScript代码
- Flask API入门教程:快速设置与运行
- Matlab实现的说话人识别和确认系统
- 全面操作OpenFlight格式的API安装指南
- 基于C++的书店管理系统课程设计与源码解析
- Apache Tomcat 7.0.42版本压缩包发布
