深度鲁棒3D人脸姿态跟踪:对抗遮挡与表情变化
PDF格式 | 2.14MB |
更新于2025-01-16
| 35 浏览量 | 举报
"本文深入探讨了在复杂环境如无约束场景和存在遮挡情况下的三维人脸姿态跟踪技术。针对这一挑战,研究者提出了一种基于深度的生成框架,旨在实现姿态跟踪与人脸模型自适应的无缝结合。他们设计了一个统计三维人脸模型,能够处理并预测人脸模型的多样性及不确定性。与依赖于ICP(Iterative Closest Point)算法的常规方法不同,新方法利用面部模型的可见性来正则化姿态估计,提高了对遮挡的抵抗能力。
在Biwi和ICT-3DHP数据集上的实验结果显示,该框架在性能上超越了现有的基于深度的跟踪方法。这一创新的跟踪系统能够在严重遮挡和各种表情变化下保持鲁棒性。例如,即使在人脸部分被遮挡时(如图1(a)所示),系统仍能准确估计出人脸姿态,且红色标记的可见点显示了模型与输入点云的匹配。此外,该系统在不同表情下(如图1(b)所示)也能稳定跟踪,确保人脸身份不受表情变化的影响。
传统的RGB视频上的面部姿态跟踪方法在光照变化、阴影和遮挡等条件下表现受限。然而,随着实时深度传感器的普及,深度数据为3D面部姿态跟踪提供了新的可能性,尤其是在解决遮挡问题方面。尽管已有方法尝试结合RGB和深度数据,但当RGB质量下降时,这些方法的可靠性仍有待提高。因此,研究仅使用深度数据的跟踪系统变得至关重要,特别是在保护隐私和RGB数据不可用的场合。
该研究为无约束场景下的三维人脸姿态跟踪提供了新的解决方案,通过深度数据的高效利用和创新的遮挡处理策略,提升了跟踪的鲁棒性和准确性。这一工作为未来的人脸识别、人机交互、虚拟现实和增强现实等领域提供了重要的技术支持,有望推动相关应用的进步。"
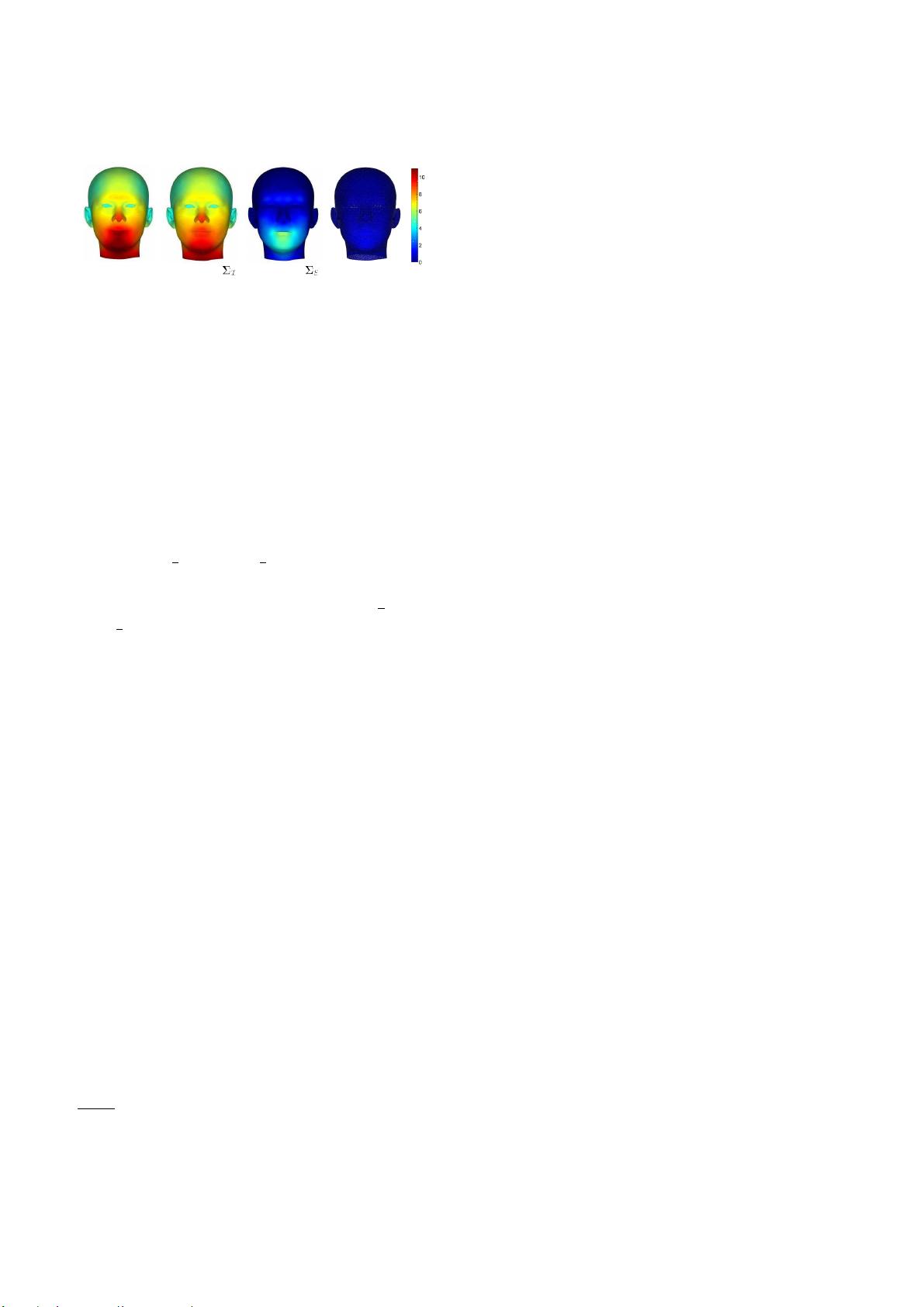
4490
exp
I
D
N
exp
N N
I
D
exp
(
a
)总体差异
图
2.
在
FaceWare
内部数据集中训练的人脸模型的统计数据
[12]
。(
a
