SIXray:大规模安检X射线图像违禁品检测基准与挑战
31 浏览量
更新于2025-01-16
收藏 1.41MB PDF 举报
"SIXray是一个大规模的安检X射线图像数据集,专注于违禁品检测,由1,059,231张图像组成,涵盖了6大类8,929个违禁物品的手动标注。这个数据集特别强调了重叠图像的挑战,同时具备复杂背景和类别不平衡的问题。"
在当前的研究中,SIXray数据集的提出旨在推动安检X射线图像分析技术的发展。由于公共场所的安全需求日益增加,快速、精准地识别X射线图像中的违禁品变得至关重要。传统的机器学习方法,如支持向量机(SVM),在处理此类任务时可能遇到局限,尤其是在复杂的背景和重叠物体的情况下。
深度学习,尤其是卷积神经网络(CNN),为解决这一问题提供了新的可能。然而,CNN在处理SIXray这类数据时,需要应对两个主要挑战:一是图像中的对象可能存在大量重叠,二是类别之间的不平衡。为了解决这些问题,研究者提出了一种类平衡的高精度反向连接精细化(Class-Balanced High-Precision Back-Connection Refinement, CBHPR)算法。
CBHPR算法假设每个输入图像都来自一个混合分布,深度网络需要通过迭代过程来准确解析图像内容。通过在不同的网络主干中插入反向连接,该方法能够提供高级视觉提示,帮助中间层功能更好地理解图像。此外,设计了一种类平衡损失函数,以减少易于引入噪声的负样本的影响。
通过对SIXray数据集进行不同阳性/阴性样本比例的评估,研究发现CBHPR算法在处理类别不平衡问题上表现出色,尤其在正样本较少的情况下,神经网络相比于SVM有显著优势。这表明神经网络在实际安全检测场景中有巨大的潜力。
1.1 引言部分还提到,随着城市人口增长和交通节点的密集,安全检查的需求持续增加。X射线图像分析技术的进步将有助于提升公共安全,自动化和精确化的违禁品检测对于防范恐怖主义等威胁至关重要。因此,SIXray数据集的发布和相关算法的开发,为科研人员提供了一个强大的工具,以进一步提升安检系统的效能。
2121
姐与我们的场景不同,这些图像中的对象很少相互重
叠。
•
X射线图像和基准
目标识别的研究领域已经成为计算机领域的主流。
由深度学习方法驱动。 随着大规模数据集[18]和强大的
计算资源的可用性,研究人员能够设计和优化非常深的
