Trans4Map:视觉变换器在自我中心到他中心语义映射中的应用
98 浏览量
更新于2025-01-16
收藏 1.75MB PDF 举报
"本文介绍了一种名为Trans4Map的新型视觉变换器,旨在解决移动代理从自我中心图像到他中心语义映射的挑战。Trans4Map是一个端到端的一阶段映射框架,利用Transformer有效地处理长距离依赖性,同时通过双向他中心记忆(BAM)模块实现更高效的空间感知能力。在Matterport3D数据集上的实验显示,Trans4Map在减少参数数量的同时,提高了语义分割的准确性。"
在当前的AI领域,尤其是涉及移动机器人和自动驾驶的技术中,构建和理解全景地图是核心任务之一。传统的卷积神经网络(CNN)由于局部感受野的限制,往往难以捕捉到全局的环境信息,这对于从自我中心视角(即机器人自身的视角)到他中心视角(全局或固定参考系)的转换是个难题。Trans4Map的出现,就是为了克服这个问题。
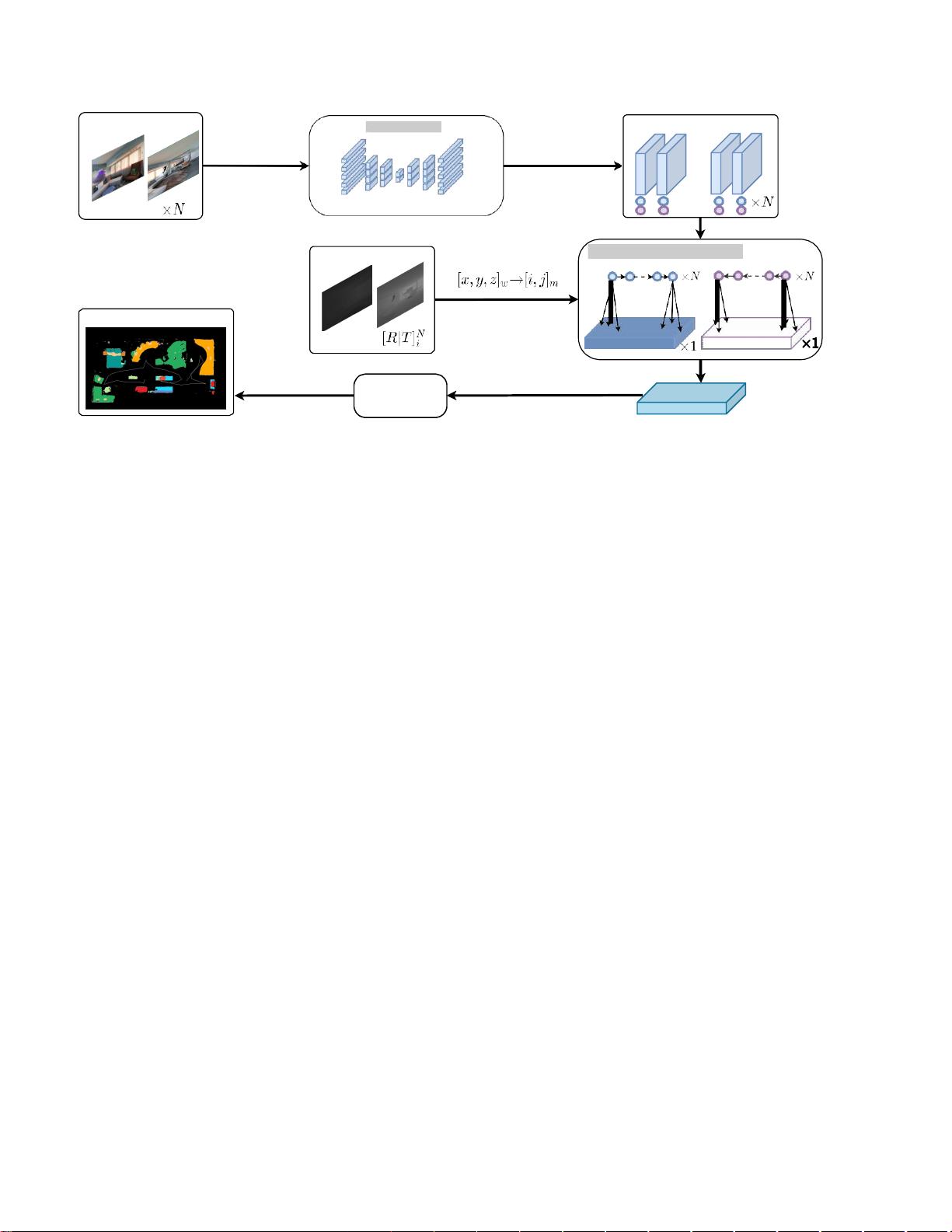
Trans4Map的核心是使用Transformer架构,Transformer以其强大的序列建模能力而闻名,可以处理序列中的长距离依赖关系。在这个框架中,Transformer被用来从一系列自我中心的图像中提取上下文特征,这有助于构建全面的环境理解。接着,引入的双向他中心记忆(BAM)模块进一步将这些特征投射到他中心视角,形成一个累积的记忆表示,这有助于构建非自我中心的语义地图。
BAM模块的关键在于其“双向”特性,它能够双向更新和融合信息,从而在记忆中既考虑到过去的观察也考虑到来自新观测的更新,这对于实时的在线映射过程尤为重要。最后,映射解码器会解析这个累积的存储器,生成自顶向下的语义分割映射,即全景语义地图。
实验结果显示,Trans4Map在Matterport3D数据集上取得了最先进的性能,相比于其他方法,它在减少67.2%参数量的同时,提高了3.25%的平均交并比(mIoU)和4.09%的精度,证明了其在效率和性能上的优势。
Trans4Map的工作为移动代理提供了一种新的、高效的方法来构建和理解周围环境,这对于自主导航、室内探索以及各种自动化任务来说都是至关重要的。这一进展为未来的研究开辟了道路,可能会进一步推动AI在空间感知和映射方面的进步。
4015
自我中心意象
Transformer
特征
...