)总体形状变化。(
b
)
-
(
c
)分别通过宽度和宽度的形状变
化
。
(d)
方程中剩余项的形状变化
。(二)、形状变化被设
置为边缘化的每个顶点分布的一个
被跟踪的面部被可靠地预测。这样的模型本质上提供了
概率先验鲁棒的人脸姿态跟踪。
3.2.1
身份和表达先验
假设恒等权重w
id
和表达式权重w
exp
遵循两个独立的高
斯分布
是合理的,
w
id
=
μ
id
+
μ
i d
,
μ
id
=
N
(
μ
i d
|
0
,
i d
)
和
w
exp
=
µ
exp
+
ex p
,
e
xp
N
(
ex p
|
0
,
xe
× p
)
。 这些先验
分布可以从训练数据中估计。特别是
我们知道µ
id
=
1
U
>
1和µ
exp
=
1
U
>
1。的
我们还感兴趣的身份适应是不变的表达变化。人脸
模型和身份参数的联合分布为
p
(
f
,
w
i d
)
=
p
M
(
f
|
w
i d
)
p
(
w
i d
)
=
N
(
f
|
f
+
P
i d
w
i d
,
E
)
N
(
w
i d
|
i d
,
(四)
其中表达式的方差在似然
p
(f)中捕获
|
w
id
)。因
此,它对表情导致的局部形状变化具有鲁棒性,并且
w
id
的后验将受用户当前表情的影响较小另一方面,
一旦身份适应于当前用户,它将有助于调整表情方
差,从而增加姿态估计的鲁棒性。
如图如图2所示,与头部的其他部分相比,整体形状
变化(表示为每像素标准偏差)在面部区域中是最显著
的。我们进一步观察到,这种形状变化-
同一性的差异决定了这一过程,正如编码
为
P
i id
P
>
的
那样
。然而,正如预期的那样,
由表达式“
EEE
”引起
的形
状不确定性通常局限于
嘴部和下巴周围以及脸颊周围
区域
眉毛。更重要的是,在方程中的残差项(2)比那些低
得多的数量级
N
id
id
N
exp
exp
仅仅是因为身份和表达。
方差矩阵被设置为具有尺度的单位矩阵
即
,
id
=
σ
2
I
,
其中
σ
2
=
1
和
4.
