附加注意组合学习(AACL):多模态图像检索与文本反馈的新方法
PDF格式 | 2.7MB |
更新于2025-01-16
| 197 浏览量 | 举报
"这篇论文主要关注的是多模态图像检索中的一个特定问题,即如何结合文本反馈进行有效的图像检索。作者提出了一种名为附加注意组合学习(AAACL)的新方法,该方法利用多模态变换器架构来处理图像-文本上下文,并特别设计了一个基于附加注意力的图像-文本合成模块,以改进深度神经网络的表现。这项工作建立在一个新的具有挑战性的基准之上,来源于Shopping100k数据集,并在FashionIQ,Fashion200k和Shopping100k这三大数据集上进行了广泛的评估,展示了AAACL在所有数据集上均取得最先进的结果。
1. 图像检索是计算机视觉领域的重要任务,通常包括使用关键字、查询图像或草图等多种方式来制定搜索查询。然而,传统图像检索难以准确理解用户的意图并据此进行精细化检索。因此,研究人员开始探索利用用户反馈来改善检索结果。
2. 文本图像检索与文本反馈的结合提供了一种自然且灵活的用户交互方式,允许用户通过自然语言描述来细化检索结果。论文中提出的任务是检索出与原始查询图像相似,但根据文本描述进行了特定修改的新图像(如图1所示)。
3. AACL方法的核心是其基于附加注意力的图像-文本合成模块,这个模块能够无缝集成到深度神经网络中,有效处理图像和文本的协同理解。这一创新解决了多模态学习中的挑战,尤其是在理解和融合视觉与语言信息时。
4. 研究中,作者创建了一个新的基准测试集,源自Shopping100k数据集,为这个领域的研究提供了更具挑战性的环境。通过对多个大规模数据集的实验,AACL证明了其优越性,不仅在FashionIQ、Fashion200k,还在自己创建的基准上超越了现有的最佳方法。
5. 这项工作的贡献在于提供了一个全新的解决方案,对于推动多模态图像检索技术的进步,特别是在实际应用如电子商务中的时尚图像检索,有着显著的意义。通过解决用户反馈的融合问题,AACL提升了用户体验,并为未来的研究打开了新的方向。"
1013
”
P
目标图像
query image
衣服比较少
没有侧面开叉,而且
裙子更宽
图像编码
器
图像编码
器
文本
编码器
池损失
加法注意力合成
模块
添加规范
前馈
添加规范
线性
加性自注意
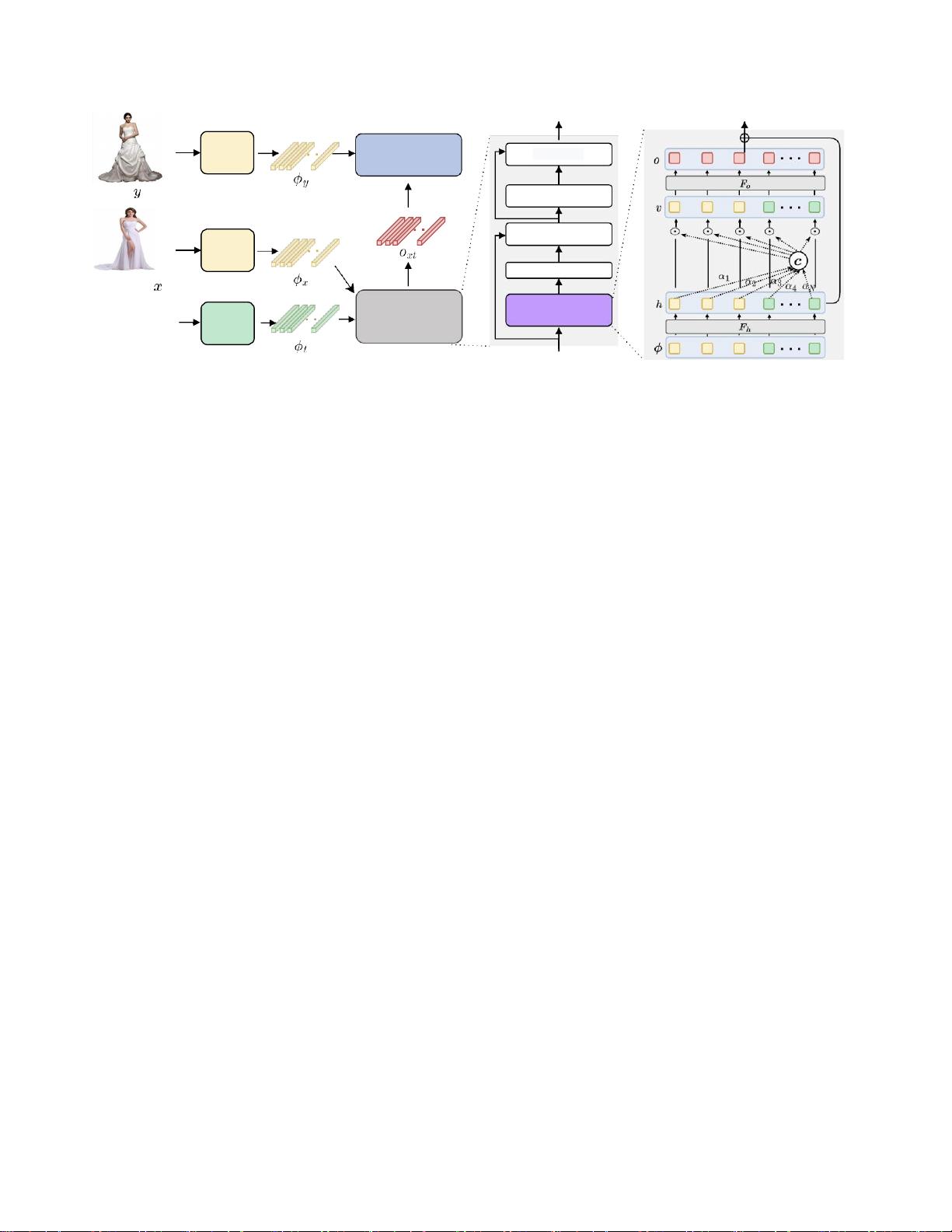
图2:我们的加法注意组合学习框架概述。给定一对查询图像和文本作为输入,我们的目标是学习与目标图像表示
对齐的复合表示。AACL包含三个主要组件:图像编码器(Sec. 3.1),文本编码器(第3.1节)。3.1),以及一个
附加注意力组成模块(第3.2节),可以插入不同的模型进行特征融合。“
然而,点积注意力有一个缺点,即它必须注意每个目
标令牌的源侧上的所有令牌,这是昂贵的,并且对于
较长的序列可能是不实际的。实验表明,在某些情况
下,加法注意比乘法注意实现更高的准确性受此启
发,我们提出了一个
附加的注意力合成模块
的特征融
合。
2.4.
视觉语言(VL)预培训
虽然带有文本反馈的图像检索与VL预训练有一些相
似之处[57,15,39,68,66,37],但我们工作的重