神经网络[18] [31] [16] [4] [13] [14],以分层的方式学习
视觉模式。在每个图像可以包含多于一个对象的场景
中,通常存在两种类型的定位方法。第一个
SIX
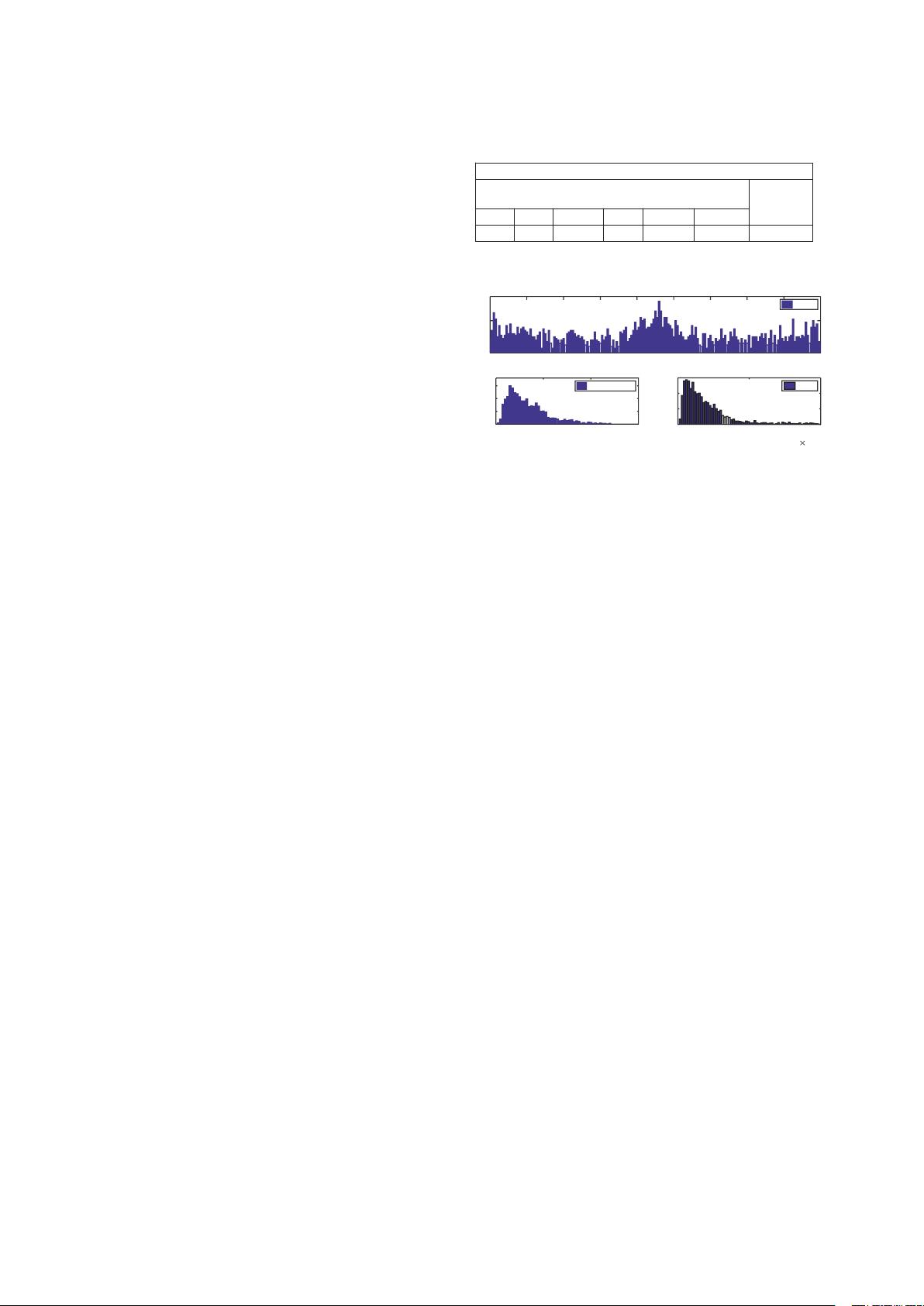
射线数据集(1,059,231)
阳性(8,
929)
负
枪
刀
扳手
钳子
剪刀
锤
3,131
1,943
2,199
3,961
983
60
1,050,302
表
1. SIXray
数据集的类分布。还有一个
锤子
类,有60个项
目,但由于样品数量少而没有使用。
20
0
0 20 40 60 80 100 120 140 160 180
角度
一种是在图像级别上工作,该级别为每个类别产生一个
分数,指示其存在或不存在[39]。第二个则在对象级别
上工作,并为每个对象生成一个边界框和一个类标签,
150
100
50
0
0
2 4 6
纵横比
150
100
50
0
0
5
区域
10
10
4
[12] [11] [29] [28][29] 前一种- ten遇到了多对象分类和
训 练 数 据 不 平 衡 的 问 题 [36], 对 此 , 二 进制 交 叉 熵
(BCE)损失[5]以及类平衡技术[36]
[15]已被发现。另一方面,第二种类型通常基于管道,
首先提取图像中的一些建议[12] [11] [29],然后确定每
个建议的类别。
本文研究图像级识别,因为训练数据中缺少每个对
象的注释,而我们的方法具有对象级定位的能力。 这
与弱监督对象定位的研究有关[3] [6] [33],或者使用
自上而下的类激活[8] [7] [40]。也有关于在多实例学
习框架中制定对象定位的努力,其中卷积滤波器充当激
活特征图上感兴趣区域的检测器[3] [37] [33][35]。
在X射线图像中的物体识别的背景下,研究人员意识
到这些图像通常包含较少的纹理信息,但形状信息更具
区分力。因此,在视觉词袋模型的时代[34] [2],设计有
效和高效的手工功能的主题被深入探讨[30] [26]。随着
深度学习成为优化复杂函数的标准工具,研究人员开始
将其应用于为X射线图像表示提取紧凑的视觉特征[1],
或者对X射线图像上的预训练模型进行微调,以便可以
借用从自然图像中学到的知识。本文主要研究第二种方
法。
3.