概率面部姿态跟踪
id
exp.
id
N
id
2
exp
=
1
是从训练集中经验学习的。
exp
在这一节中,我们提出了我们的概率面部姿势,
请注意,µ
id
(或µ
exp
)不应为0,因为它可能会让
人脸模型f对w
exp
(或w
id
)不敏感[5]。
4.1.1
多线性人脸模型先验
关于w
id
和w
exp
的正则人脸模型
M
可以写成
f
=
<$
f
+
C
2
µ
id
3
µ
exp
+
C
2
µ
id
3
µ
exp
(
二
)
+
C
2
µ
id
3
exp
+
C
2
µ
id3exp
。
(2)中的最后一项在形状变化上通常可以忽略不计,
如图所示。二、因此,
M
近似遵循高斯分布,
p
M
(
f
)
=
N
(
f
|
µ
M
,
μ
M
)
,
(
3)
其中,其中性面为
µ
M
=
<$
f
+
C
2
µ
id
3
µ
exp
,
其变异矩阵由
下
式给出
:
跟踪.图3示出了总体架构,其包括两个主要组件:1)
鲁棒的面部姿态跟踪,以及2)在线身份自适应。第一
个组件是在给定输入深度图像和概率面部模型
PM
(f)
的情况下估计刚性面部姿态Pmax。姿态
参数θ不仅包括旋转角
r
,
平移向量
t,
而且尺度
s
,因为面部模型可能由于尺度差
异而不匹配输入点云。第二部分的目的是更新
在给定先前面部模型、当前姿态参数和输入深度图像的
情况下,识别参数w_
id
和可能面部模型p
_M
(f)
4.2.
鲁棒的面部姿态跟踪
在跟踪之前或跟踪失败之后,我们需要检测人脸在
第一帧中的位置。我们采用的头部检测方法Meyer
等
人
。[26],并裁剪输入深度图以获得以检测到
P
exp
Σ
exp
P
>
.投影矩阵
P
id
和
P
ID
经验
值
头部中心在半径
r
= 100
像素内。 指
从该深度片提取的点云作为P。
恒等式和表达式定义为:P
id
=
C
3
µ
exp
2
R
3
N
M
N
id
,
P
exp
=
C
2
µ
id
2
R
3
N
M
N
e xp
.
μ
M
为
几乎与平均face<
$
f
相同,因为
k
µ
M
−
<
$
f
k
2
=
姿态参数
θ
=
{r,t,
θ}
指示旋转角度、平移向量
和尺度
s
的对数,
1
kC
ID
exp
(U
>
1)
(U
>
1
)
k2
0
. 则意味着
即
,s
=
e>
0
,8 × 2R. 一个正则面模型点f
n
被刚性地扭曲成q
n
,n 2 {
1
,.
..
,
N
M
}
as
W-ID
和
W-exp
的先验不向人脸模型添加偏差
M
表示训练数据集的表示
(b)变异
mm
(c)(d)残差
σ
2
剩余13页未读,继续阅读
相关推荐


cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- C#实现程序A的监控启动机制
- Delphi与C#交互加密解密技术实现与源码分析
- 高效财务发票管理软件
- VC6.0编程实现删除磁盘空白文件夹工具
- w5x00-master.zip压缩包解析:W5200/W5500系列Linux驱动程序
- 数字通信经典教材第五版及其答案分享
- Extjs多表头设计与实现技巧
- VBA压缩包子技术未来展望
- 精选多类型导航菜单,总有您钟爱的一款
- 局域网聊天新途径:Android平台UDP技术实现
- 深入浅出神经网络模式识别与实践教程
- Junit测试实例分享:纯Java与SSH框架案例
- jquery xslider插件实现图片的流畅自动及按钮控制滚动
- MVC架构下的图书馆管理系统开发指南
- 里昂理工学院RecruteSup项目:第5年实践与Java技术整合
- iOS 13.2真机调试包使用指南及安装
