简化关联,增强HOI检测的交互理解
PDF格式 | 13.02MB |
更新于2025-01-16
| 167 浏览量 | 举报
--.
"#$_$&'
--.
&$(_$&'
--.
&$(_)*"
--.
+,-./_)*"
20123
0
GEN-VLKT:简化关联,增强HOI检测的交互理解
0
YueLiao1,3*AixiZhang2*MiaoLu2YongliangWang2XiaoboLi2SiLiu1,3†
0
1.北京航空航天大学人工智能研究所2.阿里巴巴集团3.
北京航空航天大学杭州创新研究院
0
摘要
0
人体-物体交互(HOI)检测的任务可以分为两个核心问题,
即人体-物体关联和交互理解。在本文中,我们揭示并解决
了传统基于查询的HOI检测器在这两个方面的缺点。对于关
联,之前的两分支方法在后处理匹配上存在复杂和昂贵的问
题,而单分支方法忽略了不同任务中的特征区别。我们提出
了引导嵌入网络(GEN)来实现一个无需后处理匹配的两分
支流程。在GEN中,我们设计了一个实例解码器,使用两个
独立的查询集来检测人体和物体,并使用位置引导嵌入(p-
GE)将处于相同位置的人体和物体标记为一对。此外,我们
设计了一个交互解码器来分类交互,其中交互查询由每个实
例解码器层的生成的实例引导嵌入(i-GE)组成。对于交互
理解,之前的方法存在长尾分布和零样本发现的问题。本文
提出了视觉-语言知识传递(VLKT)训练策略,通过从视觉-
语言预训练模型CLIP中传递知识来增强交互理解。具体而言
,我们使用CLIP为所有标签提取文本嵌入来初始化分类器,
并采用模仿损失来最小化GEN和CLIP之间的视觉特征距离。
结果,GEN-VLKT在多个数据集上大幅超越了现有技术,例
如在HICO-Det上的mAP提高了5.05个百分点。源代码可在
https://github.com/YueLiao/gen-vlkt获得。
0
1.引言
0
人体-物体交互(HOI)检测是使机器在静态图像中以细粒度
的方式理解人类活动的重要任务。在这个任务中,人类活动
被表示为一系列的HOI三元组<人体,
0
*同等贡献†
通讯作者(liusi@buaa.edu.cn)
0
交互
0
解码器
0
实例解
码器
0
p-GE
0
i-GE
0
人体查
询
0
对象查
询
0
CLIP图像
0
编码器
0
CLIP文本
编码器
0
图像
0
HOI文本
0
标签
0
模仿
0
对象文本
0
标签
0
初始化HOI文本
0
嵌入
0
对象文本嵌入