...
在线投影
自我中心深度
双向分配中心存储器(BAM)前向后向
他中心语义学
...
融合
解码器
图4:端到端Trans4Map框架的概述。存在用于从RGB图像提取自我中心特征的基于变换器的编码器、用于经由
已知深度和姿态信息将所提取的特征序列投影和累积到非中心特征图的双向非中心存储器(BAM)、以及用于解
析累积的特征并预测非中心语义的基于CNN的解码器。
2.
相关工作
语义映射。最近,围绕语义映射出现了许多方法。语
义SLAM管道[13,32]将图像转发到分割网络中,然后
将预测的标签投影到俯视图上。这些努力遵循先分段
后项目的管道,这对深度信息尤其严格,
即:
RGB图
像中每个像素的全局坐标。不幸的是,轻微的错误可
能导致投影偏移,以及模型训练的拟合不足。投影然
后分 割流水 线 [36]在 投影 阶段 丢失了 大量 的视 觉信
息,这阻碍了小对象分割。相比之下,SMNet [3]执行
离线投影然后分段流水线,它在两个阶段分别训练编
码器和解码器,并且没有优化从第一视图输入到顶视
图语义的整个训练过程。
Lu
等人。
[26]提出了一种端到端网络,利用变分编
码器-解码器网络[19]对驾驶场景的前视图信息进行编
码,然后将其解码为2D自顶向下视图。Pan
等人。
[29]
用视图解析网络(VPN)表示了一个跨视图网络-一个
跨不同视图解析语义的MLP。这两种方法预测一个本
地语义自上而下的地图与一个端到端的网络从自我中
心的观察。这些方法不编码深度信息,因此语义图上
的对象不反映其几何结构。此外,有许多鸟瞰
外地BEVFormer [20]聚合来自环绕视角相机的时空线
索,而ViT-BEVSeg [9]使用空间Transformer解码器来
生成语义占用网格图。与这些工作不同,我们重新审
视了包括基于CNN或Transformer的各种骨干,并提出
了基于transformer的端到端框架,其充当用于整体
室
内
场景理解的单阶段BEV语义映射器。此外,还成功
地获得了生成的语义图中物体的对齐和几何结构
空间记忆。从以自我为中心的观察增量地生成俯视图
需要动态地更新以非自我为中心的存储器,
即
,随着
时间的推移聚集信息,例如移动代理在室内场景中移
动 。 用 于 此 任 务 的 Visual SLAM 管 道 [1 , 27 ,
38MapNet [14]开发了RNN来更新内存,并通过密集匹
配注册新的观察结果。 Tung
等人
[39]提出了几何感知
递归神经网络(GRNN)来分割3D中的对象。这项工
作是非常内存的要求,由于高维的功能。与我们的方
法最接近的工作是SMNet [3],它使用GRU来更新预测
的ten- sor。与以前的工作不同,我们提出了一个双向
的allo-中心的记忆,可以更好地积累信息随着时间的
推 移 和 分 割 被 遮 挡 的 对 象 。 这 一 关 键 设 计 允 许
Trans4Map执行隐式在线投影,启用一级映射管道,并
在大规模室内场景中设置新的最先进技术。
剩余11页未读,继续阅读
点击了解资源详情
1243 浏览量
552 浏览量
2024-06-04 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 小学水墨风学校网站模板设计
- 深入理解线程池的实现原理与应用
- MSP430编程代码集锦:实用例程源码分享
- 绿色大图幻灯商务响应式企业网站开发源码包
- 深入理解CSS与Web标准的专业解决方案
- Qt/C++集成Google拼音输入法演示Demo
- Apache Hive 0.13.1 版本安装包详解
- 百度地图范围标注技术及应用
- 打造个性化的Windows 8锁屏体验
- Atlantis移动应用开发深度解析
- ASP.NET实验教程:源代码详细解析与实践
- 2012年工业观察杂志完整版
- 全国综合缴费营业厅系统11.5:一站式缴费与运营管理解决方案
- JAVA原生实现HTTP请求的简易指南
- 便携PDF浏览器:随时随地快速查看文档
- VTF格式图片编辑工具:深入起源引擎贴图修改
