无ISP低功耗计算机视觉:训练数据集与去马赛克模拟
32 浏览量
更新于2025-01-16
收藏 1.09MB PDF 举报
"无ISP低功耗计算机视觉的训练数据集及模拟去马赛克方法"
本文探讨的是在低功耗设备上实现无ISP(图像信号处理)的计算机视觉(CV)系统的挑战和解决方案。当前的CV系统依赖于ISP单元将图像传感器捕获的原始图像转换为RGB图像,以便进行模型训练和执行视觉任务。然而,这种方法在资源受限的设备上效率低下,因此研究者开始探索传感器内和像素内计算,以减少ISP的需求。
文章指出,直接在未经ISP处理的原始图像上训练深度CV模型非常困难,因为现有的大型开源数据集几乎都是基于RGB图像。为解决这一问题,作者提出反向ISP管道的方法,该方法可以将任何RGB数据集转换为原始图像格式,使得模型能够在原始图像上进行训练。他们利用此方法创建了COCO数据集的原始版本,结果显示,与使用传统ISP处理的RGB数据集训练相比,这种方法在视觉唤醒工作(VWW)数据集上的测试准确性提高了1%。
为了进一步提升无ISP CV模型的性能,作者提出了一种能量有效的模拟像素内去马赛克技术,这可以与像素内CNN计算相结合。在PASCALRAW数据集上,该方法实现了8.1%的准确率提升。此外,他们展示了在新的应用程序中,通过少镜头学习,仅用30张图像就能在3类上获得20.5%的mAP(平均精度)增长。
这项工作的贡献在于提供了一个新的训练策略,即在原始图像上训练模型,以及一个能与像素内计算协同工作的去马赛克算法,这两者都旨在优化低功耗设备上的无ISP CV系统。通过这种方式,可以在保持或提高性能的同时,减少能源消耗和带宽需求。相关的代码可以在提供的链接中获取:https://github.com/godatta/ISP-less-CV。
这项研究为低功耗设备上的高效计算机视觉处理开辟了新途径,有助于推动未来物联网设备、嵌入式系统以及边缘计算的发展。
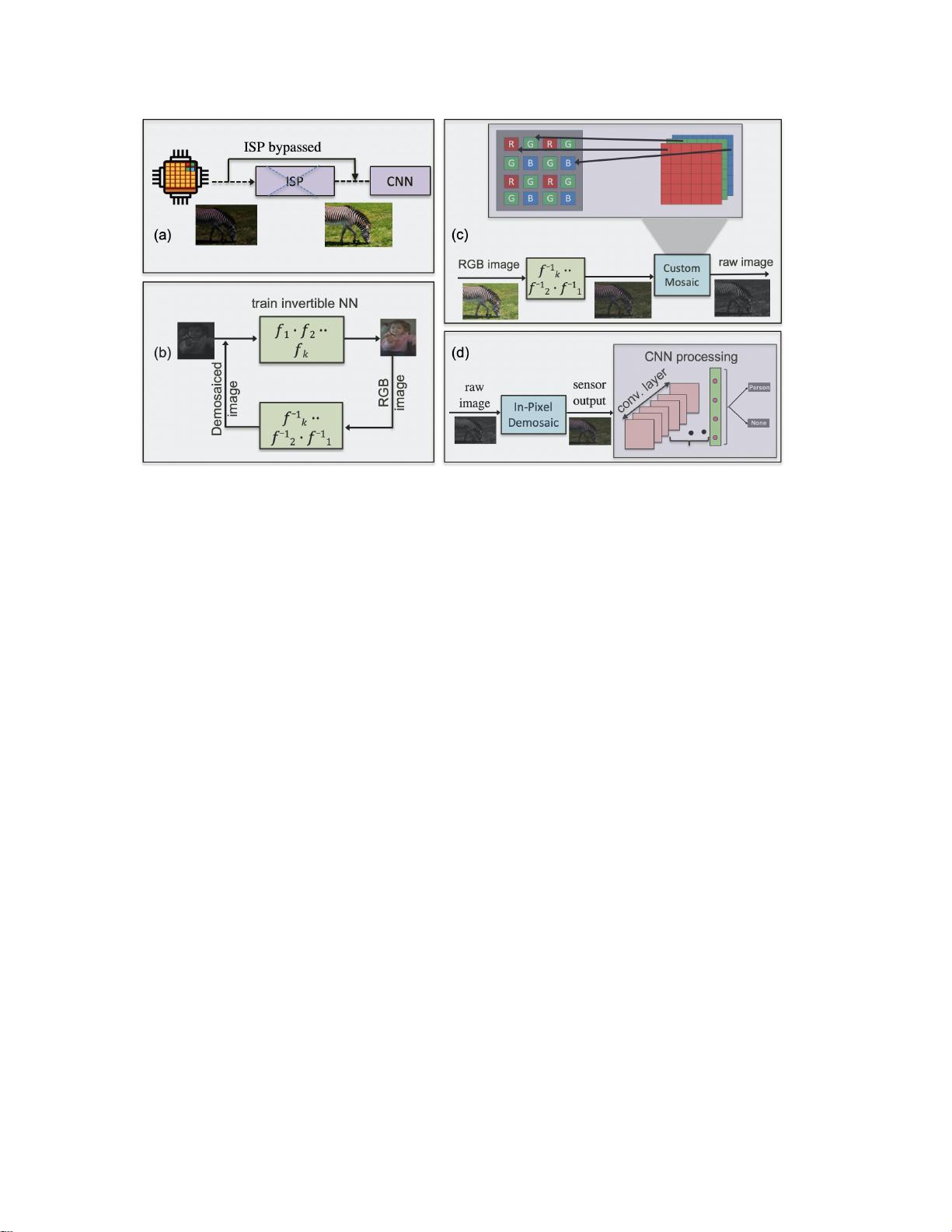
2432
图2.(a)提出的无ISP CV系统,(b)在去马赛克的原始图像上进行可逆NN训练,而不进行任何白平衡或伽马校正,(c)使
用训练的逆网络和自定义马赛克生成原始图像,以及(d)应用像素内去马赛克和无ISP CV模型的训练。注意,像素阵列中
的
像素内演示
实现如图所示。3.第三章。
网络模型,以将用于原始图像的现成预训练模型的
logit预测与用于ISP处理的RGB图像的logit预测对齐。
2.2.