SIXray基准
3.1.
数据采集
我 们 收 集 了 一 个 名 为 Security Inspection X-ray
(SIXray)的数据集,它总共包含1
,
059
,
231张X射线
图像,比现有的唯一一个公共数据集大100多倍
图
3.SIX
射线测试集中物体视角、长宽比和面积的分布
用于相同目的的lic数据集,
即
,GDXray数据集的
行李
组[25]。这些图像是从几个地铁站收集的,原始元数据
表明是否存在违禁物品。常见的违禁物品有
枪
、
刀
、
扳
手
、
钳子
、
剪刀
和
锤子
六类。在我们的实验中没有使用
仅具有60个样本的
锤
类。这些对象的分布与真实世界的
场景一致,其中与阴性样本相比,阳性样本要少得多。
此数据集的统计数据显示在选项卡中。1.一、每个图像
都由安全检查机器扫描,该机器为不同材料制成的物体
分配不同的颜色。所有图像均已存储
JPEG格式,平均大小为100K像素。
为了研究训练数据不平衡带来的影响,我们构建了该
数据集的三个子集,分别命名为SIXray10,SIXray100
和SIXray1000,数字表示阴性样本与阳性样本的比例。
在SIXray 10和SIXray 100中,所有8,929
正图像包括在内,正好有10×,
100×负图像。SIXray100的分布与真实世界场景非常接
近。最大限度地探索
我 们 的 算 法 处 理 数 据 不 平 衡 的 能 力 , 我 们 构 建
SIXray1000数据集时,每类只随机选择1000张正像,但
将它们与所有1050302张负像混合。每个子集又分为训
练集和测试集,训练集包含80%的图像,测试集包含
20%的图像(训练图像与测试图像之比为4:1)。
在整个数据集上,我们使用人类安全检查员提供的图
像级注释,
即
是否存在每种类型的违禁物品。此外,在
测试
集上,我们手动为每个禁止项添加一个边界框,以
评估对象定位的性能。
角度
纵横比
#
实例
区域
#
实例
#
实例
剩余11页未读,继续阅读
978 浏览量
点击了解资源详情
2021-09-28 上传
820 浏览量
2021-09-19 上传
2024-05-03 上传
107 浏览量

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 初学者入门必备!Visual C++开发的连连看小程序
- C#实现SqlServer分页存储过程示例分析
- 西门子工业网络通信例程解读与实践
- JavaScript实现表格变色与选中效果指南
- MVP与Retrofit2.0相结合的登录示例教程
- MFC实现透明泡泡效果与文件操作教程
- 探索Delphi ERP框架的核心功能与应用案例
- 爱尔兰COVID-19案例数据分析与可视化
- 提升效率的三维石头制作插件
- 人脸C++识别系统实现:源码与测试包
- MishMash Hackathon:Python编程马拉松盛事
- JavaScript Switch语句练习指南:简洁注释详解
- C语言实现的通讯录管理系统设计教程
- ASP.net实现用户登录注册功能模块详解
- 吉时利2000数据读取与分析教程
- 钻石画软件:从设计到生产的高效解决方案