00
(a)GEN的两个分支解码器(b)VLKT
0
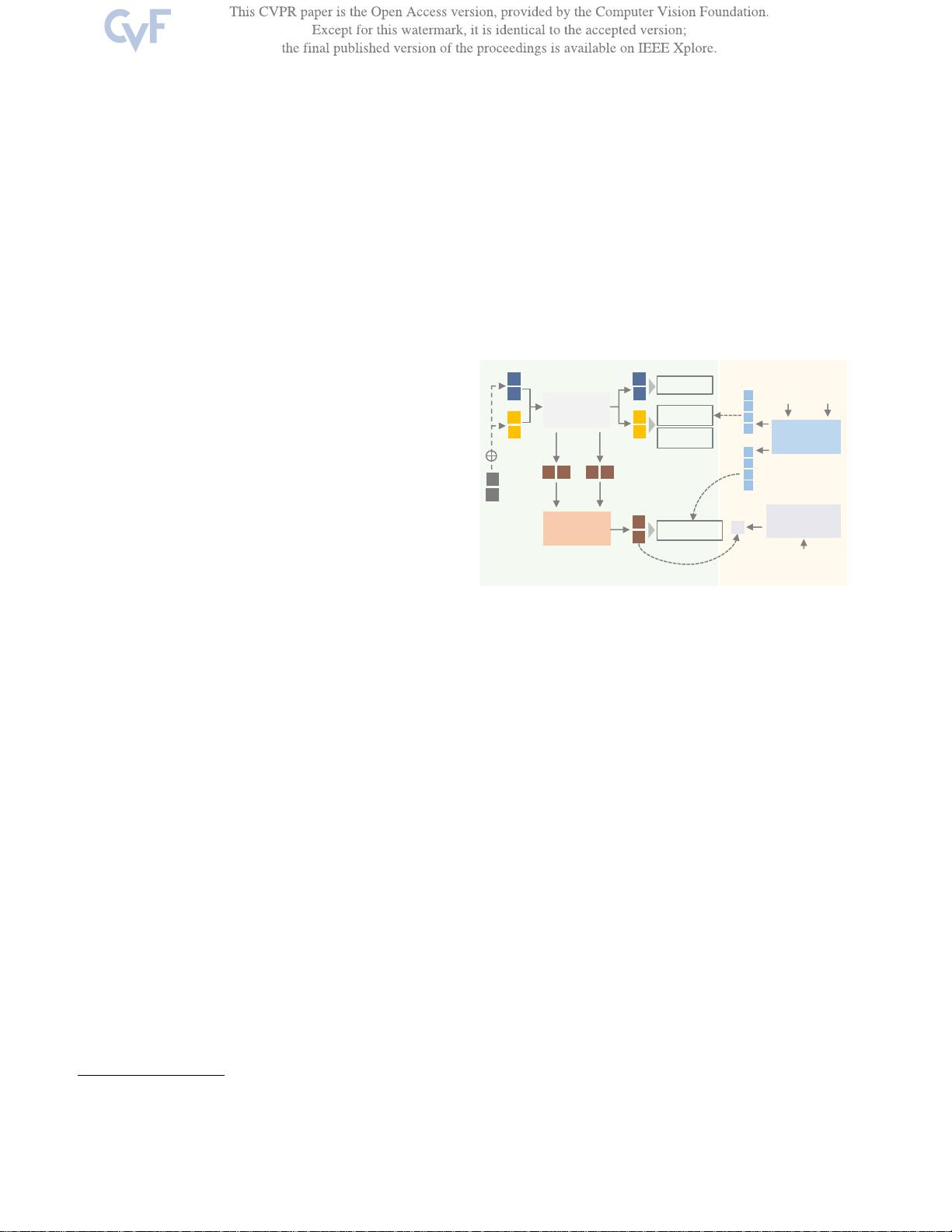
图1.
我们的GEN-VLKT流程。我们提出了GEN,一个基于查询的HOI检
测器,具有两个分支解码器,其中我们设计了一个引导嵌入关联机
制来替代传统的后处理匹配过程,以简化关联。此外,我们设计了
一种训练策略VLKT,通过从大规模视觉-语言预训练模型CLIP中传
递知识来增强交互理解。
0
对象,动词>,因此需要一个HOI检测器来定位人体和物体
对并识别它们的交互。HOI检测的核心问题是探索如何关联
交互的人体和物体对并理解它们的交互。因此,我们考虑从
两个方面改进HOI检测器,并设计了一个统一且优越的HOI
检测框架。我们首先回顾传统方法在这两个方面的努力。
0
对于关联问题,主要可以分为两种范式,即自底向上和自顶
向下。自底向上的方法[6,7,
21]首先检测人体和物体,然后通过分类器或图模型关联人
体和物体。自顶向下的方法通常设计一个锚点来表示交互,
例如交互点[23]和查询[4,31,
46],然后通过预定义的关联规则找到相应的人体和物体。
受益于视觉Transformer的发展,基于查询的方法正在引领
HOI检测的性能,主要有两个流派,即两个
下载后可阅读完整内容,剩余9页未读,立即下载
相关推荐




cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- A7Demo.appstudio:探索JavaScript应用开发
- 百度地图范围内的标注点技术实现
- Foobar2000绿色汉化版:全面提升音频播放体验
- Rhythm Core .NET库:字符串与集合扩展方法详解
- 深入了解Tomcat源码及其依赖包结构
- 物流节约里程法的文档整理与实践分享
- NUnit3.vsix:快速安装NUnit三件套到VS2017及以上版本
- JQuery核心函数使用速查手册详解
- 多种风格的Select下拉框美化插件及其js代码下载
- Mac用户必备:SmartSVN版本控制工具介绍
- ELTE IK Web编程与Web开发课程内容详解
- QuartusII环境下的Verilog锁相环实现
- 横版过关游戏完整VC源码及资源包
- MVC后台管理框架2021版:源码与代码生成器详解
- 宗成庆主讲的自然语言理解课程PPT解析
- Memcached与Tomcat会话共享与Kryo序列化配置指南
