批量最优传输损失提升3D形状识别与深度度量学习性能
38 浏览量
更新于2025-01-16
收藏 1.51MB PDF 举报
本文主要探讨了基于批量最优传输损失的3D形状识别与深度度量学习相结合的方法。传统的深度度量学习,如常用的两两(或三重)损失目标,存在一些局限性,如无法充分挖掘训练样本的语义信息,对困难样本的关注不足,这导致了学习过程中的收敛速度慢和性能不佳。为了克服这些问题,研究者提出了新的批量最优传输损失。
批量最优传输损失的核心思想是通过优化过程中的批量样本,学习到一个能够自动强调困难样本、驱动收敛的重要性驱动的距离度量。这种方法不再局限于单对或少数样本之间的比较,而是利用整个训练批次的信息,使得相似的正样本被紧密聚类,不相似的负样本被有效分离。这通过批量运输规划得以实现,使得模型能更有效地处理具有大差异的正样本和小差异的负样本,从而提升学习效率。
作者将这个新损失与深度度量学习结合,构建了一个端到端的深度学习框架,用于学习深度特征表示和嵌入度量。实验结果显示,这种方法在MNIST、CIFAR10、SHREC13、SHREC14、ModelNet10和ModelNet40等多个3D形状识别任务上表现优秀,不仅能显著加速模型收敛,还能达到当前最先进的识别性能。
例如,在3D形状识别的具体实验中,研究者发现他们的方法在较短的学习周期内就能取得优于传统方法的识别效果。这不仅证明了批量最优传输损失的有效性,也表明其在实际应用中具有更高的效率和准确性。此外,论文还提到了批量最优传输损失在其他领域的应用潜力,如人脸识别和基于草图的识别,显示出其广泛适用性。
这篇论文为深度度量学习领域提供了一个有力的工具,通过改进损失函数设计,促进了3D形状识别等任务的性能提升,为未来的研究者和开发者提供了新的思路和技术支持。
3335
OPT
I
J
I
J
2
2
2
+
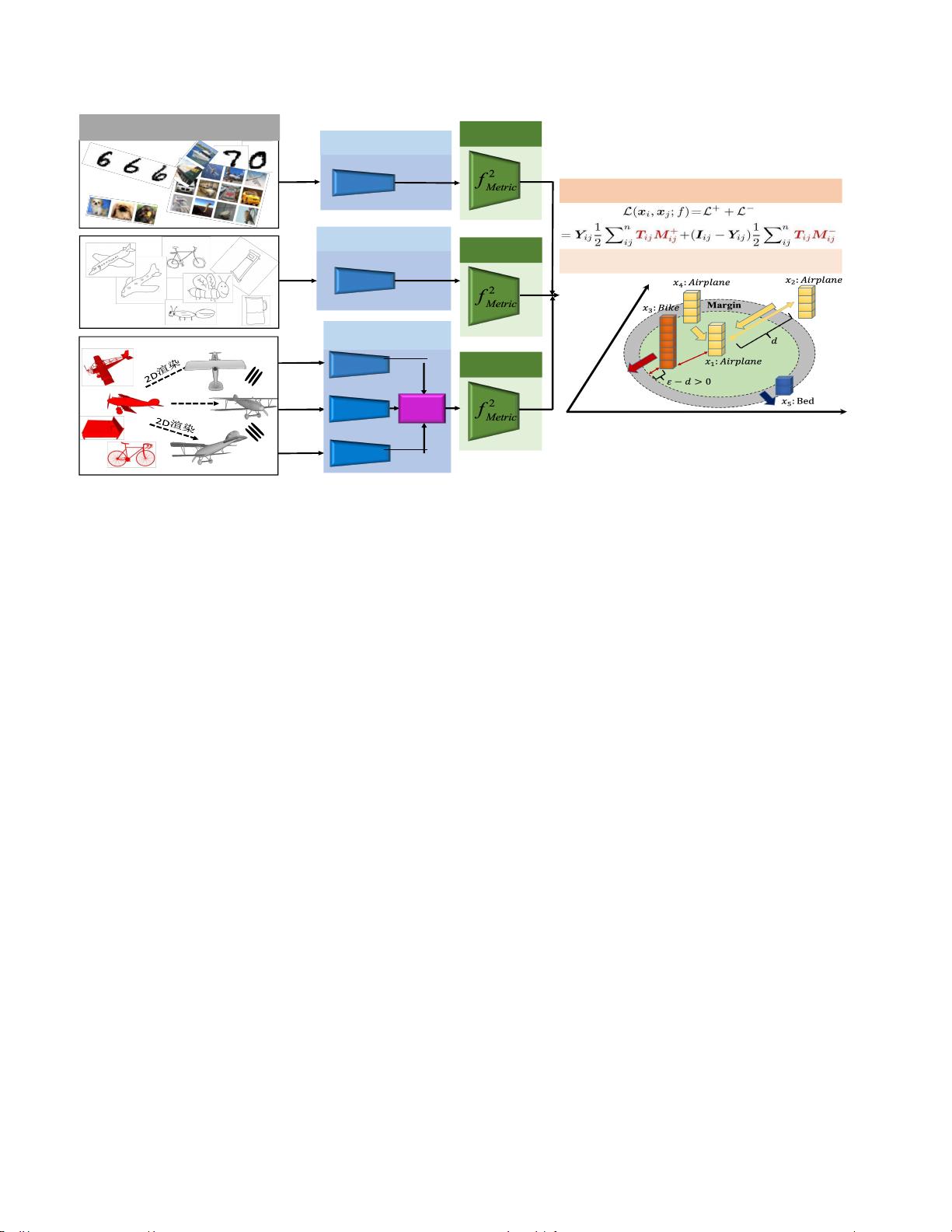
图2.我们将建议的损失公式化到深度度量学习框架中。给定每个模态样本的批次,我们使用LeNet-5
[32]
,
ResNet-50[25]
和
MVCNN[52]
作为
f
1
分别为2D图像、2D草图和3D形状提取深度CNN特征
2
CNN
度量网络f
Metric
由四个全连接(FC)层组成,即,4096-2048-512-128(LeNet-5的两个FC层512-256)
用于执行
CNN
特征的降维。我们在这些
FC
层之间添加三个
sigmoid
函数作为激活,以生成归一化和密集的特征向量。整个框架
可以通过新的批量方式
−
最佳运输损耗突出显示的重要性驱动距离度量T
ij
M
+
和T
ij
M
用于强调硬阳性
和阴性样品。它联合学习语义嵌入度量和深度特征表示,用于检索和分类。
学习深度距离度量
M
ij
为
L(
x
,
x
;f)=
y M
+(1−
y
)max{0
,
ε
−
M
概率分布r和c之间的计划定义为:
U(
r
,
c
):
={
T
∈ Rn
×
n
|
T
1
=
r
,
T
T
1
=
c
}
,
其中1
是
}
,
(
1
)
i j ij ij ij ij ij
ij
全
1
向量。运输计划的集合
U
(
r
,
c
)
con.