少镜头目标检测
近年来,随着ML在低数据场景中的准确性不断提
高,少镜头对象检测(FSOD)获得了显著的吸引力。
FSOD中有两种主流的训练范式,元学习和基于微调的
方法。元学习方法试图从多个注释的数据丰富的支持
数据集中捕获聚合的信息。因此,当需要在具有新类
和更少数据的数据集上训练时,模型可以利用从支持
数据集学习的先验知识来推广到新类。例如,[22]使
用重新加权模块通过捕获支持图像的全局特征来调整
查询图像Meta特征的系数,以适合于新对象检测。作
者在[45]中提出了一个预测器头重构网络(PRN)模
块,用于生成类关注向量,以提供元学习者预测器头
的支持和查询图像之间的聚合特征此外,[17]引入了
一个基于注意力的区域建议网络,以将候选建议与支
持图像和多关系检测器进行匹配,该检测器可以测量
来自查询和支持对象的建议框与需要复杂训练过程的
元学习相比,基于微调的方法具有更简单的管道。例
如,[41]提出了基于两阶段微调的方法(TFA),该方
法仅微调
边界框分类和回归部分基于类平衡的训练集,但优于
许多Meta学习方法。此外,为了减少将新实例错误分
类为令人困惑的基类,[39]将对比学习引入FSOD管
道,这有助于学习的目标特征表现出高的类内相似性
和类间变异性。
3.
反转ISP管道
与[44]类似,我们建议使用第2.1节中描述的仿射耦
合层从ISP处理的RGB图像生成原始演示图像。然而,
在这方面,
[44]在去马赛克、白平衡和伽马校正的原始图像上对
ISP流水线进行建模,因此,可逆ISP流水线不生成直
接由相机捕获的原始图像。作者对原始数据进行伽马
校正(即,而不存储在磁盘上)以压缩动态范围以获
得更快的收敛。 因此 ,对于 无ISP的 传感器内CV 系
统,[44]中提出的可逆ISP流水线的朴素应用将需要在
传感器中执行这些操作。由于像素阵列和外围中可用
的有限计算/存储器占用空间,这是具有挑战性的。特
别地,传统的去马赛克涉及矩阵运算,其涉及插值
(最近邻、双线性、双三次等)。与输入分辨率成比
例的技术。此外,白平衡涉及每个像素位置的可变增
益放大,这需要复杂的控制逻辑,伽马校正涉及对数
计算,这对于在高级高密度像素中使用模拟逻辑进行
处理是具有挑战性的
剩余10页未读,继续阅读
697 浏览量
2011-11-30 上传
207 浏览量
407 浏览量
520 浏览量
229 浏览量
点击了解资源详情
点击了解资源详情

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Ruby语言集成Mandrill API的gem开发
- 开源嵌入式qt软键盘SYSZUXpinyin可移植源代码
- Kinect2.0实现高清面部特征精确对齐技术
- React与GitHub Jobs API整合的就业搜索应用
- MATLAB傅里叶变换函数应用实例分析
- 探索鼠标悬停特效的实现与应用
- 工行捷德U盾64位驱动程序安装指南
- Apache与Tomcat整合集群配置教程
- 成为JavaScript英雄:掌握be-the-hero-master技巧
- 深入实践Java编程珠玑:第13章源代码解析
- Proficy Maintenance Gateway软件:实时维护策略助力业务变革
- HTML5图片上传与编辑控件的实现
- RTDS环境下电网STATCOM模型的应用与分析
- 掌握Matlab下偏微分方程的有限元方法解析
- Aop原理与示例程序解读
- projete大语言项目登陆页面设计与实现