点是不同的。VL预训练的目标是学习跨模态表示,可
以通过微调来适应各种下游任务[39]。然而,我们的
工作集中在图像-文本合成模块本身,它执行单阶段后
期特征融合与图像和文本嵌入从单独的transformer编
码器。
3.
方法
图2展示了我们的附加注意组合学习(AACL)框架
的整体架构。给定源图像x和文本反馈t作为输 入查
询,AACL的目标是学习可用于从
图像和文本编码器的输出。
在下文中,我们首先在第3.1节中提供两个编码器的
概述然后,我们在第3.2节中详细介绍了我们的新组合
模块,并在第3.3节中详细介绍了我们的模型优化。
3.1.
图像和文本表示
图像表示:我们采用Swin变换器[44]来导出图像的视
觉内容的判别表示。作为一个Transformer固有地学习
视觉概念,增加抽象的组成,层次顺序,我们推测,
图像的功能,从最后一层可能无法完全捕获的视觉信
息较低的水平。因此,我们将从Swin Transformer的最
后(阶段4)和倒数第二(阶段3)层除非另有
指定,我们的模型使用这些49 98个图像标记,用于
多层次图像理解。学习的线性投影将每个图像标记映
射到d维,使得最终的图像表示是
10x
R
98d
。
文本表示:DistilBERT语言表示模型[52]用于编码伴
随文本的语义。DistilBERT自然会为输入单词生成m个
标记,即模型最后一层的隐藏状态。我们将这些标记
连接
起来
,形成最终的文本表示
形式
。
目标数据库。AACL包含三个关键组件:(1)用于视
觉语义表示学习的图像编码器,(2)用于自然语言表
示学习的文本编码器,以及(3)根据文本表示修改源
图像表示的附加注意力合成模块。与使用多个阶段的
特征合成和匹配的其他方法(例如,[14]),AACL在
一个阶段中使用最终的
3.2.
加法注意力合成模块
为了联合表示查询的图像和文本成分,我们寻求转
换以语言语义为条件的视觉特征。为了实现这一点,
我们提出了一个添加剂的注意力组合模块的特征融
合。该模块由多个合成块组成,每个合成块采用附加
自注意力来学习上下文向量,然后上下文向量选择性
地修改
剩余10页未读,继续阅读
相关推荐

326 浏览量


cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- C#实现程序A的监控启动机制
- Delphi与C#交互加密解密技术实现与源码分析
- 高效财务发票管理软件
- VC6.0编程实现删除磁盘空白文件夹工具
- w5x00-master.zip压缩包解析:W5200/W5500系列Linux驱动程序
- 数字通信经典教材第五版及其答案分享
- Extjs多表头设计与实现技巧
- VBA压缩包子技术未来展望
- 精选多类型导航菜单,总有您钟爱的一款
- 局域网聊天新途径:Android平台UDP技术实现
- 深入浅出神经网络模式识别与实践教程
- Junit测试实例分享:纯Java与SSH框架案例
- jquery xslider插件实现图片的流畅自动及按钮控制滚动
- MVC架构下的图书馆管理系统开发指南
- 里昂理工学院RecruteSup项目:第5年实践与Java技术整合
- iOS 13.2真机调试包使用指南及安装