其中标签
y
ij
∈ {0
,
1}
指示一对(
x
i
,
x
j
)是否
来
自同一类。 边缘
参数
ε
规定了不同样本之间距离的阈
值。度量
M
ij
可以是特征嵌入空间中的任意距离度量
通常,
欧几里得度量
M
ij
=
||
(f(
x
i
)
−
f
(
x
j
))
||
2
用于
包含所有非负
的
n
×
n
元素,行和列
分别求和r和c
给定一个n
×
n的地面距离矩阵M,利用一个传输矩
阵T将r映射到c的代价可以量化为
:
. 代表弗罗贝纽斯
点积。那么方程(3)中定义的问题
表示一对样本之间的距离。三重损失[60,10]与对比损
失有相似的想法,但除了
D
M
(
r
,
c
):=
min
T
∈
U
(
r
,
c
)
(
3
)旅游
景点
将一对样本趋向于三个样本。对于给定的查询
x
i
、
与查询相似的样本
x
j
和不相似的样本
x
k
,三元组损
失可以公式化为:
L(x
i
,
x
j
,
x
k
; f)= max{0
,
M
ij
− M
ik
+ ε}
。
(
二)
直觉上,它鼓励不同对之间的距离
M
ik
=
||(f
(
x
i
)−
f
(
x
k
))||
2
大于相似对之间的距离
M
ij
=
||(f
(
x
i
)− f
(
x
j
))||
2
至少有一个边缘ε。
最佳运输距离:最优运输距离[16],也称为Wasserstein
距离[56]或地球移动器距离[43],根据最优运输理论[57,
61]的原理定义两个概率分布之间的距离。形式上,设
r
和
c
是n维概率测度.交通工具的设置
称为给定地面费用
M
的
r
和
c
之间的最优运输问题。
最佳运输距离
DM
(
r
,
c
)测量在概率测度
r
中运输质
量以匹配在
c
中的质量的最便宜的方式。
与一些常用的箱到箱度量相比,最佳传输距离定义
了更强大的跨箱度量来测量概率,例如,Euclidean、
Hellinger和Kullback-Leibler分歧。然而,当在一般度
量空间中比较两
个
n维概率分布时,计算D
M
的成本至
少为O(n
3
log(n))为了缓解这个问题,Cuturi [16]
通过在方程(3)中添加熵正则化器来制定正则化的运
输问题。这使得目标函数严格凸,并允许它被有效地
解决。特别地,给定传输矩阵T,令
CNN 2D
图像网络
二维图像的度
量
f
1
CNN
CNN 2D
草图网络
f
1
CNN
CNN 3D
电视网
f
1
CNN
f
1
CNN
查看
池化
深度度量空间
Deep Metric
Space
f
1
CNN
三维空间的度
量
二维草图的度
量
批样品
基于重要性驱动的距离度量学习挖掘硬正负样
本
用于学习的
2D
渲染
…
…
…
…
…
…
剩余10页未读,继续阅读
点击了解资源详情
129 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 初学者入门必备!Visual C++开发的连连看小程序
- C#实现SqlServer分页存储过程示例分析
- 西门子工业网络通信例程解读与实践
- JavaScript实现表格变色与选中效果指南
- MVP与Retrofit2.0相结合的登录示例教程
- MFC实现透明泡泡效果与文件操作教程
- 探索Delphi ERP框架的核心功能与应用案例
- 爱尔兰COVID-19案例数据分析与可视化
- 提升效率的三维石头制作插件
- 人脸C++识别系统实现:源码与测试包
- MishMash Hackathon:Python编程马拉松盛事
- JavaScript Switch语句练习指南:简洁注释详解
- C语言实现的通讯录管理系统设计教程
- ASP.net实现用户登录注册功能模块详解
- 吉时利2000数据读取与分析教程
- 钻石画软件:从设计到生产的高效解决方案
